 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCPPO: Contrastive Perception for Vision Language Policy Optimization
Jan 01, 2026We introduce CPPO, a Contrastive Perception Policy Optimization method for finetuning vision-language models (VLMs). While reinforcement learning (RL) has advanced reasoning in language models, extending it to multimodal reasoning requires improving both the perception and reasoning aspects. Prior works tackle this challenge mainly with explicit perception rewards, but disentangling perception tokens from reasoning tokens is difficult, requiring extra LLMs, ground-truth data, forced separation of perception from reasoning by policy model, or applying rewards indiscriminately to all output tokens. CPPO addresses this problem by detecting perception tokens via entropy shifts in the model outputs under perturbed input images. CPPO then extends the RL objective function with a Contrastive Perception Loss (CPL) that enforces consistency under information-preserving perturbations and sensitivity under information-removing ones. Experiments show that CPPO surpasses previous perception-rewarding methods, while avoiding extra models, making training more efficient and scalable.
ETP-R1: Evolving Topological Planning with Reinforcement Fine-tuning for Vision-Language Navigation in Continuous Environments
Dec 24, 2025Vision-Language Navigation in Continuous Environments (VLN-CE) requires an embodied agent to navigate towards target in continuous environments, following natural language instructions. While current graph-based methods offer an efficient, structured approach by abstracting the environment into a topological map and simplifying the action space to waypoint selection, they lag behind methods based on Large Vision-Language Models (LVLMs) in leveraging large-scale data and advanced training paradigms. In this paper, we try to bridge this gap by introducing ETP-R1, a framework that applies the paradigm of scaling up data and Reinforcement Fine-Tuning (RFT) to a graph-based VLN-CE model. To build a strong foundation, we first construct a high-quality, large-scale pretraining dataset using the Gemini API. This dataset consists of diverse, low-hallucination instructions for topological trajectories, providing rich supervision for our graph-based policy to map language to topological paths. This foundation is further strengthened by unifying data from both R2R and RxR tasks for joint pretraining. Building on this, we introduce a three-stage training paradigm, which culminates in the first application of closed-loop, online RFT to a graph-based VLN-CE model, powered by the Group Relative Policy Optimization (GRPO) algorithm. Extensive experiments demonstrate that our approach is highly effective, establishing new state-of-the-art performance across all major metrics on both the R2R-CE and RxR-CE benchmarks. Our code is available at https://github.com/Cepillar/ETP-R1.
Dynamic Mixture of Progressive Parameter-Efficient Expert Library for Lifelong Robot Learning
Jun 06, 2025A generalist agent must continuously learn and adapt throughout its lifetime, achieving efficient forward transfer while minimizing catastrophic forgetting. Previous work within the dominant pretrain-then-finetune paradigm has explored parameter-efficient fine-tuning for single-task adaptation, effectively steering a frozen pretrained model with a small number of parameters. However, in the context of lifelong learning, these methods rely on the impractical assumption of a test-time task identifier and restrict knowledge sharing among isolated adapters. To address these limitations, we propose Dynamic Mixture of Progressive Parameter-Efficient Expert Library (DMPEL) for lifelong robot learning. DMPEL progressively learn a low-rank expert library and employs a lightweight router to dynamically combine experts into an end-to-end policy, facilitating flexible behavior during lifelong adaptation. Moreover, by leveraging the modular structure of the fine-tuned parameters, we introduce coefficient replay to guide the router in accurately retrieving frozen experts for previously encountered tasks, thereby mitigating catastrophic forgetting. This method is significantly more storage- and computationally-efficient than applying demonstration replay to the entire policy. Extensive experiments on the lifelong manipulation benchmark LIBERO demonstrate that our framework outperforms state-of-the-art lifelong learning methods in success rates across continual adaptation, while utilizing minimal trainable parameters and storage.
OccluGaussian: Occlusion-Aware Gaussian Splatting for Large Scene Reconstruction and Rendering
Mar 20, 2025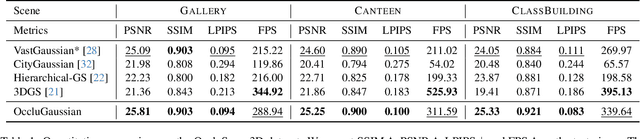
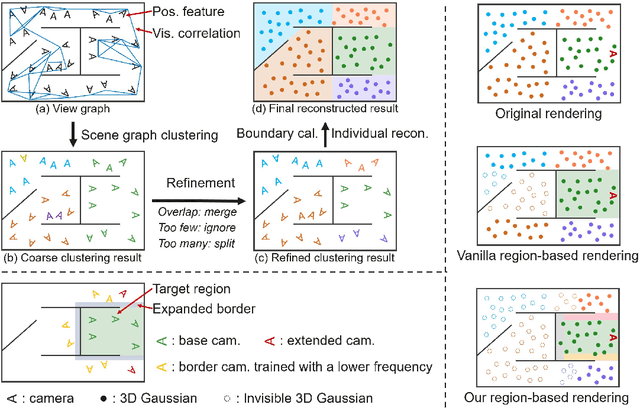
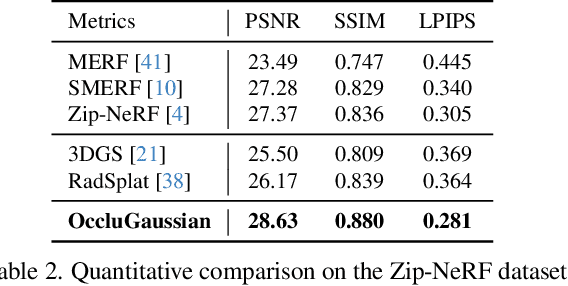
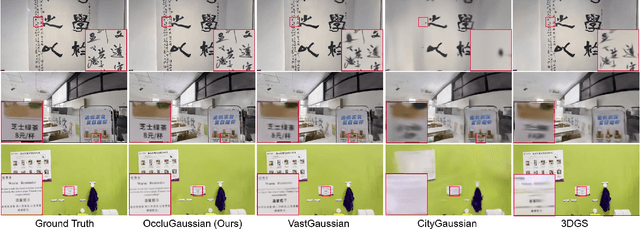
In large-scale scene reconstruction using 3D Gaussian splatting, it is common to partition the scene into multiple smaller regions and reconstruct them individually. However, existing division methods are occlusion-agnostic, meaning that each region may contain areas with severe occlusions. As a result, the cameras within those regions are less correlated, leading to a low average contribution to the overall reconstruction. In this paper, we propose an occlusion-aware scene division strategy that clusters training cameras based on their positions and co-visibilities to acquire multiple regions. Cameras in such regions exhibit stronger correlations and a higher average contribution, facilitating high-quality scene reconstruction. We further propose a region-based rendering technique to accelerate large scene rendering, which culls Gaussians invisible to the region where the viewpoint is located. Such a technique significantly speeds up the rendering without compromising quality. Extensive experiments on multiple large scenes show that our method achieves superior reconstruction results with faster rendering speed compared to existing state-of-the-art approaches. Project page: https://occlugaussian.github.io.
Scale Disparity of Instances in Interactive Point Cloud Segmentation
Jul 19, 2024



Interactive point cloud segmentation has become a pivotal task for understanding 3D scenes, enabling users to guide segmentation models with simple interactions such as clicks, therefore significantly reducing the effort required to tailor models to diverse scenarios and new categories. However, in the realm of interactive segmentation, the meaning of instance diverges from that in instance segmentation, because users might desire to segment instances of both thing and stuff categories that vary greatly in scale. Existing methods have focused on thing categories, neglecting the segmentation of stuff categories and the difficulties arising from scale disparity. To bridge this gap, we propose ClickFormer, an innovative interactive point cloud segmentation model that accurately segments instances of both thing and stuff categories. We propose a query augmentation module to augment click queries by a global query sampling strategy, thus maintaining consistent performance across different instance scales. Additionally, we employ global attention in the query-voxel transformer to mitigate the risk of generating false positives, along with several other network structure improvements to further enhance the model's segmentation performance. Experiments demonstrate that ClickFormer outperforms existing interactive point cloud segmentation methods across both indoor and outdoor datasets, providing more accurate segmentation results with fewer user clicks in an open-world setting.
Preserving Full Degradation Details for Blind Image Super-Resolution
Jul 02, 2024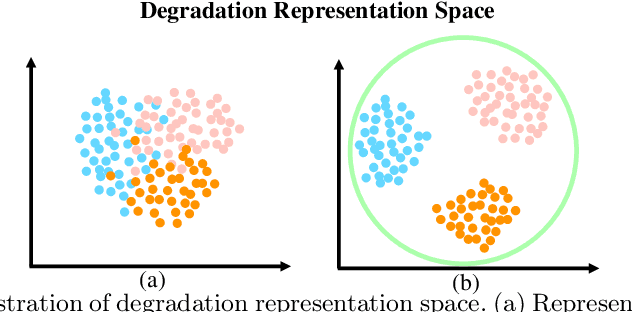
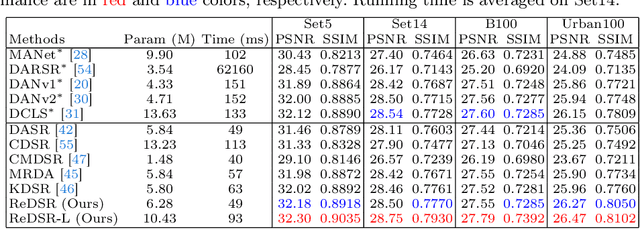
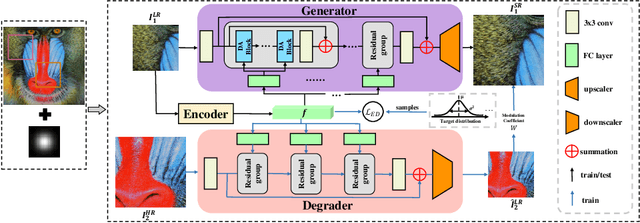
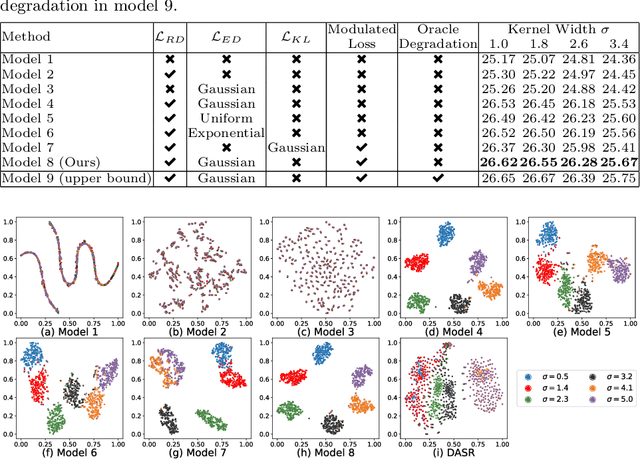
The performance of image super-resolution relies heavily on the accuracy of degradation information, especially under blind settings. Due to absence of true degradation models in real-world scenarios, previous methods learn distinct representations by distinguishing different degradations in a batch. However, the most significant degradation differences may provide shortcuts for the learning of representations such that subtle difference may be discarded. In this paper, we propose an alternative to learn degradation representations through reproducing degraded low-resolution (LR) images. By guiding the degrader to reconstruct input LR images, full degradation information can be encoded into the representations. In addition, we develop an energy distance loss to facilitate the learning of the degradation representations by introducing a bounded constraint. Experiments show that our representations can extract accurate and highly robust degradation information. Moreover, evaluations on both synthetic and real images demonstrate that our ReDSR achieves state-of-the-art performance for the blind SR tasks.
PanopticRecon: Leverage Open-vocabulary Instance Segmentation for Zero-shot Panoptic Reconstruction
Jul 01, 2024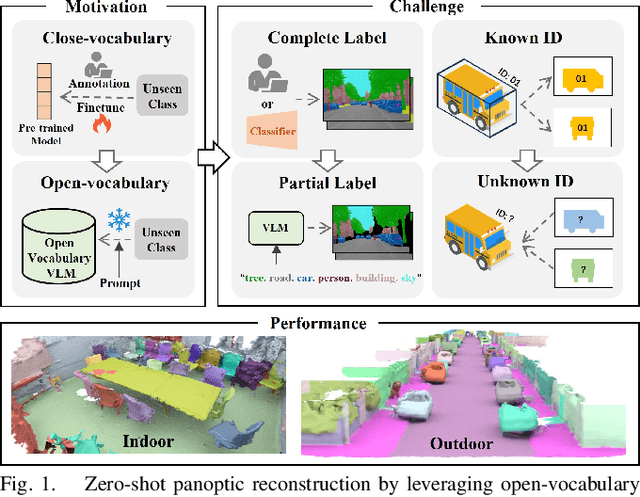
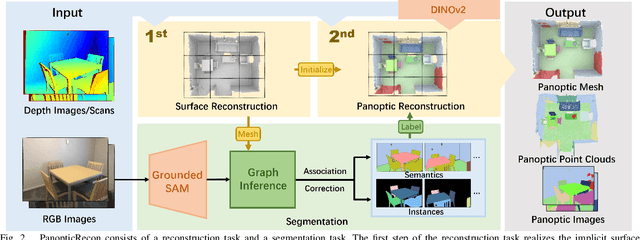
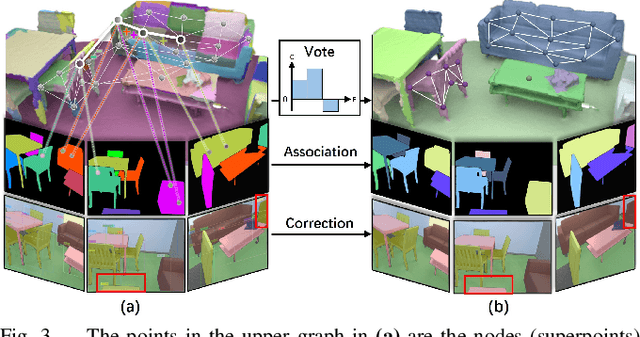
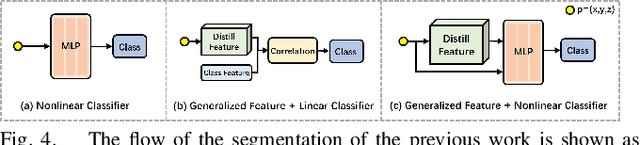
Panoptic reconstruction is a challenging task in 3D scene understanding. However, most existing methods heavily rely on pre-trained semantic segmentation models and known 3D object bounding boxes for 3D panoptic segmentation, which is not available for in-the-wild scenes. In this paper, we propose a novel zero-shot panoptic reconstruction method from RGB-D images of scenes. For zero-shot segmentation, we leverage open-vocabulary instance segmentation, but it has to face partial labeling and instance association challenges. We tackle both challenges by propagating partial labels with the aid of dense generalized features and building a 3D instance graph for associating 2D instance IDs. Specifically, we exploit partial labels to learn a classifier for generalized semantic features to provide complete labels for scenes with dense distilled features. Moreover, we formulate instance association as a 3D instance graph segmentation problem, allowing us to fully utilize the scene geometry prior and all 2D instance masks to infer global unique pseudo 3D instance ID. Our method outperforms state-of-the-art methods on the indoor dataset ScanNet V2 and the outdoor dataset KITTI-360, demonstrating the effectiveness of our graph segmentation method and reconstruction network.
SCALE: Self-Correcting Visual Navigation for Mobile Robots via Anti-Novelty Estimation
Apr 16, 2024Although visual navigation has been extensively studied using deep reinforcement learning, online learning for real-world robots remains a challenging task. Recent work directly learned from offline dataset to achieve broader generalization in the real-world tasks, which, however, faces the out-of-distribution (OOD) issue and potential robot localization failures in a given map for unseen observation. This significantly drops the success rates and even induces collision. In this paper, we present a self-correcting visual navigation method, SCALE, that can autonomously prevent the robot from the OOD situations without human intervention. Specifically, we develop an image-goal conditioned offline reinforcement learning method based on implicit Q-learning (IQL). When facing OOD observation, our novel localization recovery method generates the potential future trajectories by learning from the navigation affordance, and estimates the future novelty via random network distillation (RND). A tailored cost function searches for the candidates with the least novelty that can lead the robot to the familiar places. We collect offline data and conduct evaluation experiments in three real-world urban scenarios. Experiment results show that SCALE outperforms the previous state-of-the-art methods for open-world navigation with a unique capability of localization recovery, significantly reducing the need for human intervention. Code is available at https://github.com/KubeEdge4Robotics/ScaleNav.
NF-Atlas: Multi-Volume Neural Feature Fields for Large Scale LiDAR Mapping
Apr 10, 2023LiDAR Mapping has been a long-standing problem in robotics. Recent progress in neural implicit representation has brought new opportunities to robotic mapping. In this paper, we propose the multi-volume neural feature fields, called NF-Atlas, which bridge the neural feature volumes with pose graph optimization. By regarding the neural feature volume as pose graph nodes and the relative pose between volumes as pose graph edges, the entire neural feature field becomes both locally rigid and globally elastic. Locally, the neural feature volume employs a sparse feature Octree and a small MLP to encode the submap SDF with an option of semantics. Learning the map using this structure allows for end-to-end solving of maximum a posteriori (MAP) based probabilistic mapping. Globally, the map is built volume by volume independently, avoiding catastrophic forgetting when mapping incrementally. Furthermore, when a loop closure occurs, with the elastic pose graph based representation, only updating the origin of neural volumes is required without remapping. Finally, these functionalities of NF-Atlas are validated. Thanks to the sparsity and the optimization based formulation, NF-Atlas shows competitive performance in terms of accuracy, efficiency and memory usage on both simulation and real-world datasets.
Loop-Closure Detection Based on 3D Point Cloud Learning for Self-Driving Industry Vehicles
Apr 30, 2019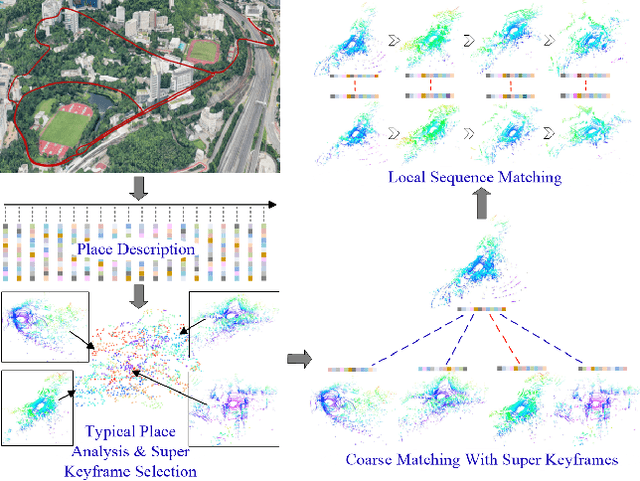
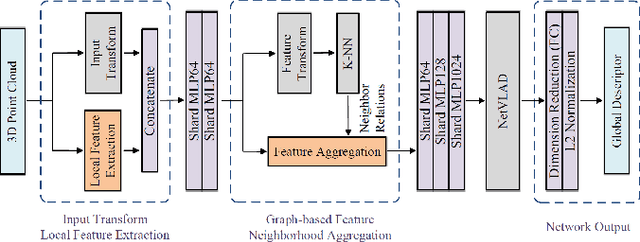

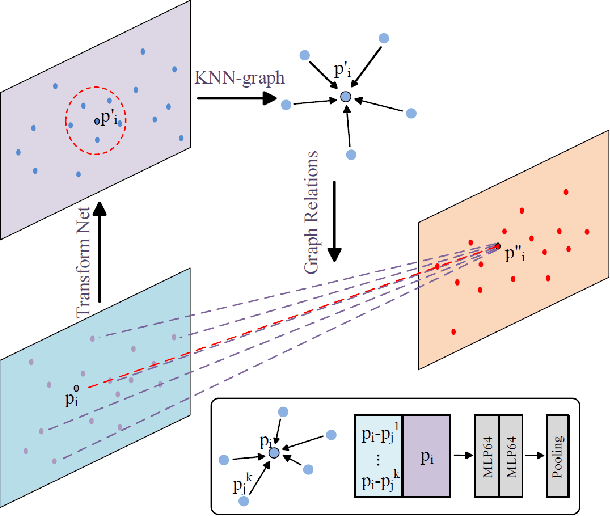
Self-driving industry vehicle plays a key role in the industry automation and contributes to resolve the problems of the shortage and increasing cost in manpower. Place recognition and loop-closure detection are main challenges in the localization and navigation tasks, specially when industry vehicles work in large-scale complex environments, such as the logistics warehouse and the port terminal. In this paper, we resolve the loop-closure detection problem by developing a novel 3D point cloud learning network, an active super keyframe selection method and a coarse-to-fine sequence matching strategy. More specifically, we first propose a novel deep neural network to extract a global descriptors from the original large-scale 3D point cloud, then based on which, an environment analysis approach is presented to investigate the feature space distribution of the global descriptors and actively select several super keyframes. Finally, a coarse-to-fine sequence matching strategy, which includes a super keyframe based coarse matching stage and a local sequence matching stage, is presented to ensure the loop-closure detection accuracy and real-time performance simultaneously. The proposed network is evaluated in different datasets and obtains a substantial improvement against the state-of-the-art PointNetVLAD in place recognition tasks. Experiment results on a self-driving industry vehicle validate the effectiveness of the proposed loop-closure detection algorithm.