 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPATIALALIGN: Aligning Dynamic Spatial Relationships in Video Generation
Feb 26, 2026Most text-to-video (T2V) generators prioritize aesthetic quality, but often ignoring the spatial constraints in the generated videos. In this work, we present SPATIALALIGN, a self-improvement framework that enhances T2V models capabilities to depict Dynamic Spatial Relationships (DSR) specified in text prompts. We present a zeroth-order regularized Direct Preference Optimization (DPO) to fine-tune T2V models towards better alignment with DSR. Specifically, we design DSR-SCORE, a geometry-based metric that quantitatively measures the alignment between generated videos and the specified DSRs in prompts, which is a step forward from prior works that rely on VLM for evaluation. We also conduct a dataset of text-video pairs with diverse DSRs to facilitate the study. Extensive experiments demonstrate that our fine-tuned model significantly out performs the baseline in spatial relationships. The code will be released in Link.
Semantix: An Energy Guided Sampler for Semantic Style Transfer
Mar 28, 2025
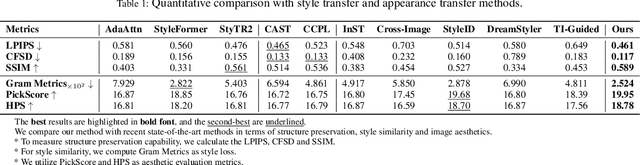
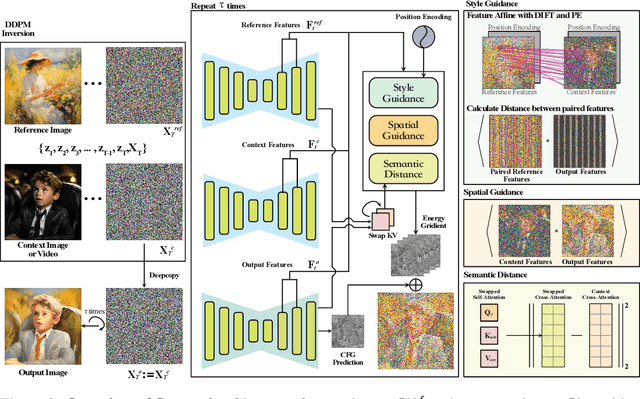
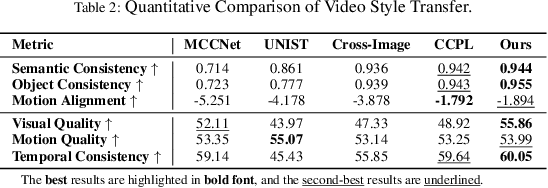
Recent advances in style and appearance transfer are impressive, but most methods isolate global style and local appearance transfer, neglecting semantic correspondence. Additionally, image and video tasks are typically handled in isolation, with little focus on integrating them for video transfer. To address these limitations, we introduce a novel task, Semantic Style Transfer, which involves transferring style and appearance features from a reference image to a target visual content based on semantic correspondence. We subsequently propose a training-free method, Semantix an energy-guided sampler designed for Semantic Style Transfer that simultaneously guides both style and appearance transfer based on semantic understanding capacity of pre-trained diffusion models. Additionally, as a sampler, Semantix be seamlessly applied to both image and video models, enabling semantic style transfer to be generic across various visual media. Specifically, once inverting both reference and context images or videos to noise space by SDEs, Semantix utilizes a meticulously crafted energy function to guide the sampling process, including three key components: Style Feature Guidance, Spatial Feature Guidance and Semantic Distance as a regularisation term. Experimental results demonstrate that Semantix not only effectively accomplishes the task of semantic style transfer across images and videos, but also surpasses existing state-of-the-art solutions in both fields. The project website is available at https://huiang-he.github.io/semantix/
Amodal3R: Amodal 3D Reconstruction from Occluded 2D Images
Mar 17, 2025Most image-based 3D object reconstructors assume that objects are fully visible, ignoring occlusions that commonly occur in real-world scenarios. In this paper, we introduce Amodal3R, a conditional 3D generative model designed to reconstruct 3D objects from partial observations. We start from a "foundation" 3D generative model and extend it to recover plausible 3D geometry and appearance from occluded objects. We introduce a mask-weighted multi-head cross-attention mechanism followed by an occlusion-aware attention layer that explicitly leverages occlusion priors to guide the reconstruction process. We demonstrate that, by training solely on synthetic data, Amodal3R learns to recover full 3D objects even in the presence of occlusions in real scenes. It substantially outperforms existing methods that independently perform 2D amodal completion followed by 3D reconstruction, thereby establishing a new benchmark for occlusion-aware 3D reconstruction.
One-shot Human Motion Transfer via Occlusion-Robust Flow Prediction and Neural Texturing
Dec 09, 2024



Human motion transfer aims at animating a static source image with a driving video. While recent advances in one-shot human motion transfer have led to significant improvement in results, it remains challenging for methods with 2D body landmarks, skeleton and semantic mask to accurately capture correspondences between source and driving poses due to the large variation in motion and articulation complexity. In addition, the accuracy and precision of DensePose degrade the image quality for neural-rendering-based methods. To address the limitations and by both considering the importance of appearance and geometry for motion transfer, in this work, we proposed a unified framework that combines multi-scale feature warping and neural texture mapping to recover better 2D appearance and 2.5D geometry, partly by exploiting the information from DensePose, yet adapting to its inherent limited accuracy. Our model takes advantage of multiple modalities by jointly training and fusing them, which allows it to robust neural texture features that cope with geometric errors as well as multi-scale dense motion flow that better preserves appearance. Experimental results with full and half-view body video datasets demonstrate that our model can generalize well and achieve competitive results, and that it is particularly effective in handling challenging cases such as those with substantial self-occlusions.
D-LORD for Motion Stylization
Dec 05, 2024This paper introduces a novel framework named D-LORD (Double Latent Optimization for Representation Disentanglement), which is designed for motion stylization (motion style transfer and motion retargeting). The primary objective of this framework is to separate the class and content information from a given motion sequence using a data-driven latent optimization approach. Here, class refers to person-specific style, such as a particular emotion or an individual's identity, while content relates to the style-agnostic aspect of an action, such as walking or jumping, as universally understood concepts. The key advantage of D-LORD is its ability to perform style transfer without needing paired motion data. Instead, it utilizes class and content labels during the latent optimization process. By disentangling the representation, the framework enables the transformation of one motion sequences style to another's style using Adaptive Instance Normalization. The proposed D-LORD framework is designed with a focus on generalization, allowing it to handle different class and content labels for various applications. Additionally, it can generate diverse motion sequences when specific class and content labels are provided. The framework's efficacy is demonstrated through experimentation on three datasets: the CMU XIA dataset for motion style transfer, the MHAD dataset, and the RRIS Ability dataset for motion retargeting. Notably, this paper presents the first generalized framework for motion style transfer and motion retargeting, showcasing its potential contributions in this area.
Gazing at Rewards: Eye Movements as a Lens into Human and AI Decision-Making in Hybrid Visual Foraging
Nov 14, 2024
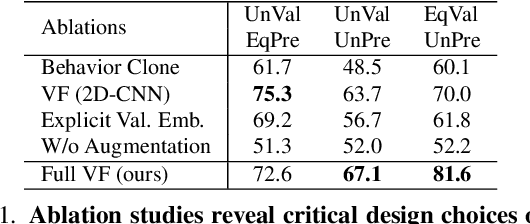


Imagine searching a collection of coins for quarters ($0.25$), dimes ($0.10$), nickels ($0.05$), and pennies ($0.01$)-a hybrid foraging task where observers look for multiple instances of multiple target types. In such tasks, how do target values and their prevalence influence foraging and eye movement behaviors (e.g., should you prioritize rare quarters or common nickels)? To explore this, we conducted human psychophysics experiments, revealing that humans are proficient reward foragers. Their eye fixations are drawn to regions with higher average rewards, fixation durations are longer on more valuable targets, and their cumulative rewards exceed chance, approaching the upper bound of optimal foragers. To probe these decision-making processes of humans, we developed a transformer-based Visual Forager (VF) model trained via reinforcement learning. Our VF model takes a series of targets, their corresponding values, and the search image as inputs, processes the images using foveated vision, and produces a sequence of eye movements along with decisions on whether to collect each fixated item. Our model outperforms all baselines, achieves cumulative rewards comparable to those of humans, and approximates human foraging behavior in eye movements and foraging biases within time-limited environments. Furthermore, stress tests on out-of-distribution tasks with novel targets, unseen values, and varying set sizes demonstrate the VF model's effective generalization. Our work offers valuable insights into the relationship between eye movements and decision-making, with our model serving as a powerful tool for further exploration of this connection. All data, code, and models will be made publicly available.
MVSplat360: Feed-Forward 360 Scene Synthesis from Sparse Views
Nov 07, 2024

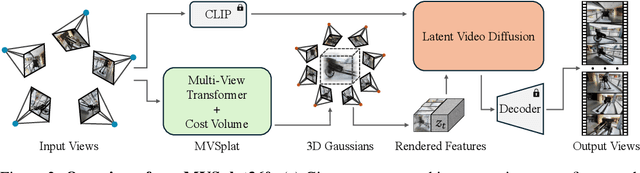
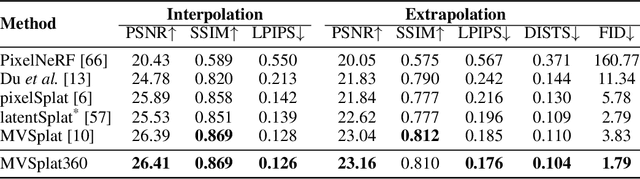
We introduce MVSplat360, a feed-forward approach for 360{\deg} novel view synthesis (NVS) of diverse real-world scenes, using only sparse observations. This setting is inherently ill-posed due to minimal overlap among input views and insufficient visual information provided, making it challenging for conventional methods to achieve high-quality results. Our MVSplat360 addresses this by effectively combining geometry-aware 3D reconstruction with temporally consistent video generation. Specifically, it refactors a feed-forward 3D Gaussian Splatting (3DGS) model to render features directly into the latent space of a pre-trained Stable Video Diffusion (SVD) model, where these features then act as pose and visual cues to guide the denoising process and produce photorealistic 3D-consistent views. Our model is end-to-end trainable and supports rendering arbitrary views with as few as 5 sparse input views. To evaluate MVSplat360's performance, we introduce a new benchmark using the challenging DL3DV-10K dataset, where MVSplat360 achieves superior visual quality compared to state-of-the-art methods on wide-sweeping or even 360{\deg} NVS tasks. Experiments on the existing benchmark RealEstate10K also confirm the effectiveness of our model. The video results are available on our project page: https://donydchen.github.io/mvsplat360.
3iGS: Factorised Tensorial Illumination for 3D Gaussian Splatting
Aug 07, 2024The use of 3D Gaussians as representation of radiance fields has enabled high quality novel view synthesis at real-time rendering speed. However, the choice of optimising the outgoing radiance of each Gaussian independently as spherical harmonics results in unsatisfactory view dependent effects. In response to these limitations, our work, Factorised Tensorial Illumination for 3D Gaussian Splatting, or 3iGS, improves upon 3D Gaussian Splatting (3DGS) rendering quality. Instead of optimising a single outgoing radiance parameter, 3iGS enhances 3DGS view-dependent effects by expressing the outgoing radiance as a function of a local illumination field and Bidirectional Reflectance Distribution Function (BRDF) features. We optimise a continuous incident illumination field through a Tensorial Factorisation representation, while separately fine-tuning the BRDF features of each 3D Gaussian relative to this illumination field. Our methodology significantly enhances the rendering quality of specular view-dependent effects of 3DGS, while maintaining rapid training and rendering speeds.
ClusteringSDF: Self-Organized Neural Implicit Surfaces for 3D Decomposition
Mar 21, 2024



3D decomposition/segmentation still remains a challenge as large-scale 3D annotated data is not readily available. Contemporary approaches typically leverage 2D machine-generated segments, integrating them for 3D consistency. While the majority of these methods are based on NeRFs, they face a potential weakness that the instance/semantic embedding features derive from independent MLPs, thus preventing the segmentation network from learning the geometric details of the objects directly through radiance and density. In this paper, we propose ClusteringSDF, a novel approach to achieve both segmentation and reconstruction in 3D via the neural implicit surface representation, specifically Signal Distance Function (SDF), where the segmentation rendering is directly integrated with the volume rendering of neural implicit surfaces. Although based on ObjectSDF++, ClusteringSDF no longer requires the ground-truth segments for supervision while maintaining the capability of reconstructing individual object surfaces, but purely with the noisy and inconsistent labels from pre-trained models.As the core of ClusteringSDF, we introduce a high-efficient clustering mechanism for lifting the 2D labels to 3D and the experimental results on the challenging scenes from ScanNet and Replica datasets show that ClusteringSDF can achieve competitive performance compared against the state-of-the-art with significantly reduced training time.
MVSplat: Efficient 3D Gaussian Splatting from Sparse Multi-View Images
Mar 21, 2024We propose MVSplat, an efficient feed-forward 3D Gaussian Splatting model learned from sparse multi-view images. To accurately localize the Gaussian centers, we propose to build a cost volume representation via plane sweeping in the 3D space, where the cross-view feature similarities stored in the cost volume can provide valuable geometry cues to the estimation of depth. We learn the Gaussian primitives' opacities, covariances, and spherical harmonics coefficients jointly with the Gaussian centers while only relying on photometric supervision. We demonstrate the importance of the cost volume representation in learning feed-forward Gaussian Splatting models via extensive experimental evaluations. On the large-scale RealEstate10K and ACID benchmarks, our model achieves state-of-the-art performance with the fastest feed-forward inference speed (22 fps). Compared to the latest state-of-the-art method pixelSplat, our model uses $10\times $ fewer parameters and infers more than $2\times$ faster while providing higher appearance and geometry quality as well as better cross-dataset generalization.