 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Self-Consistency Learning for Seismic Irregular Spatial Sampling Reconstruction
Nov 01, 2024
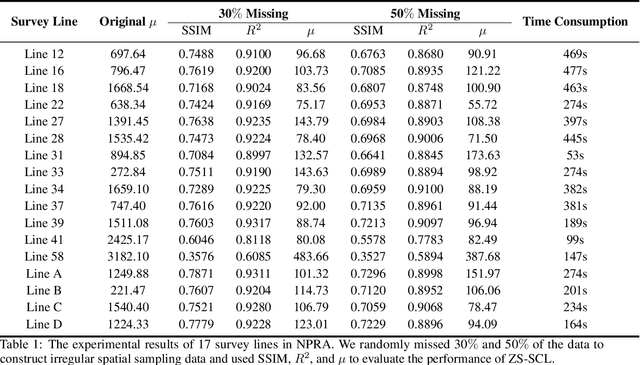


Seismic exploration is currently the most important method for understanding subsurface structures. However, due to surface conditions, seismic receivers may not be uniformly distributed along the measurement line, making the entire exploration work difficult to carry out. Previous deep learning methods for reconstructing seismic data often relied on additional datasets for training. While some existing methods do not require extra data, they lack constraints on the reconstruction data, leading to unstable reconstruction performance. In this paper, we proposed a zero-shot self-consistency learning strategy and employed an extremely lightweight network for seismic data reconstruction. Our method does not require additional datasets and utilizes the correlations among different parts of the data to design a self-consistency learning loss function, driving a network with only 90,609 learnable parameters. We applied this method to experiments on the USGS National Petroleum Reserve-Alaska public dataset and the results indicate that our proposed approach achieved good reconstruction results. Additionally, our method also demonstrates a certain degree of noise suppression, which is highly beneficial for large and complex seismic exploration tasks.
Scale-aware Insertion of Virtual Objects in Monocular Videos
Dec 04, 2020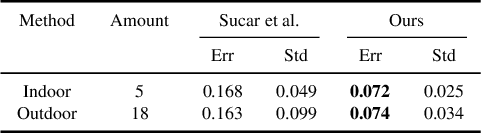

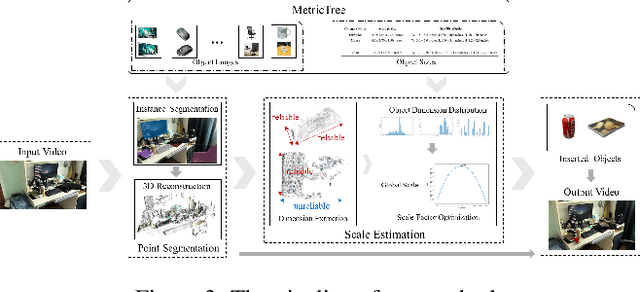
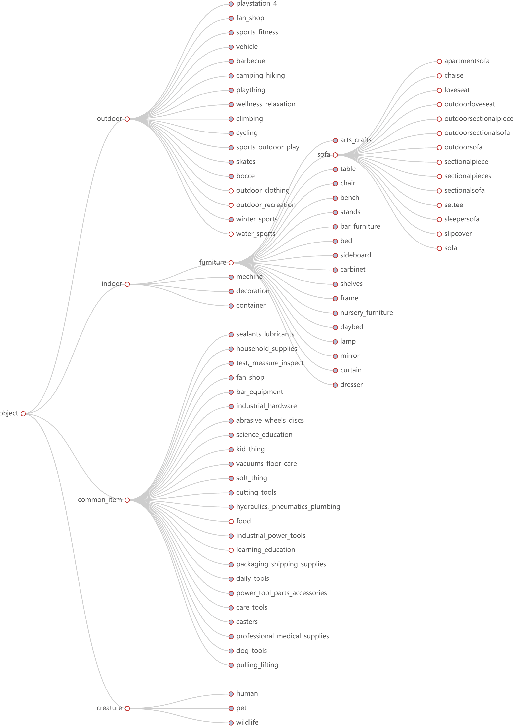
In this paper, we propose a scale-aware method for inserting virtual objects with proper sizes into monocular videos. To tackle the scale ambiguity problem of geometry recovery from monocular videos, we estimate the global scale objects in a video with a Bayesian approach incorporating the size priors of objects, where the scene objects sizes should strictly conform to the same global scale and the possibilities of global scales are maximized according to the size distribution of object categories. To do so, we propose a dataset of sizes of object categories: Metric-Tree, a hierarchical representation of sizes of more than 900 object categories with the corresponding images. To handle the incompleteness of objects recovered from videos, we propose a novel scale estimation method that extracts plausible dimensions of objects for scale optimization. Experiments have shown that our method for scale estimation performs better than the state-of-the-art methods, and has considerable validity and robustness for different video scenes. Metric-Tree has been made available at: https://metric-tree.github.io
3D Point Cloud Learning for Large-scale Environment Analysis and Place Recognition
Dec 11, 2018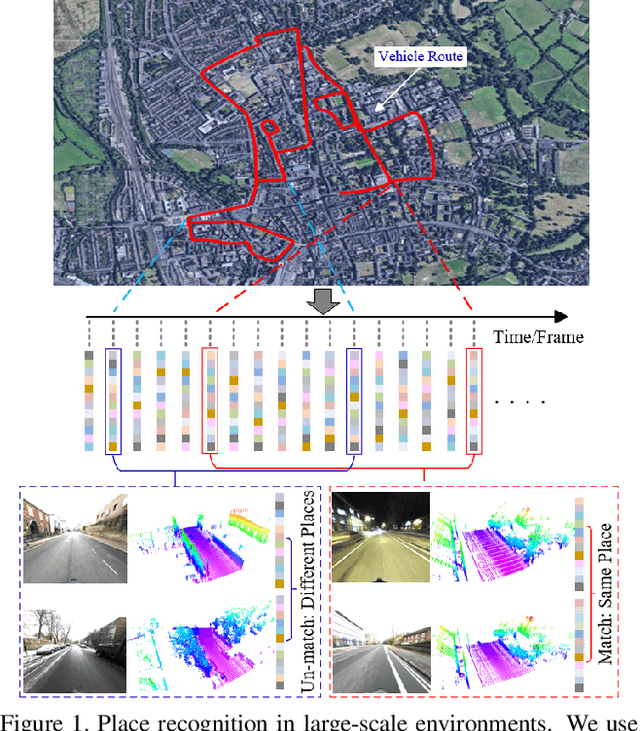
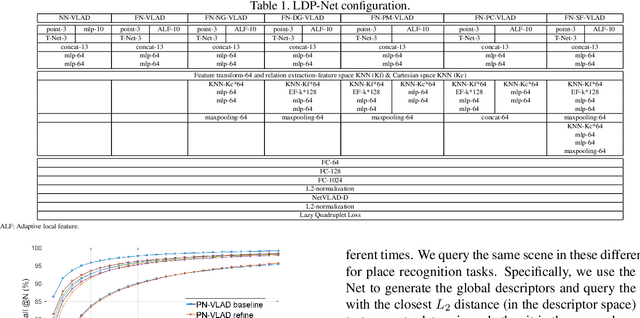
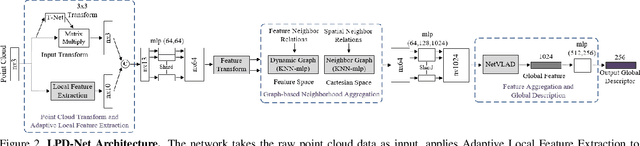
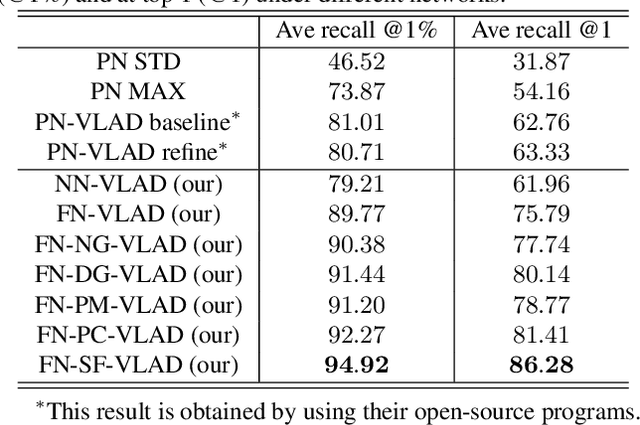
In this paper, we develop a new deep neural network which can extract discriminative and generalizable global descriptors from the raw 3D point cloud. Specifically, two novel modules, Adaptive Local Feature Extraction and Graph-based Neighborhood Aggregation, are designed and integrated into our network. This contributes to extract the local features adequately, reveal the spatial distribution of the point cloud, and find out the local structure and neighborhood relations of each part in a large-scale point cloud with an end-to-end manner. Furthermore, we utilize the network output for point cloud based analysis and retrieval tasks to achieve large-scale place recognition and environmental analysis. We tested our approach on the Oxford RobotCar dataset. The results for place recognition increased the existing state-of-the-art result (PointNetVLAD) from 81.01% to 94.92%. Moreover, we present an application to analyze the large-scale environment by evaluating the uniqueness of each location in the map, which can be applied to localization and loop-closure tasks, which are crucial for robotics and self-driving applications.