 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMVSplat360: Feed-Forward 360 Scene Synthesis from Sparse Views
Nov 07, 2024

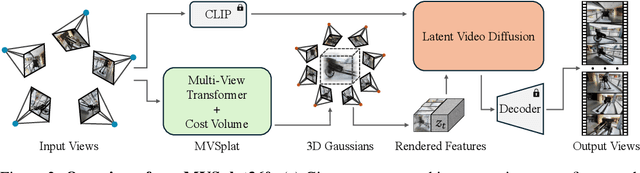
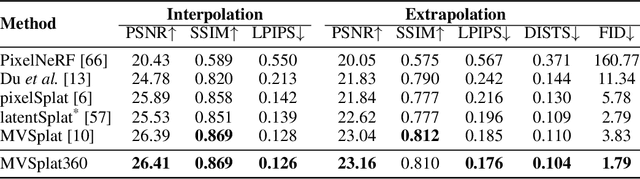
We introduce MVSplat360, a feed-forward approach for 360{\deg} novel view synthesis (NVS) of diverse real-world scenes, using only sparse observations. This setting is inherently ill-posed due to minimal overlap among input views and insufficient visual information provided, making it challenging for conventional methods to achieve high-quality results. Our MVSplat360 addresses this by effectively combining geometry-aware 3D reconstruction with temporally consistent video generation. Specifically, it refactors a feed-forward 3D Gaussian Splatting (3DGS) model to render features directly into the latent space of a pre-trained Stable Video Diffusion (SVD) model, where these features then act as pose and visual cues to guide the denoising process and produce photorealistic 3D-consistent views. Our model is end-to-end trainable and supports rendering arbitrary views with as few as 5 sparse input views. To evaluate MVSplat360's performance, we introduce a new benchmark using the challenging DL3DV-10K dataset, where MVSplat360 achieves superior visual quality compared to state-of-the-art methods on wide-sweeping or even 360{\deg} NVS tasks. Experiments on the existing benchmark RealEstate10K also confirm the effectiveness of our model. The video results are available on our project page: https://donydchen.github.io/mvsplat360.
MVSplat: Efficient 3D Gaussian Splatting from Sparse Multi-View Images
Mar 21, 2024We propose MVSplat, an efficient feed-forward 3D Gaussian Splatting model learned from sparse multi-view images. To accurately localize the Gaussian centers, we propose to build a cost volume representation via plane sweeping in the 3D space, where the cross-view feature similarities stored in the cost volume can provide valuable geometry cues to the estimation of depth. We learn the Gaussian primitives' opacities, covariances, and spherical harmonics coefficients jointly with the Gaussian centers while only relying on photometric supervision. We demonstrate the importance of the cost volume representation in learning feed-forward Gaussian Splatting models via extensive experimental evaluations. On the large-scale RealEstate10K and ACID benchmarks, our model achieves state-of-the-art performance with the fastest feed-forward inference speed (22 fps). Compared to the latest state-of-the-art method pixelSplat, our model uses $10\times $ fewer parameters and infers more than $2\times$ faster while providing higher appearance and geometry quality as well as better cross-dataset generalization.
MuRF: Multi-Baseline Radiance Fields
Dec 07, 2023



We present Multi-Baseline Radiance Fields (MuRF), a general feed-forward approach to solving sparse view synthesis under multiple different baseline settings (small and large baselines, and different number of input views). To render a target novel view, we discretize the 3D space into planes parallel to the target image plane, and accordingly construct a target view frustum volume. Such a target volume representation is spatially aligned with the target view, which effectively aggregates relevant information from the input views for high-quality rendering. It also facilitates subsequent radiance field regression with a convolutional network thanks to its axis-aligned nature. The 3D context modeled by the convolutional network enables our method to synthesis sharper scene structures than prior works. Our MuRF achieves state-of-the-art performance across multiple different baseline settings and diverse scenarios ranging from simple objects (DTU) to complex indoor and outdoor scenes (RealEstate10K and LLFF). We also show promising zero-shot generalization abilities on the Mip-NeRF 360 dataset, demonstrating the general applicability of MuRF.
Explicit Correspondence Matching for Generalizable Neural Radiance Fields
Apr 24, 2023



We present a new generalizable NeRF method that is able to directly generalize to new unseen scenarios and perform novel view synthesis with as few as two source views. The key to our approach lies in the explicitly modeled correspondence matching information, so as to provide the geometry prior to the prediction of NeRF color and density for volume rendering. The explicit correspondence matching is quantified with the cosine similarity between image features sampled at the 2D projections of a 3D point on different views, which is able to provide reliable cues about the surface geometry. Unlike previous methods where image features are extracted independently for each view, we consider modeling the cross-view interactions via Transformer cross-attention, which greatly improves the feature matching quality. Our method achieves state-of-the-art results on different evaluation settings, with the experiments showing a strong correlation between our learned cosine feature similarity and volume density, demonstrating the effectiveness and superiority of our proposed method. Code is at https://github.com/donydchen/matchnerf
Object-Compositional Neural Implicit Surfaces
Jul 20, 2022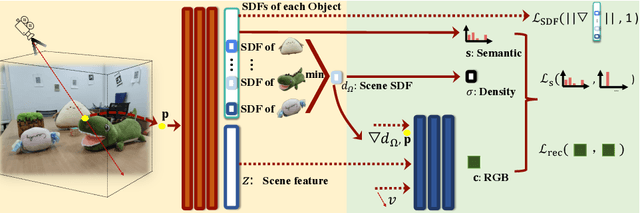
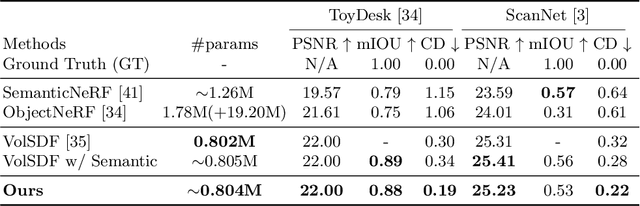

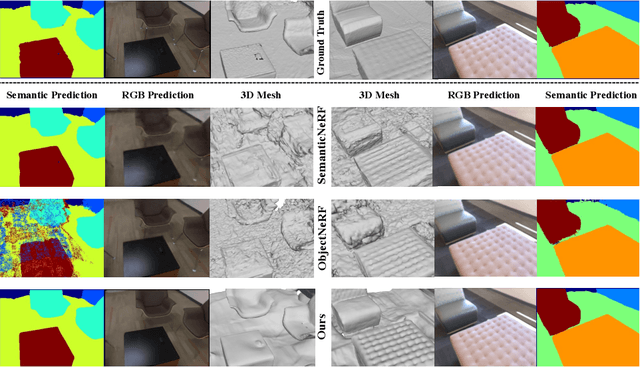
The neural implicit representation has shown its effectiveness in novel view synthesis and high-quality 3D reconstruction from multi-view images. However, most approaches focus on holistic scene representation yet ignore individual objects inside it, thus limiting potential downstream applications. In order to learn object-compositional representation, a few works incorporate the 2D semantic map as a cue in training to grasp the difference between objects. But they neglect the strong connections between object geometry and instance semantic information, which leads to inaccurate modeling of individual instance. This paper proposes a novel framework, ObjectSDF, to build an object-compositional neural implicit representation with high fidelity in 3D reconstruction and object representation. Observing the ambiguity of conventional volume rendering pipelines, we model the scene by combining the Signed Distance Functions (SDF) of individual object to exert explicit surface constraint. The key in distinguishing different instances is to revisit the strong association between an individual object's SDF and semantic label. Particularly, we convert the semantic information to a function of object SDF and develop a unified and compact representation for scene and objects. Experimental results show the superiority of ObjectSDF framework in representing both the holistic object-compositional scene and the individual instances. Code can be found at https://qianyiwu.github.io/objectsdf/
Sem2NeRF: Converting Single-View Semantic Masks to Neural Radiance Fields
Mar 21, 2022

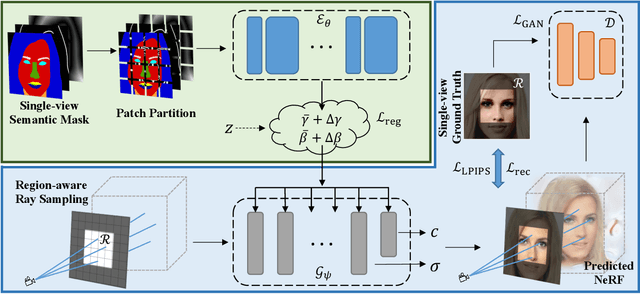

Image translation and manipulation have gain increasing attention along with the rapid development of deep generative models. Although existing approaches have brought impressive results, they mainly operated in 2D space. In light of recent advances in NeRF-based 3D-aware generative models, we introduce a new task, Semantic-to-NeRF translation, that aims to reconstruct a 3D scene modelled by NeRF, conditioned on one single-view semantic mask as input. To kick-off this novel task, we propose the Sem2NeRF framework. In particular, Sem2NeRF addresses the highly challenging task by encoding the semantic mask into the latent code that controls the 3D scene representation of a pretrained decoder. To further improve the accuracy of the mapping, we integrate a new region-aware learning strategy into the design of both the encoder and the decoder. We verify the efficacy of the proposed Sem2NeRF and demonstrate that it outperforms several strong baselines on two benchmark datasets.
Edge Prior Augmented Networks for Motion Deblurring on Naturally Blurry Images
Sep 18, 2021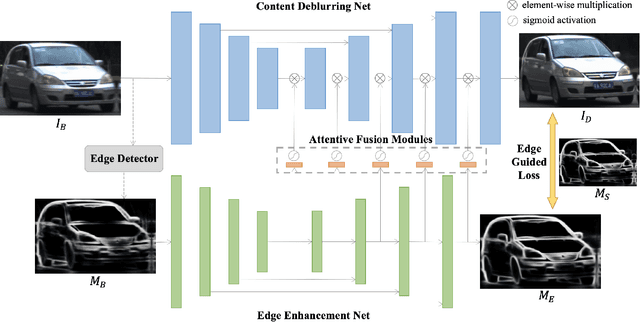



Motion deblurring has witnessed rapid development in recent years, and most of the recent methods address it by using deep learning techniques, with the help of different kinds of prior knowledge. Concerning that deblurring is essentially expected to improve the image sharpness, edge information can serve as an important prior. However, the edge has not yet been seriously taken into consideration in previous methods when designing deep models. To this end, we present a novel framework that incorporates edge prior knowledge into deep models, termed Edge Prior Augmented Networks (EPAN). EPAN has a content-based main branch and an edge-based auxiliary branch, which are constructed as a Content Deblurring Net (CDN) and an Edge Enhancement Net (EEN), respectively. EEN is designed to augment CDN in the deblurring process via an attentive fusion mechanism, where edge features are mapped as spatial masks to guide content features in a feature-based hierarchical manner. An edge-guided loss function is proposed to further regulate the optimization of EPAN by enforcing the focus on edge areas. Besides, we design a dual-camera-based image capturing setting to build a new dataset, Real Object Motion Blur (ROMB), with paired sharp and naturally blurry images of fast-moving cars, so as to better train motion deblurring models and benchmark the capability of motion deblurring algorithms in practice. Extensive experiments on the proposed ROMB and other existing datasets demonstrate that EPAN outperforms state-of-the-art approaches qualitatively and quantitatively.
Towards Unbiased Visual Emotion Recognition via Causal Intervention
Jul 26, 2021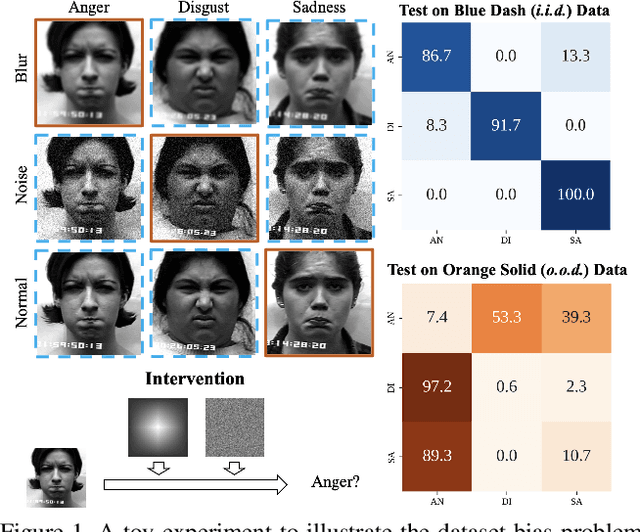

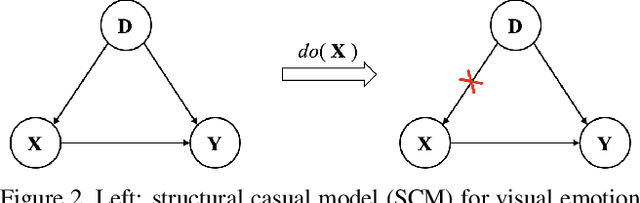

Although much progress has been made in visual emotion recognition, researchers have realized that modern deep networks tend to exploit dataset characteristics to learn spurious statistical associations between the input and the target. Such dataset characteristics are usually treated as dataset bias, which damages the robustness and generalization performance of these recognition systems. In this work, we scrutinize this problem from the perspective of causal inference, where such dataset characteristic is termed as a confounder which misleads the system to learn the spurious correlation. To alleviate the negative effects brought by the dataset bias, we propose a novel Interventional Emotion Recognition Network (IERN) to achieve the backdoor adjustment, which is one fundamental deconfounding technique in causal inference. A series of designed tests validate the effectiveness of IERN, and experiments on three emotion benchmarks demonstrate that IERN outperforms other state-of-the-art approaches.
GeoConv: Geodesic Guided Convolution for Facial Action Unit Recognition
Mar 06, 2020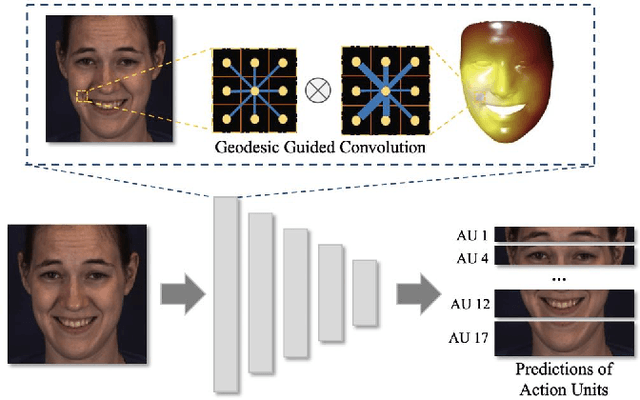
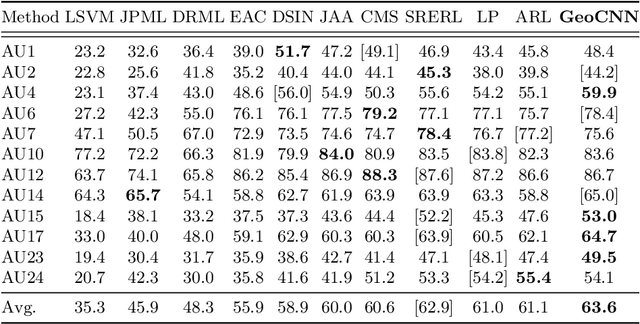
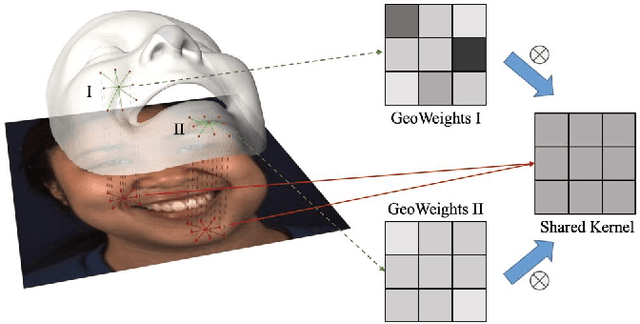
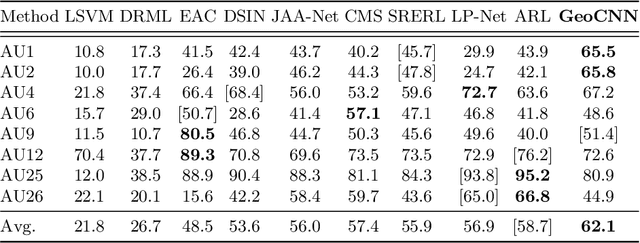
Automatic facial action unit (AU) recognition has attracted great attention but still remains a challenging task, as subtle changes of local facial muscles are difficult to thoroughly capture. Most existing AU recognition approaches leverage geometry information in a straightforward 2D or 3D manner, which either ignore 3D manifold information or suffer from high computational costs. In this paper, we propose a novel geodesic guided convolution (GeoConv) for AU recognition by embedding 3D manifold information into 2D convolutions. Specifically, the kernel of GeoConv is weighted by our introduced geodesic weights, which are negatively correlated to geodesic distances on a coarsely reconstructed 3D face model. Moreover, based on GeoConv, we further develop an end-to-end trainable framework named GeoCNN for AU recognition. Extensive experiments on BP4D and DISFA benchmarks show that our approach significantly outperforms the state-of-the-art AU recognition methods.
Facial Motion Prior Networks for Facial Expression Recognition
Feb 23, 2019
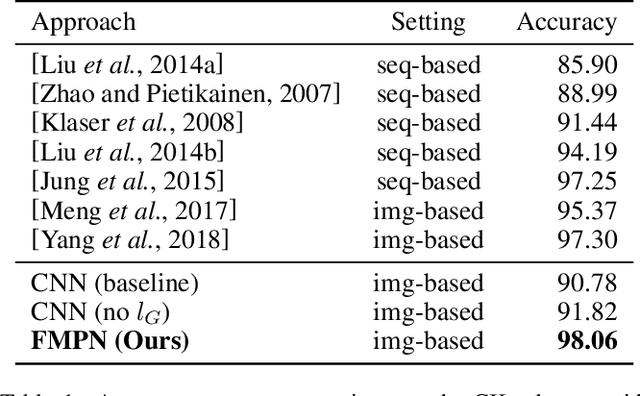

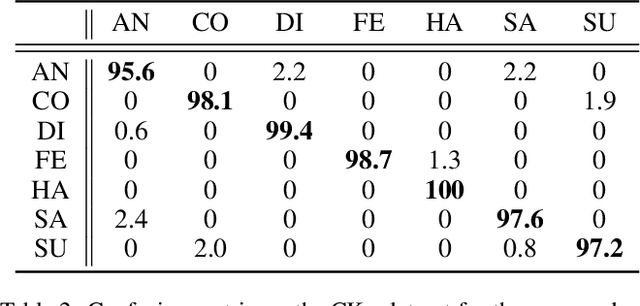
Deep learning based facial expression recognition (FER) has received a lot of attention in the past few years. Most of the existing deep learning based FER methods do not consider domain knowledge well, which thereby fail to extract representative features. In this work, we propose a novel FER framework, named Facial Motion Prior Networks (FMPN). Particularly, we introduce an addition branch to generate a facial mask so as to focus on facial muscle moving regions. To guide the facial mask learning, we propose to incorporate prior domain knowledge by using the average differences between neutral faces and the corresponding expressive faces as the guidance. Extensive experiments on four facial expression benchmark datasets demonstrate the effectiveness of the proposed method, compared with the state-of-the-art approaches.