 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParticulate: Feed-Forward 3D Object Articulation
Dec 12, 2025We present Particulate, a feed-forward approach that, given a single static 3D mesh of an everyday object, directly infers all attributes of the underlying articulated structure, including its 3D parts, kinematic structure, and motion constraints. At its core is a transformer network, Part Articulation Transformer, which processes a point cloud of the input mesh using a flexible and scalable architecture to predict all the aforementioned attributes with native multi-joint support. We train the network end-to-end on a diverse collection of articulated 3D assets from public datasets. During inference, Particulate lifts the network's feed-forward prediction to the input mesh, yielding a fully articulated 3D model in seconds, much faster than prior approaches that require per-object optimization. Particulate can also accurately infer the articulated structure of AI-generated 3D assets, enabling full-fledged extraction of articulated 3D objects from a single (real or synthetic) image when combined with an off-the-shelf image-to-3D generator. We further introduce a new challenging benchmark for 3D articulation estimation curated from high-quality public 3D assets, and redesign the evaluation protocol to be more consistent with human preferences. Quantitative and qualitative results show that Particulate significantly outperforms state-of-the-art approaches.
Geo4D: Leveraging Video Generators for Geometric 4D Scene Reconstruction
Apr 10, 2025We introduce Geo4D, a method to repurpose video diffusion models for monocular 3D reconstruction of dynamic scenes. By leveraging the strong dynamic prior captured by such video models, Geo4D can be trained using only synthetic data while generalizing well to real data in a zero-shot manner. Geo4D predicts several complementary geometric modalities, namely point, depth, and ray maps. It uses a new multi-modal alignment algorithm to align and fuse these modalities, as well as multiple sliding windows, at inference time, thus obtaining robust and accurate 4D reconstruction of long videos. Extensive experiments across multiple benchmarks show that Geo4D significantly surpasses state-of-the-art video depth estimation methods, including recent methods such as MonST3R, which are also designed to handle dynamic scenes.
Semantix: An Energy Guided Sampler for Semantic Style Transfer
Mar 28, 2025
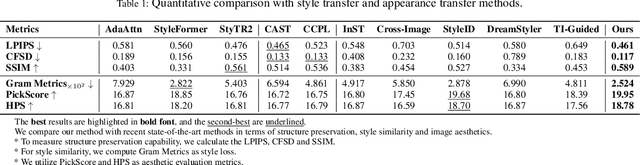
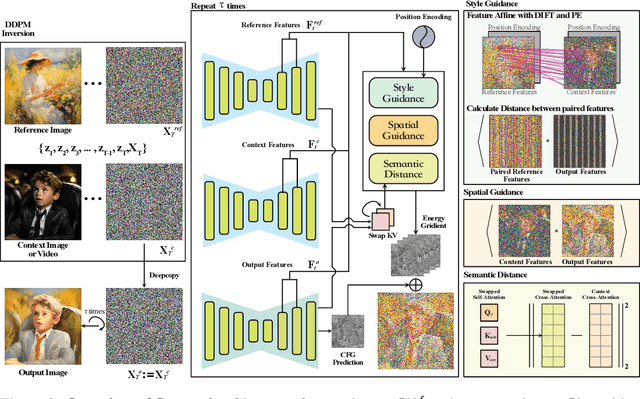
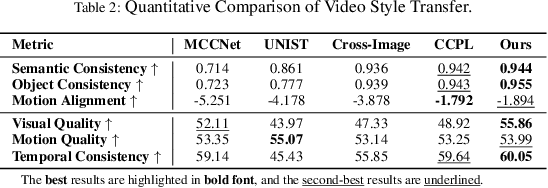
Recent advances in style and appearance transfer are impressive, but most methods isolate global style and local appearance transfer, neglecting semantic correspondence. Additionally, image and video tasks are typically handled in isolation, with little focus on integrating them for video transfer. To address these limitations, we introduce a novel task, Semantic Style Transfer, which involves transferring style and appearance features from a reference image to a target visual content based on semantic correspondence. We subsequently propose a training-free method, Semantix an energy-guided sampler designed for Semantic Style Transfer that simultaneously guides both style and appearance transfer based on semantic understanding capacity of pre-trained diffusion models. Additionally, as a sampler, Semantix be seamlessly applied to both image and video models, enabling semantic style transfer to be generic across various visual media. Specifically, once inverting both reference and context images or videos to noise space by SDEs, Semantix utilizes a meticulously crafted energy function to guide the sampling process, including three key components: Style Feature Guidance, Spatial Feature Guidance and Semantic Distance as a regularisation term. Experimental results demonstrate that Semantix not only effectively accomplishes the task of semantic style transfer across images and videos, but also surpasses existing state-of-the-art solutions in both fields. The project website is available at https://huiang-he.github.io/semantix/
DSO: Aligning 3D Generators with Simulation Feedback for Physical Soundness
Mar 28, 2025Most 3D object generators focus on aesthetic quality, often neglecting physical constraints necessary in applications. One such constraint is that the 3D object should be self-supporting, i.e., remains balanced under gravity. Prior approaches to generating stable 3D objects used differentiable physics simulators to optimize geometry at test-time, which is slow, unstable, and prone to local optima. Inspired by the literature on aligning generative models to external feedback, we propose Direct Simulation Optimization (DSO), a framework to use the feedback from a (non-differentiable) simulator to increase the likelihood that the 3D generator outputs stable 3D objects directly. We construct a dataset of 3D objects labeled with a stability score obtained from the physics simulator. We can then fine-tune the 3D generator using the stability score as the alignment metric, via direct preference optimization (DPO) or direct reward optimization (DRO), a novel objective, which we introduce, to align diffusion models without requiring pairwise preferences. Our experiments show that the fine-tuned feed-forward generator, using either DPO or DRO objective, is much faster and more likely to produce stable objects than test-time optimization. Notably, the DSO framework works even without any ground-truth 3D objects for training, allowing the 3D generator to self-improve by automatically collecting simulation feedback on its own outputs.
Amodal3R: Amodal 3D Reconstruction from Occluded 2D Images
Mar 17, 2025Most image-based 3D object reconstructors assume that objects are fully visible, ignoring occlusions that commonly occur in real-world scenarios. In this paper, we introduce Amodal3R, a conditional 3D generative model designed to reconstruct 3D objects from partial observations. We start from a "foundation" 3D generative model and extend it to recover plausible 3D geometry and appearance from occluded objects. We introduce a mask-weighted multi-head cross-attention mechanism followed by an occlusion-aware attention layer that explicitly leverages occlusion priors to guide the reconstruction process. We demonstrate that, by training solely on synthetic data, Amodal3R learns to recover full 3D objects even in the presence of occlusions in real scenes. It substantially outperforms existing methods that independently perform 2D amodal completion followed by 3D reconstruction, thereby establishing a new benchmark for occlusion-aware 3D reconstruction.
One-shot Human Motion Transfer via Occlusion-Robust Flow Prediction and Neural Texturing
Dec 09, 2024



Human motion transfer aims at animating a static source image with a driving video. While recent advances in one-shot human motion transfer have led to significant improvement in results, it remains challenging for methods with 2D body landmarks, skeleton and semantic mask to accurately capture correspondences between source and driving poses due to the large variation in motion and articulation complexity. In addition, the accuracy and precision of DensePose degrade the image quality for neural-rendering-based methods. To address the limitations and by both considering the importance of appearance and geometry for motion transfer, in this work, we proposed a unified framework that combines multi-scale feature warping and neural texture mapping to recover better 2D appearance and 2.5D geometry, partly by exploiting the information from DensePose, yet adapting to its inherent limited accuracy. Our model takes advantage of multiple modalities by jointly training and fusing them, which allows it to robust neural texture features that cope with geometric errors as well as multi-scale dense motion flow that better preserves appearance. Experimental results with full and half-view body video datasets demonstrate that our model can generalize well and achieve competitive results, and that it is particularly effective in handling challenging cases such as those with substantial self-occlusions.
MVSplat360: Feed-Forward 360 Scene Synthesis from Sparse Views
Nov 07, 2024

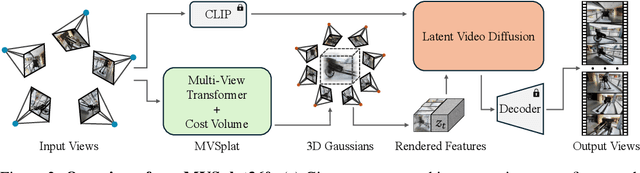
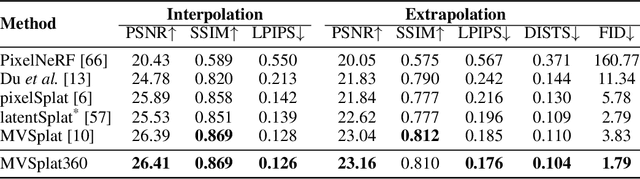
We introduce MVSplat360, a feed-forward approach for 360{\deg} novel view synthesis (NVS) of diverse real-world scenes, using only sparse observations. This setting is inherently ill-posed due to minimal overlap among input views and insufficient visual information provided, making it challenging for conventional methods to achieve high-quality results. Our MVSplat360 addresses this by effectively combining geometry-aware 3D reconstruction with temporally consistent video generation. Specifically, it refactors a feed-forward 3D Gaussian Splatting (3DGS) model to render features directly into the latent space of a pre-trained Stable Video Diffusion (SVD) model, where these features then act as pose and visual cues to guide the denoising process and produce photorealistic 3D-consistent views. Our model is end-to-end trainable and supports rendering arbitrary views with as few as 5 sparse input views. To evaluate MVSplat360's performance, we introduce a new benchmark using the challenging DL3DV-10K dataset, where MVSplat360 achieves superior visual quality compared to state-of-the-art methods on wide-sweeping or even 360{\deg} NVS tasks. Experiments on the existing benchmark RealEstate10K also confirm the effectiveness of our model. The video results are available on our project page: https://donydchen.github.io/mvsplat360.
Splatt3R: Zero-shot Gaussian Splatting from Uncalibarated Image Pairs
Aug 25, 2024In this paper, we introduce Splatt3R, a pose-free, feed-forward method for in-the-wild 3D reconstruction and novel view synthesis from stereo pairs. Given uncalibrated natural images, Splatt3R can predict 3D Gaussian Splats without requiring any camera parameters or depth information. For generalizability, we start from a 'foundation' 3D geometry reconstruction method, MASt3R, and extend it to be a full 3D structure and appearance reconstructor. Specifically, unlike the original MASt3R which reconstructs only 3D point clouds, we predict the additional Gaussian attributes required to construct a Gaussian primitive for each point. Hence, unlike other novel view synthesis methods, Splatt3R is first trained by optimizing the 3D point cloud's geometry loss, and then a novel view synthesis objective. By doing this, we avoid the local minima present in training 3D Gaussian Splats from stereo views. We also propose a novel loss masking strategy that we empirically find is critical for strong performance on extrapolated viewpoints. We train Splatt3R on the ScanNet++ dataset and demonstrate excellent generalisation to uncalibrated, in-the-wild images. Splatt3R can reconstruct scenes at 4FPS at 512 x 512 resolution, and the resultant splats can be rendered in real-time.
Puppet-Master: Scaling Interactive Video Generation as a Motion Prior for Part-Level Dynamics
Aug 08, 2024



We present Puppet-Master, an interactive video generative model that can serve as a motion prior for part-level dynamics. At test time, given a single image and a sparse set of motion trajectories (i.e., drags), Puppet-Master can synthesize a video depicting realistic part-level motion faithful to the given drag interactions. This is achieved by fine-tuning a large-scale pre-trained video diffusion model, for which we propose a new conditioning architecture to inject the dragging control effectively. More importantly, we introduce the all-to-first attention mechanism, a drop-in replacement for the widely adopted spatial attention modules, which significantly improves generation quality by addressing the appearance and background issues in existing models. Unlike other motion-conditioned video generators that are trained on in-the-wild videos and mostly move an entire object, Puppet-Master is learned from Objaverse-Animation-HQ, a new dataset of curated part-level motion clips. We propose a strategy to automatically filter out sub-optimal animations and augment the synthetic renderings with meaningful motion trajectories. Puppet-Master generalizes well to real images across various categories and outperforms existing methods in a zero-shot manner on a real-world benchmark. See our project page for more results: vgg-puppetmaster.github.io.
Flash3D: Feed-Forward Generalisable 3D Scene Reconstruction from a Single Image
Jun 06, 2024In this paper, we propose Flash3D, a method for scene reconstruction and novel view synthesis from a single image which is both very generalisable and efficient. For generalisability, we start from a "foundation" model for monocular depth estimation and extend it to a full 3D shape and appearance reconstructor. For efficiency, we base this extension on feed-forward Gaussian Splatting. Specifically, we predict a first layer of 3D Gaussians at the predicted depth, and then add additional layers of Gaussians that are offset in space, allowing the model to complete the reconstruction behind occlusions and truncations. Flash3D is very efficient, trainable on a single GPU in a day, and thus accessible to most researchers. It achieves state-of-the-art results when trained and tested on RealEstate10k. When transferred to unseen datasets like NYU it outperforms competitors by a large margin. More impressively, when transferred to KITTI, Flash3D achieves better PSNR than methods trained specifically on that dataset. In some instances, it even outperforms recent methods that use multiple views as input. Code, models, demo, and more results are available at https://www.robots.ox.ac.uk/~vgg/research/flash3d/.