 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePropeller-Assisted Robust 3D Hopping Robot with Hierarchical Force Allocation
Jun 06, 2026Monopedal hopping robots are conceptually simple but highly dynamic and inherently unstable. Achieving robust 3D hopping is still difficult because ground reaction forces are available only during the short stance phase, while the robot is underactuated in flight. A key unresolved issue is how to improve flight-phase control authority. Propeller assistance provides a promising solution, but it requires careful coordination of leg-generated contact forces and propeller thrusts across stance and flight. This paper presents Pro-OMEGA2, a propeller-assisted 3D monopedal hopping robot with an active 3-RSR parallel leg and a trunk-mounted tri-rotor for auxiliary attitude regulation. To address the force coordination challenge, we propose a Hierarchical Force Allocation (HFA) framework based on a single rigid body (SRB) model. The leg generates the main stance contact wrench, while the tri-rotor provides auxiliary attitude regulation, compensating the residual attitude moment in stance and maintaining attitude during flight. Real-robot experiments in indoor and outdoor scenarios demonstrate sustained 3D hopping, including terrain transitions and impulsive push recovery, validating robustness under unmodeled contact and external disturbances.
Global Truncated Loss Minimization for Robust and Threshold-Resilient Geometric Estimation
Mar 16, 2026To achieve outlier-robust geometric estimation, robust objective functions are generally employed to mitigate the influence of outliers. The widely used consensus maximization(CM) is highly robust when paired with global branch-and-bound(BnB) search. However, CM relies solely on inlier counts and is sensitive to the inlier threshold. Besides, the discrete nature of CM leads to loose bounds, necessitating extensive BnB iterations and computation cost. Truncated losses(TL), another continuous alternative, leverage residual information more effectively and could potentially overcome these issues. But to our knowledge, no prior work has systematically explored globally minimizing TL with BnB and its potential for enhanced threshold resilience or search efficiency. In this work, we propose GTM, the first unified BnB-based framework for globally-optimal TL loss minimization across diverse geometric problems. GTM involves a hybrid solving design: given an n-dimensional problem, it performs BnB search over an (n-1)-dimensional subspace while the remaining 1D variable is solved by bounding the objective function. Our hybrid design not only reduces the search space, but also enables us to derive Lipschitz-continuous bounding functions that are general, tight, and can be efficiently solved by a classic global Lipschitz solver named DIRECT, which brings further acceleration. We conduct a systematic evaluation on various BnB-based methods for CM and TL on the robust linear regression problem, showing that GTM enjoys remarkable threshold resilience and the highest efficiency compared to baseline methods. Furthermore, we apply GTM on different geometric estimation problems with diverse residual forms. Extensive experiments demonstrate that GTM achieves state-of-the-art outlier-robustness and threshold-resilience while maintaining high efficiency across these estimation tasks.
A Unified Calibration Framework for Coordinate and Kinematic Parameters in Dual-Arm Robots
Mar 16, 2026Precise collaboration in vision-based dual-arm robot systems requires accurate system calibration. Recent dual-robot calibration methods have achieved strong performance by simultaneously solving multiple coordinate transformations. However, these methods either treat kinematic errors as implicit noise or handle them through separated error modeling, resulting in non-negligible accumulated errors. In this paper, we present a novel framework for unified calibration of the coordinate transformations and kinematic parameters in both robot arms. Our key idea is to unify all the tightly coupled parameters within a single Lie-algebraic formulation. To this end, we construct a consolidated error model grounded in the product-of-exponentials formula, which naturally integrates the coordinate and kinematic parameters in twist forms. Our model introduces no artificial error separation and thus greatly mitigates the error propagation. In addition, we derive a closed-form analytical Jacobian from this model using Lie derivatives. By exploring the Jacobian rank property, we analyze the identifiability of all calibration parameters and show that our joint optimization is well-posed under mild conditions. This enables off-the-shelf iterative solvers to stably optimize these parameters on the manifold space. Besides, to ensure robust convergence of our joint optimization, we develop a certifiably correct algorithm for initializing the unknown coordinates. Relying on semidefinite relaxation, our algorithm can yield a reliable estimate whose near-global optimality can be verified a posteriori. Extensive experiments validate the superior accuracy of our approach over previous baselines under identical visual measurements. Meanwhile, our certifiable initialization consistently outperforms several coordinate-only baselines, proving its reliability as a starting point for joint optimization.
Jumping Control for a Quadrupedal Wheeled-Legged Robot via NMPC and DE Optimization
Feb 25, 2026Quadrupedal wheeled-legged robots combine the advantages of legged and wheeled locomotion to achieve superior mobility, but executing dynamic jumps remains a significant challenge due to the additional degrees of freedom introduced by wheeled legs. This paper develops a mini-sized wheeled-legged robot for agile motion and presents a novel motion control framework that integrates the Nonlinear Model Predictive Control (NMPC) for locomotion and the Differential Evolution (DE) based trajectory optimization for jumping in quadrupedal wheeled-legged robots. The proposed controller utilizes wheel motion and locomotion to enhance jumping performance, achieving versatile maneuvers such as vertical jumping, forward jumping, and backflips. Extensive simulations and real-world experiments validate the effectiveness of the framework, demonstrating a forward jump over a 0.12 m obstacle and a vertical jump reaching 0.5 m.
SpaceVista: All-Scale Visual Spatial Reasoning from mm to km
Oct 10, 2025With the current surge in spatial reasoning explorations, researchers have made significant progress in understanding indoor scenes, but still struggle with diverse applications such as robotics and autonomous driving. This paper aims to advance all-scale spatial reasoning across diverse scenarios by tackling two key challenges: 1) the heavy reliance on indoor 3D scans and labor-intensive manual annotations for dataset curation; 2) the absence of effective all-scale scene modeling, which often leads to overfitting to individual scenes. In this paper, we introduce a holistic solution that integrates a structured spatial reasoning knowledge system, scale-aware modeling, and a progressive training paradigm, as the first attempt to broaden the all-scale spatial intelligence of MLLMs to the best of our knowledge. Using a task-specific, specialist-driven automated pipeline, we curate over 38K video scenes across 5 spatial scales to create SpaceVista-1M, a dataset comprising approximately 1M spatial QA pairs spanning 19 diverse task types. While specialist models can inject useful domain knowledge, they are not reliable for evaluation. We then build an all-scale benchmark with precise annotations by manually recording, retrieving, and assembling video-based data. However, naive training with SpaceVista-1M often yields suboptimal results due to the potential knowledge conflict. Accordingly, we introduce SpaceVista-7B, a spatial reasoning model that accepts dense inputs beyond semantics and uses scale as an anchor for scale-aware experts and progressive rewards. Finally, extensive evaluations across 5 benchmarks, including our SpaceVista-Bench, demonstrate competitive performance, showcasing strong generalization across all scales and scenarios. Our dataset, model, and benchmark will be released on https://peiwensun2000.github.io/mm2km .
Shared Object Manipulation with a Team of Collaborative Quadrupeds
Oct 01, 2025
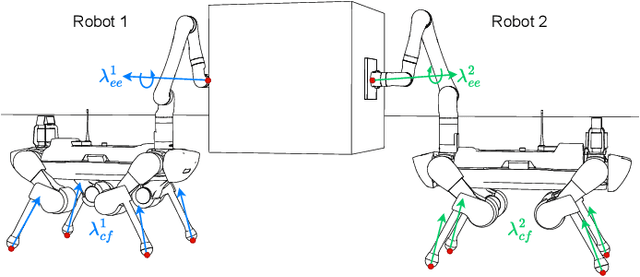
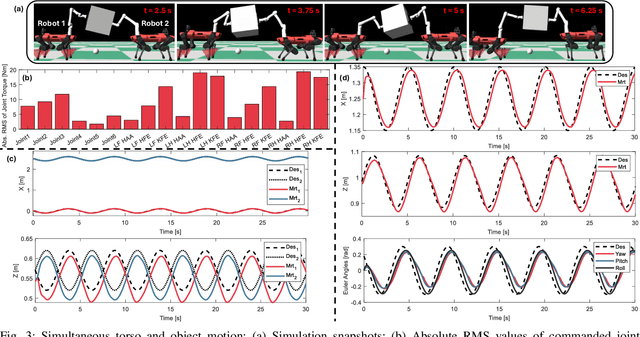
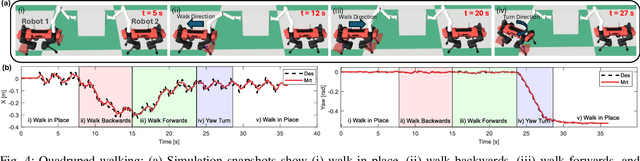
Utilizing teams of multiple robots is advantageous for handling bulky objects. Many related works focus on multi-manipulator systems, which are limited by workspace constraints. In this paper, we extend a classical hybrid motion-force controller to a team of legged manipulator systems, enabling collaborative loco-manipulation of rigid objects with a force-closed grasp. Our novel approach allows the robots to flexibly coordinate their movements, achieving efficient and stable object co-manipulation and transport, validated through extensive simulations and real-world experiments.
OmniDepth: Bridging Monocular and Stereo Reasoning with Latent Alignment
Aug 06, 2025Monocular and stereo depth estimation offer complementary strengths: monocular methods capture rich contextual priors but lack geometric precision, while stereo approaches leverage epipolar geometry yet struggle with ambiguities such as reflective or textureless surfaces. Despite post-hoc synergies, these paradigms remain largely disjoint in practice. We introduce OmniDepth, a unified framework that bridges both through iterative bidirectional alignment of their latent representations. At its core, a novel cross-attentive alignment mechanism dynamically synchronizes monocular contextual cues with stereo hypothesis representations during stereo reasoning. This mutual alignment resolves stereo ambiguities (e.g., specular surfaces) by injecting monocular structure priors while refining monocular depth with stereo geometry within a single network. Extensive experiments demonstrate state-of-the-art results: \textbf{OmniDepth reduces zero-shot generalization error by $\!>\!40\%$ on Middlebury and ETH3D}, while addressing longstanding failures on transparent and reflective surfaces. By harmonizing multi-view geometry with monocular context, OmniDepth enables robust 3D perception that transcends modality-specific limitations. Codes available at https://github.com/aeolusguan/OmniDepth.
Whole-Body Control Framework for Humanoid Robots with Heavy Limbs: A Model-Based Approach
Jun 17, 2025Humanoid robots often face significant balance issues due to the motion of their heavy limbs. These challenges are particularly pronounced when attempting dynamic motion or operating in environments with irregular terrain. To address this challenge, this manuscript proposes a whole-body control framework for humanoid robots with heavy limbs, using a model-based approach that combines a kino-dynamics planner and a hierarchical optimization problem. The kino-dynamics planner is designed as a model predictive control (MPC) scheme to account for the impact of heavy limbs on mass and inertia distribution. By simplifying the robot's system dynamics and constraints, the planner enables real-time planning of motion and contact forces. The hierarchical optimization problem is formulated using Hierarchical Quadratic Programming (HQP) to minimize limb control errors and ensure compliance with the policy generated by the kino-dynamics planner. Experimental validation of the proposed framework demonstrates its effectiveness. The humanoid robot with heavy limbs controlled by the proposed framework can achieve dynamic walking speeds of up to 1.2~m/s, respond to external disturbances of up to 60~N, and maintain balance on challenging terrains such as uneven surfaces, and outdoor environments.
Incentivizing Multimodal Reasoning in Large Models for Direct Robot Manipulation
May 19, 2025Recent Large Multimodal Models have demonstrated remarkable reasoning capabilities, especially in solving complex mathematical problems and realizing accurate spatial perception. Our key insight is that these emerging abilities can naturally extend to robotic manipulation by enabling LMMs to directly infer the next goal in language via reasoning, rather than relying on a separate action head. However, this paradigm meets two main challenges: i) How to make LMMs understand the spatial action space, and ii) How to fully exploit the reasoning capacity of LMMs in solving these tasks. To tackle the former challenge, we propose a novel task formulation, which inputs the current states of object parts and the gripper, and reformulates rotation by a new axis representation instead of traditional Euler angles. This representation is more compatible with spatial reasoning and easier to interpret within a unified language space. For the latter challenge, we design a pipeline to utilize cutting-edge LMMs to generate a small but high-quality reasoning dataset of multi-round dialogues that successfully solve manipulation tasks for supervised fine-tuning. Then, we perform reinforcement learning by trial-and-error interactions in simulation to further enhance the model's reasoning abilities for robotic manipulation. Our resulting reasoning model built upon a 7B backbone, named ReasonManip, demonstrates three notable advantages driven by its system-2 level reasoning capabilities: i) exceptional generalizability to out-of-distribution environments, objects, and tasks; ii) inherent sim-to-real transfer ability enabled by the unified language representation shared across domains; iii) transparent interpretability connecting high-level reasoning and low-level control. Extensive experiments demonstrate the effectiveness of the proposed paradigm and its potential to advance LMM-driven robotic manipulation.
OPA-Pack: Object-Property-Aware Robotic Bin Packing
May 19, 2025Robotic bin packing aids in a wide range of real-world scenarios such as e-commerce and warehouses. Yet, existing works focus mainly on considering the shape of objects to optimize packing compactness and neglect object properties such as fragility, edibility, and chemistry that humans typically consider when packing objects. This paper presents OPA-Pack (Object-Property-Aware Packing framework), the first framework that equips the robot with object property considerations in planning the object packing. Technical-wise, we develop a novel object property recognition scheme with retrieval-augmented generation and chain-of-thought reasoning, and build a dataset with object property annotations for 1,032 everyday objects. Also, we formulate OPA-Net, aiming to jointly separate incompatible object pairs and reduce pressure on fragile objects, while compacting the packing. Further, OPA-Net consists of a property embedding layer to encode the property of candidate objects to be packed, together with a fragility heightmap and an avoidance heightmap to keep track of the packed objects. Then, we design a reward function and adopt a deep Q-learning scheme to train OPA-Net. Experimental results manifest that OPA-Pack greatly improves the accuracy of separating incompatible object pairs (from 52% to 95%) and largely reduces pressure on fragile objects (by 29.4%), while maintaining good packing compactness. Besides, we demonstrate the effectiveness of OPA-Pack on a real packing platform, showcasing its practicality in real-world scenarios.