 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGazing at Rewards: Eye Movements as a Lens into Human and AI Decision-Making in Hybrid Visual Foraging
Nov 14, 2024
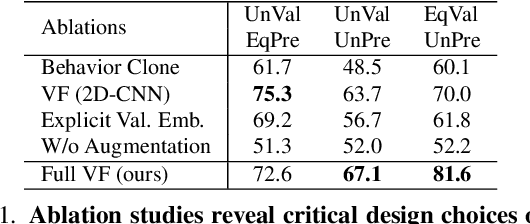


Imagine searching a collection of coins for quarters ($0.25$), dimes ($0.10$), nickels ($0.05$), and pennies ($0.01$)-a hybrid foraging task where observers look for multiple instances of multiple target types. In such tasks, how do target values and their prevalence influence foraging and eye movement behaviors (e.g., should you prioritize rare quarters or common nickels)? To explore this, we conducted human psychophysics experiments, revealing that humans are proficient reward foragers. Their eye fixations are drawn to regions with higher average rewards, fixation durations are longer on more valuable targets, and their cumulative rewards exceed chance, approaching the upper bound of optimal foragers. To probe these decision-making processes of humans, we developed a transformer-based Visual Forager (VF) model trained via reinforcement learning. Our VF model takes a series of targets, their corresponding values, and the search image as inputs, processes the images using foveated vision, and produces a sequence of eye movements along with decisions on whether to collect each fixated item. Our model outperforms all baselines, achieves cumulative rewards comparable to those of humans, and approximates human foraging behavior in eye movements and foraging biases within time-limited environments. Furthermore, stress tests on out-of-distribution tasks with novel targets, unseen values, and varying set sizes demonstrate the VF model's effective generalization. Our work offers valuable insights into the relationship between eye movements and decision-making, with our model serving as a powerful tool for further exploration of this connection. All data, code, and models will be made publicly available.
DreamFactory: Pioneering Multi-Scene Long Video Generation with a Multi-Agent Framework
Aug 21, 2024Current video generation models excel at creating short, realistic clips, but struggle with longer, multi-scene videos. We introduce \texttt{DreamFactory}, an LLM-based framework that tackles this challenge. \texttt{DreamFactory} leverages multi-agent collaboration principles and a Key Frames Iteration Design Method to ensure consistency and style across long videos. It utilizes Chain of Thought (COT) to address uncertainties inherent in large language models. \texttt{DreamFactory} generates long, stylistically coherent, and complex videos. Evaluating these long-form videos presents a challenge. We propose novel metrics such as Cross-Scene Face Distance Score and Cross-Scene Style Consistency Score. To further research in this area, we contribute the Multi-Scene Videos Dataset containing over 150 human-rated videos.