 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZDySS -- Zero-Shot Dynamic Scene Stylization using Gaussian Splatting
Jan 07, 2025



Stylizing a dynamic scene based on an exemplar image is critical for various real-world applications, including gaming, filmmaking, and augmented and virtual reality. However, achieving consistent stylization across both spatial and temporal dimensions remains a significant challenge. Most existing methods are designed for static scenes and often require an optimization process for each style image, limiting their adaptability. We introduce ZDySS, a zero-shot stylization framework for dynamic scenes, allowing our model to generalize to previously unseen style images at inference. Our approach employs Gaussian splatting for scene representation, linking each Gaussian to a learned feature vector that renders a feature map for any given view and timestamp. By applying style transfer on the learned feature vectors instead of the rendered feature map, we enhance spatio-temporal consistency across frames. Our method demonstrates superior performance and coherence over state-of-the-art baselines in tests on real-world dynamic scenes, making it a robust solution for practical applications.
SADG: Segment Any Dynamic Gaussian Without Object Trackers
Nov 28, 2024Understanding dynamic 3D scenes is fundamental for various applications, including extended reality (XR) and autonomous driving. Effectively integrating semantic information into 3D reconstruction enables holistic representation that opens opportunities for immersive and interactive applications. We introduce SADG, Segment Any Dynamic Gaussian Without Object Trackers, a novel approach that combines dynamic Gaussian Splatting representation and semantic information without reliance on object IDs. In contrast to existing works, we do not rely on supervision based on object identities to enable consistent segmentation of dynamic 3D objects. To this end, we propose to learn semantically-aware features by leveraging masks generated from the Segment Anything Model (SAM) and utilizing our novel contrastive learning objective based on hard pixel mining. The learned Gaussian features can be effectively clustered without further post-processing. This enables fast computation for further object-level editing, such as object removal, composition, and style transfer by manipulating the Gaussians in the scene. We further extend several dynamic novel-view datasets with segmentation benchmarks to enable testing of learned feature fields from unseen viewpoints. We evaluate SADG on proposed benchmarks and demonstrate the superior performance of our approach in segmenting objects within dynamic scenes along with its effectiveness for further downstream editing tasks.
Physically-Based Photometric Bundle Adjustment in Non-Lambertian Environments
Sep 18, 2024
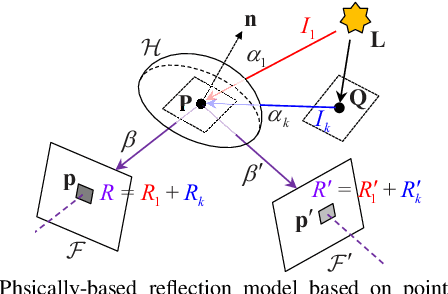
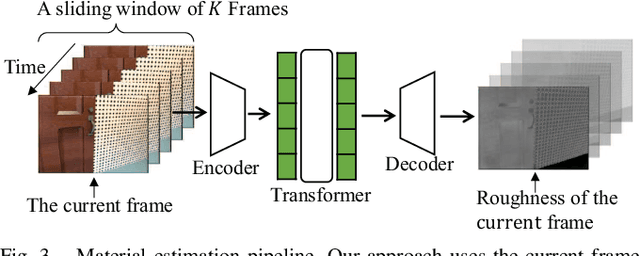
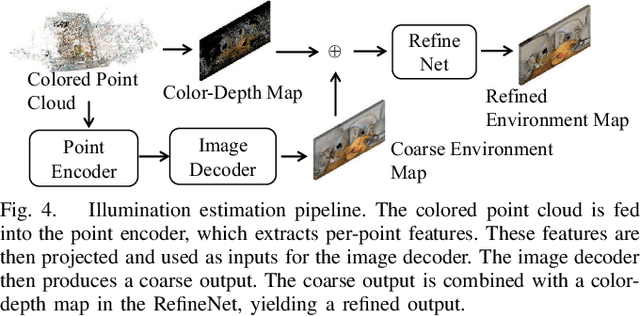
Photometric bundle adjustment (PBA) is widely used in estimating the camera pose and 3D geometry by assuming a Lambertian world. However, the assumption of photometric consistency is often violated since the non-diffuse reflection is common in real-world environments. The photometric inconsistency significantly affects the reliability of existing PBA methods. To solve this problem, we propose a novel physically-based PBA method. Specifically, we introduce the physically-based weights regarding material, illumination, and light path. These weights distinguish the pixel pairs with different levels of photometric inconsistency. We also design corresponding models for material estimation based on sequential images and illumination estimation based on point clouds. In addition, we establish the first SLAM-related dataset of non-Lambertian scenes with complete ground truth of illumination and material. Extensive experiments demonstrated that our PBA method outperforms existing approaches in accuracy.
VXP: Voxel-Cross-Pixel Large-scale Image-LiDAR Place Recognition
Mar 21, 2024Recent works on the global place recognition treat the task as a retrieval problem, where an off-the-shelf global descriptor is commonly designed in image-based and LiDAR-based modalities. However, it is non-trivial to perform accurate image-LiDAR global place recognition since extracting consistent and robust global descriptors from different domains (2D images and 3D point clouds) is challenging. To address this issue, we propose a novel Voxel-Cross-Pixel (VXP) approach, which establishes voxel and pixel correspondences in a self-supervised manner and brings them into a shared feature space. Specifically, VXP is trained in a two-stage manner that first explicitly exploits local feature correspondences and enforces similarity of global descriptors. Extensive experiments on the three benchmarks (Oxford RobotCar, ViViD++ and KITTI) demonstrate our method surpasses the state-of-the-art cross-modal retrieval by a large margin.
Gaussian Splatting in Style
Mar 13, 2024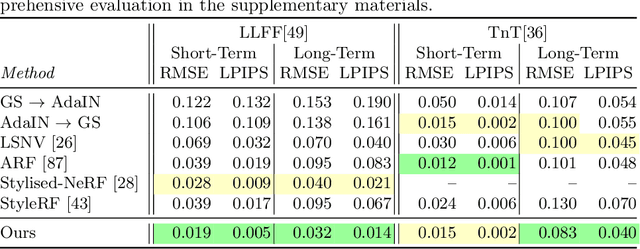


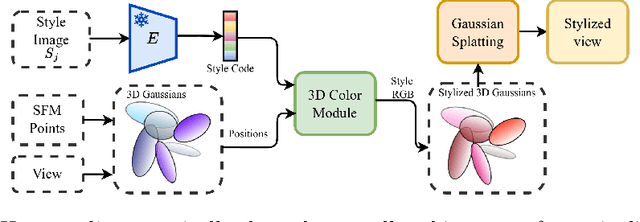
Scene stylization extends the work of neural style transfer to three spatial dimensions. A vital challenge in this problem is to maintain the uniformity of the stylized appearance across a multi-view setting. A vast majority of the previous works achieve this by optimizing the scene with a specific style image. In contrast, we propose a novel architecture trained on a collection of style images, that at test time produces high quality stylized novel views. Our work builds up on the framework of 3D Gaussian splatting. For a given scene, we take the pretrained Gaussians and process them using a multi resolution hash grid and a tiny MLP to obtain the conditional stylised views. The explicit nature of 3D Gaussians give us inherent advantages over NeRF-based methods including geometric consistency, along with having a fast training and rendering regime. This enables our method to be useful for vast practical use cases such as in augmented or virtual reality applications. Through our experiments, we show our methods achieve state-of-the-art performance with superior visual quality on various indoor and outdoor real-world data.
Robust Autonomous Vehicle Pursuit without Expert Steering Labels
Aug 16, 2023In this work, we present a learning method for lateral and longitudinal motion control of an ego-vehicle for vehicle pursuit. The car being controlled does not have a pre-defined route, rather it reactively adapts to follow a target vehicle while maintaining a safety distance. To train our model, we do not rely on steering labels recorded from an expert driver but effectively leverage a classical controller as an offline label generation tool. In addition, we account for the errors in the predicted control values, which can lead to a loss of tracking and catastrophic crashes of the controlled vehicle. To this end, we propose an effective data augmentation approach, which allows to train a network capable of handling different views of the target vehicle. During the pursuit, the target vehicle is firstly localized using a Convolutional Neural Network. The network takes a single RGB image along with cars' velocities and estimates the target vehicle's pose with respect to the ego-vehicle. This information is then fed to a Multi-Layer Perceptron, which regresses the control commands for the ego-vehicle, namely throttle and steering angle. We extensively validate our approach using the CARLA simulator on a wide range of terrains. Our method demonstrates real-time performance and robustness to different scenarios including unseen trajectories and high route completion. The project page containing code and multimedia can be publicly accessed here: https://changyaozhou.github.io/Autonomous-Vehicle-Pursuit/.
PVT3D: Point Voxel Transformers for Place Recognition from Sparse Lidar Scans
Nov 22, 2022Place recognition based on point cloud (LiDAR) scans is an important module for achieving robust autonomy in robots or self-driving vehicles. Training deep networks to match such scans presents a difficult trade-off: a higher spatial resolution of the network's intermediate representations is needed to perform fine-grained matching of subtle geometric features, but growing it too large makes the memory requirements infeasible. In this work, we propose a Point-Voxel Transformer network (PVT3D) that achieves robust fine-grained matching with low memory requirements. It leverages a sparse voxel branch to extract and aggregate information at a lower resolution and a point-wise branch to obtain fine-grained local information. A novel hierarchical cross-attention transformer (HCAT) uses queries from one branch to try to match structures in the other branch, ensuring that both extract self-contained descriptors of the point cloud (rather than one branch dominating), but using both to inform the output global descriptor of the point cloud. Extensive experiments show that the proposed PVT3D method surpasses the state-of-the-art by a large amount on several datasets (Oxford RobotCar, TUM, USyd). For instance, we achieve AR@1 of 85.6% on the TUM dataset, which surpasses the strongest prior model by ~15%.
DirectTracker: 3D Multi-Object Tracking Using Direct Image Alignment and Photometric Bundle Adjustment
Sep 29, 2022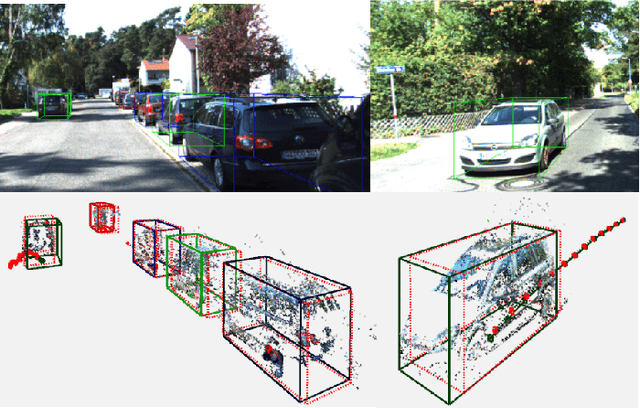
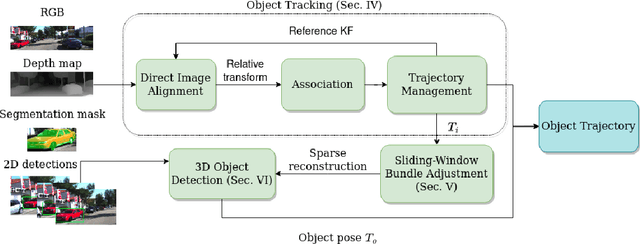


Direct methods have shown excellent performance in the applications of visual odometry and SLAM. In this work we propose to leverage their effectiveness for the task of 3D multi-object tracking. To this end, we propose DirectTracker, a framework that effectively combines direct image alignment for the short-term tracking and sliding-window photometric bundle adjustment for 3D object detection. Object proposals are estimated based on the sparse sliding-window pointcloud and further refined using an optimization-based cost function that carefully combines 3D and 2D cues to ensure consistency in image and world space. We propose to evaluate 3D tracking using the recently introduced higher-order tracking accuracy (HOTA) metric and the generalized intersection over union similarity measure to mitigate the limitations of the conventional use of intersection over union for the evaluation of vision-based trackers. We perform evaluation on the KITTI Tracking benchmark for the Car class and show competitive performance in tracking objects both in 2D and 3D.
Tight Integration of Feature-Based Relocalization in Monocular Direct Visual Odometry
Feb 08, 2021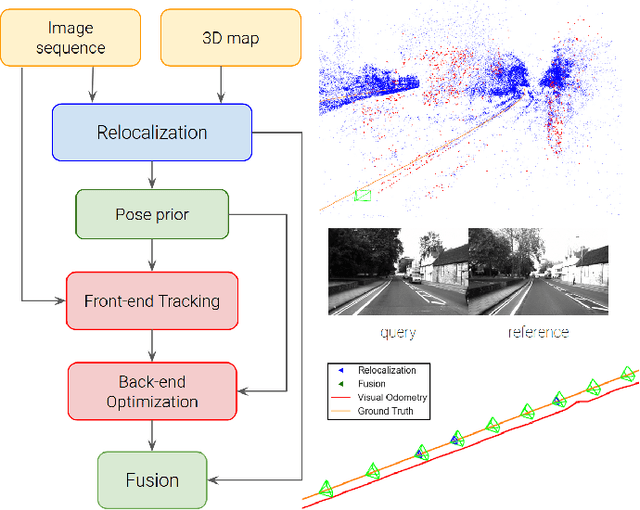
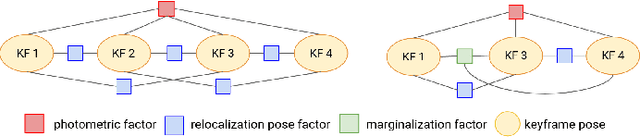
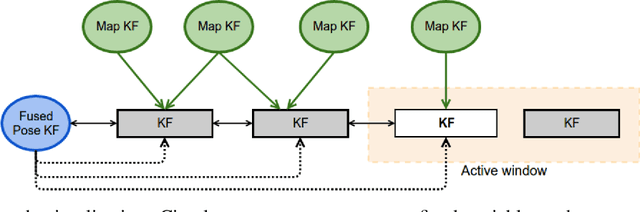
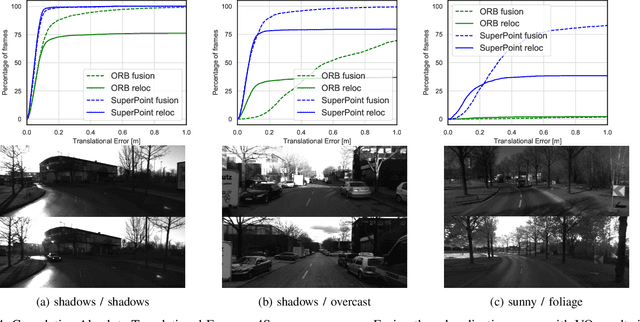
In this paper we propose a framework for integrating map-based relocalization into online direct visual odometry. To achieve map-based relocalization for direct methods, we integrate image features into Direct Sparse Odometry (DSO) and rely on feature matching to associate online visual odometry (VO) with a previously built map. The integration of the relocalization poses is threefold. Firstly, they are treated as pose priors and tightly integrated into the direct image alignment of the front-end tracking. Secondly, they are also tightly integrated into the back-end bundle adjustment. An online fusion module is further proposed to combine relative VO poses and global relocalization poses in a pose graph to estimate keyframe-wise smooth and globally accurate poses. We evaluate our method on two multi-weather datasets showing the benefits of integrating different handcrafted and learned features and demonstrating promising improvements on camera tracking accuracy.