 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUltraGauss: Ultrafast Gaussian Reconstruction of 3D Ultrasound Volumes
May 08, 2025Ultrasound imaging is widely used due to its safety, affordability, and real-time capabilities, but its 2D interpretation is highly operator-dependent, leading to variability and increased cognitive demand. 2D-to-3D reconstruction mitigates these challenges by providing standardized volumetric views, yet existing methods are often computationally expensive, memory-intensive, or incompatible with ultrasound physics. We introduce UltraGauss: the first ultrasound-specific Gaussian Splatting framework, extending view synthesis techniques to ultrasound wave propagation. Unlike conventional perspective-based splatting, UltraGauss models probe-plane intersections in 3D, aligning with acoustic image formation. We derive an efficient rasterization boundary formulation for GPU parallelization and introduce a numerically stable covariance parametrization, improving computational efficiency and reconstruction accuracy. On real clinical ultrasound data, UltraGauss achieves state-of-the-art reconstructions in 5 minutes, and reaching 0.99 SSIM within 20 minutes on a single GPU. A survey of expert clinicians confirms UltraGauss' reconstructions are the most realistic among competing methods. Our CUDA implementation will be released upon publication.
UniLoc: Towards Universal Place Recognition Using Any Single Modality
Dec 16, 2024To date, most place recognition methods focus on single-modality retrieval. While they perform well in specific environments, cross-modal methods offer greater flexibility by allowing seamless switching between map and query sources. It also promises to reduce computation requirements by having a unified model, and achieving greater sample efficiency by sharing parameters. In this work, we develop a universal solution to place recognition, UniLoc, that works with any single query modality (natural language, image, or point cloud). UniLoc leverages recent advances in large-scale contrastive learning, and learns by matching hierarchically at two levels: instance-level matching and scene-level matching. Specifically, we propose a novel Self-Attention based Pooling (SAP) module to evaluate the importance of instance descriptors when aggregated into a place-level descriptor. Experiments on the KITTI-360 dataset demonstrate the benefits of cross-modality for place recognition, achieving superior performance in cross-modal settings and competitive results also for uni-modal scenarios. Our project page is publicly available at https://yan-xia.github.io/projects/UniLoc/.
TrafficLoc: Localizing Traffic Surveillance Cameras in 3D Scenes
Dec 13, 2024



We tackle the problem of localizing the traffic surveillance cameras in cooperative perception. To overcome the lack of large-scale real-world intersection datasets, we introduce Carla Intersection, a new simulated dataset with 75 urban and rural intersections in Carla. Moreover, we introduce a novel neural network, TrafficLoc, localizing traffic cameras within a 3D reference map. TrafficLoc employs a coarse-to-fine matching pipeline. For image-point cloud feature fusion, we propose a novel Geometry-guided Attention Loss to address cross-modal viewpoint inconsistencies. During coarse matching, we propose an Inter-Intra Contrastive Learning to achieve precise alignment while preserving distinctiveness among local intra-features within image patch-point group pairs. Besides, we introduce Dense Training Alignment with a soft-argmax operator to consider additional features when regressing the final position. Extensive experiments show that our TrafficLoc improves the localization accuracy over the state-of-the-art Image-to-point cloud registration methods by a large margin (up to 86%) on Carla Intersection and generalizes well to real-world data. TrafficLoc also achieves new SOTA performance on KITTI and NuScenes datasets, demonstrating strong localization ability across both in-vehicle and traffic cameras. Our project page is publicly available at https://tum-luk.github.io/projects/trafficloc/.
VisualPredicator: Learning Abstract World Models with Neuro-Symbolic Predicates for Robot Planning
Oct 30, 2024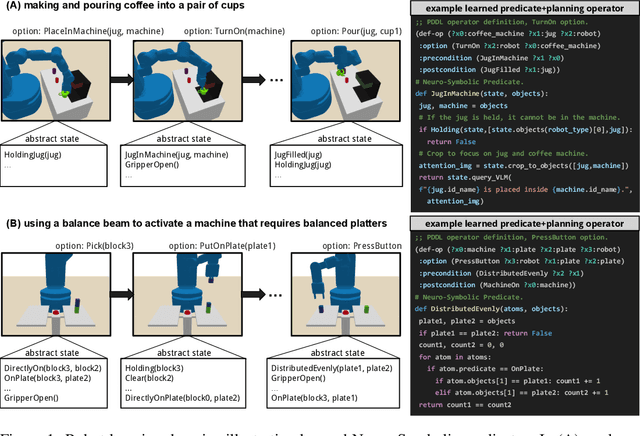
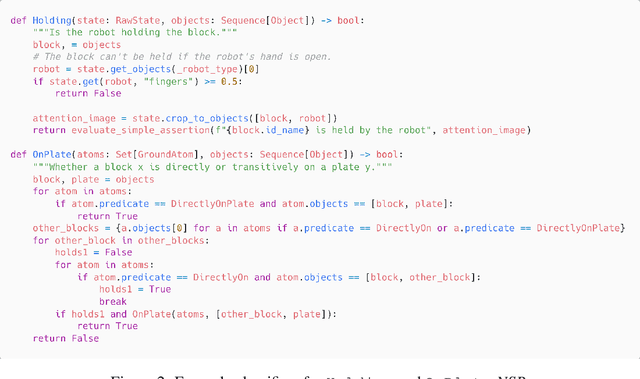
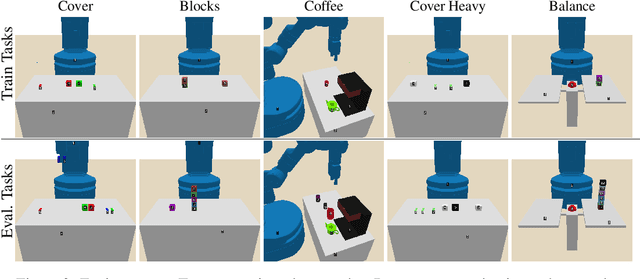
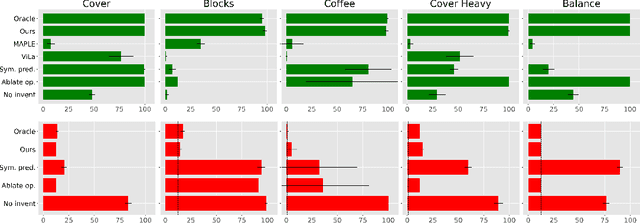
Broadly intelligent agents should form task-specific abstractions that selectively expose the essential elements of a task, while abstracting away the complexity of the raw sensorimotor space. In this work, we present Neuro-Symbolic Predicates, a first-order abstraction language that combines the strengths of symbolic and neural knowledge representations. We outline an online algorithm for inventing such predicates and learning abstract world models. We compare our approach to hierarchical reinforcement learning, vision-language model planning, and symbolic predicate invention approaches, on both in- and out-of-distribution tasks across five simulated robotic domains. Results show that our approach offers better sample complexity, stronger out-of-distribution generalization, and improved interpretability.
Interpretable Representation Learning from Videos using Nonlinear Priors
Oct 24, 2024



Learning interpretable representations of visual data is an important challenge, to make machines' decisions understandable to humans and to improve generalisation outside of the training distribution. To this end, we propose a deep learning framework where one can specify nonlinear priors for videos (e.g. of Newtonian physics) that allow the model to learn interpretable latent variables and use these to generate videos of hypothetical scenarios not observed at training time. We do this by extending the Variational Auto-Encoder (VAE) prior from a simple isotropic Gaussian to an arbitrary nonlinear temporal Additive Noise Model (ANM), which can describe a large number of processes (e.g. Newtonian physics). We propose a novel linearization method that constructs a Gaussian Mixture Model (GMM) approximating the prior, and derive a numerically stable Monte Carlo estimate of the KL divergence between the posterior and prior GMMs. We validate the method on different real-world physics videos including a pendulum, a mass on a spring, a falling object and a pulsar (rotating neutron star). We specify a physical prior for each experiment and show that the correct variables are learned. Once a model is trained, we intervene on it to change different physical variables (such as oscillation amplitude or adding air drag) to generate physically correct videos of hypothetical scenarios that were not observed previously.
Dissecting Temporal Understanding in Text-to-Audio Retrieval
Sep 01, 2024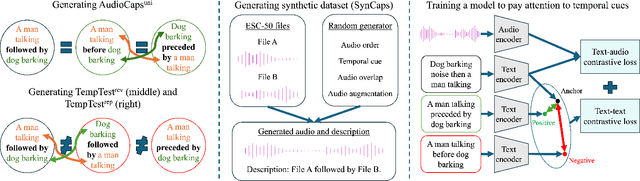
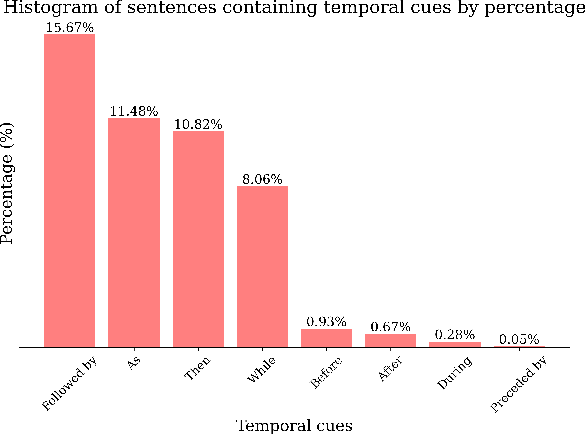
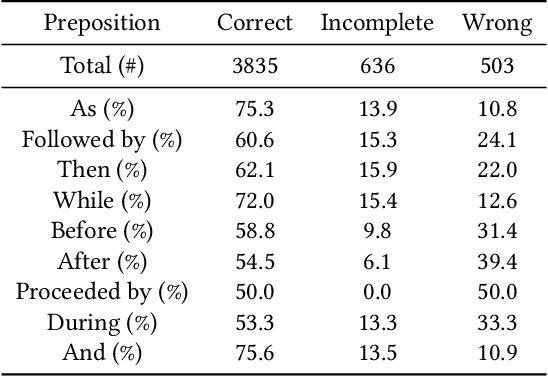
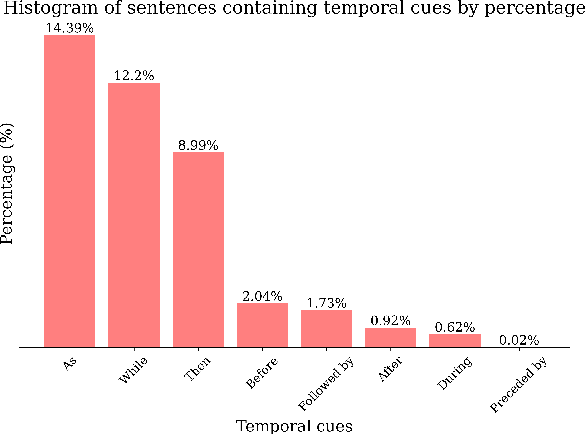
Recent advancements in machine learning have fueled research on multimodal tasks, such as for instance text-to-video and text-to-audio retrieval. These tasks require models to understand the semantic content of video and audio data, including objects, and characters. The models also need to learn spatial arrangements and temporal relationships. In this work, we analyse the temporal ordering of sounds, which is an understudied problem in the context of text-to-audio retrieval. In particular, we dissect the temporal understanding capabilities of a state-of-the-art model for text-to-audio retrieval on the AudioCaps and Clotho datasets. Additionally, we introduce a synthetic text-audio dataset that provides a controlled setting for evaluating temporal capabilities of recent models. Lastly, we present a loss function that encourages text-audio models to focus on the temporal ordering of events. Code and data are available at https://www.robots.ox.ac.uk/~vgg/research/audio-retrieval/dtu/.
3D-Aware Instance Segmentation and Tracking in Egocentric Videos
Aug 19, 2024



Egocentric videos present unique challenges for 3D scene understanding due to rapid camera motion, frequent object occlusions, and limited object visibility. This paper introduces a novel approach to instance segmentation and tracking in first-person video that leverages 3D awareness to overcome these obstacles. Our method integrates scene geometry, 3D object centroid tracking, and instance segmentation to create a robust framework for analyzing dynamic egocentric scenes. By incorporating spatial and temporal cues, we achieve superior performance compared to state-of-the-art 2D approaches. Extensive evaluations on the challenging EPIC Fields dataset demonstrate significant improvements across a range of tracking and segmentation consistency metrics. Specifically, our method outperforms the next best performing approach by $7$ points in Association Accuracy (AssA) and $4.5$ points in IDF1 score, while reducing the number of ID switches by $73\%$ to $80\%$ across various object categories. Leveraging our tracked instance segmentations, we showcase downstream applications in 3D object reconstruction and amodal video object segmentation in these egocentric settings.
SOAP-RL: Sequential Option Advantage Propagation for Reinforcement Learning in POMDP Environments
Jul 26, 2024



This work compares ways of extending Reinforcement Learning algorithms to Partially Observed Markov Decision Processes (POMDPs) with options. One view of options is as temporally extended action, which can be realized as a memory that allows the agent to retain historical information beyond the policy's context window. While option assignment could be handled using heuristics and hand-crafted objectives, learning temporally consistent options and associated sub-policies without explicit supervision is a challenge. Two algorithms, PPOEM and SOAP, are proposed and studied in depth to address this problem. PPOEM applies the forward-backward algorithm (for Hidden Markov Models) to optimize the expected returns for an option-augmented policy. However, this learning approach is unstable during on-policy rollouts. It is also unsuited for learning causal policies without the knowledge of future trajectories, since option assignments are optimized for offline sequences where the entire episode is available. As an alternative approach, SOAP evaluates the policy gradient for an optimal option assignment. It extends the concept of the generalized advantage estimation (GAE) to propagate option advantages through time, which is an analytical equivalent to performing temporal back-propagation of option policy gradients. This option policy is only conditional on the history of the agent, not future actions. Evaluated against competing baselines, SOAP exhibited the most robust performance, correctly discovering options for POMDP corridor environments, as well as on standard benchmarks including Atari and MuJoCo, outperforming PPOEM, as well as LSTM and Option-Critic baselines. The open-sourced code is available at https://github.com/shuishida/SoapRL.
Unsupervised Object Detection with Theoretical Guarantees
Jun 11, 2024Unsupervised object detection using deep neural networks is typically a difficult problem with few to no guarantees about the learned representation. In this work we present the first unsupervised object detection method that is theoretically guaranteed to recover the true object positions up to quantifiable small shifts. We develop an unsupervised object detection architecture and prove that the learned variables correspond to the true object positions up to small shifts related to the encoder and decoder receptive field sizes, the object sizes, and the widths of the Gaussians used in the rendering process. We perform detailed analysis of how the error depends on each of these variables and perform synthetic experiments validating our theoretical predictions up to a precision of individual pixels. We also perform experiments on CLEVR-based data and show that, unlike current SOTA object detection methods (SAM, CutLER), our method's prediction errors always lie within our theoretical bounds. We hope that this work helps open up an avenue of research into object detection methods with theoretical guarantees.
Flash3D: Feed-Forward Generalisable 3D Scene Reconstruction from a Single Image
Jun 06, 2024In this paper, we propose Flash3D, a method for scene reconstruction and novel view synthesis from a single image which is both very generalisable and efficient. For generalisability, we start from a "foundation" model for monocular depth estimation and extend it to a full 3D shape and appearance reconstructor. For efficiency, we base this extension on feed-forward Gaussian Splatting. Specifically, we predict a first layer of 3D Gaussians at the predicted depth, and then add additional layers of Gaussians that are offset in space, allowing the model to complete the reconstruction behind occlusions and truncations. Flash3D is very efficient, trainable on a single GPU in a day, and thus accessible to most researchers. It achieves state-of-the-art results when trained and tested on RealEstate10k. When transferred to unseen datasets like NYU it outperforms competitors by a large margin. More impressively, when transferred to KITTI, Flash3D achieves better PSNR than methods trained specifically on that dataset. In some instances, it even outperforms recent methods that use multiple views as input. Code, models, demo, and more results are available at https://www.robots.ox.ac.uk/~vgg/research/flash3d/.