 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-like Object Grouping in Self-supervised Vision Transformers
Mar 14, 2026Vision foundation models trained with self-supervised objectives achieve strong performance across diverse tasks and exhibit emergent object segmentation properties. However, their alignment with human object perception remains poorly understood. Here, we introduce a behavioral benchmark in which participants make same/different object judgments for dot pairs on naturalistic scenes, scaling up a classical psychophysics paradigm to over 1000 trials. We test a diverse set of vision models using a simple readout from their representations to predict subjects' reaction times. We observe a steady improvement across model generations, with both architecture and training objective contributing to alignment, and transformer-based models trained with the DINO self-supervised objective showing the strongest performance. To investigate the source of this improvement, we propose a novel metric to quantify the object-centric component of representations by measuring patch similarity within and between objects. Across models, stronger object-centric structure predicts human segmentation behavior more accurately. We further show that matching the Gram matrix of supervised transformer models, capturing similarity structure across image patches, with that of a self-supervised model through distillation improves their alignment with human behavior, converging with the prior finding that Gram anchoring improves DINOv3's feature quality. Together, these results demonstrate that self-supervised vision models capture object structure in a behaviorally human-like manner, and that Gram matrix structure plays a role in driving perceptual alignment.
Learning to See Through a Baby's Eyes: Early Visual Diets Enable Robust Visual Intelligence in Humans and Machines
Nov 18, 2025Newborns perceive the world with low-acuity, color-degraded, and temporally continuous vision, which gradually sharpens as infants develop. To explore the ecological advantages of such staged "visual diets", we train self-supervised learning (SSL) models on object-centric videos under constraints that simulate infant vision: grayscale-to-color (C), blur-to-sharp (A), and preserved temporal continuity (T)-collectively termed CATDiet. For evaluation, we establish a comprehensive benchmark across ten datasets, covering clean and corrupted image recognition, texture-shape cue conflict tests, silhouette recognition, depth-order classification, and the visual cliff paradigm. All CATDiet variants demonstrate enhanced robustness in object recognition, despite being trained solely on object-centric videos. Remarkably, models also exhibit biologically aligned developmental patterns, including neural plasticity changes mirroring synaptic density in macaque V1 and behaviors resembling infants' visual cliff responses. Building on these insights, CombDiet initializes SSL with CATDiet before standard training while preserving temporal continuity. Trained on object-centric or head-mounted infant videos, CombDiet outperforms standard SSL on both in-domain and out-of-domain object recognition and depth perception. Together, these results suggest that the developmental progression of early infant visual experience offers a powerful reverse-engineering framework for understanding the emergence of robust visual intelligence in machines. All code, data, and models will be publicly released.
Dual Prompt Learning for Adapting Vision-Language Models to Downstream Image-Text Retrieval
Aug 06, 2025
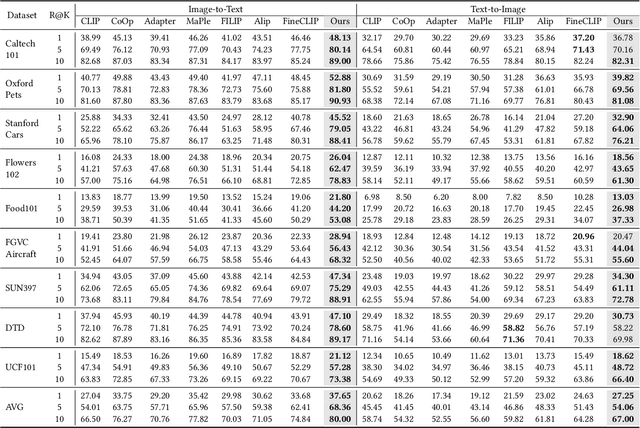
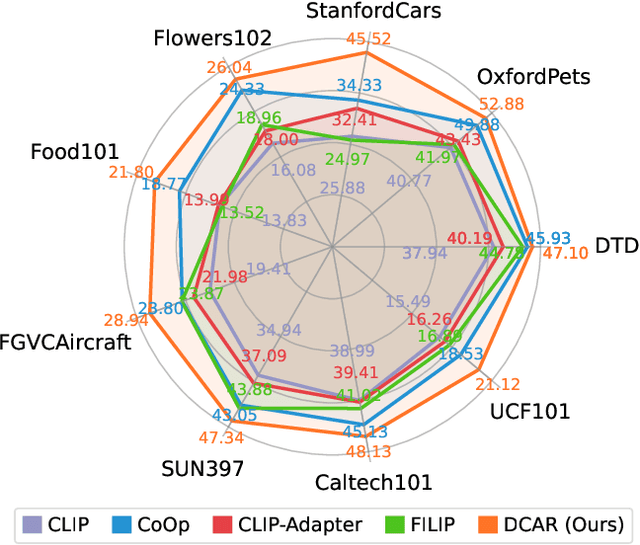
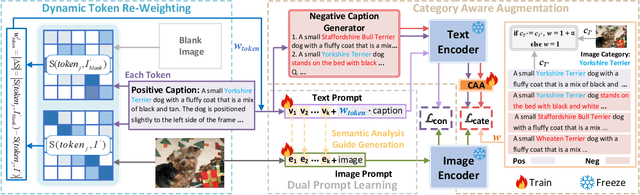
Recently, prompt learning has demonstrated remarkable success in adapting pre-trained Vision-Language Models (VLMs) to various downstream tasks such as image classification. However, its application to the downstream Image-Text Retrieval (ITR) task is more challenging. We find that the challenge lies in discriminating both fine-grained attributes and similar subcategories of the downstream data. To address this challenge, we propose Dual prompt Learning with Joint Category-Attribute Reweighting (DCAR), a novel dual-prompt learning framework to achieve precise image-text matching. The framework dynamically adjusts prompt vectors from both semantic and visual dimensions to improve the performance of CLIP on the downstream ITR task. Based on the prompt paradigm, DCAR jointly optimizes attribute and class features to enhance fine-grained representation learning. Specifically, (1) at the attribute level, it dynamically updates the weights of attribute descriptions based on text-image mutual information correlation; (2) at the category level, it introduces negative samples from multiple perspectives with category-matching weighting to learn subcategory distinctions. To validate our method, we construct the Fine-class Described Retrieval Dataset (FDRD), which serves as a challenging benchmark for ITR in downstream data domains. It covers over 1,500 downstream fine categories and 230,000 image-caption pairs with detailed attribute annotations. Extensive experiments on FDRD demonstrate that DCAR achieves state-of-the-art performance over existing baselines.
Peering into the Unknown: Active View Selection with Neural Uncertainty Maps for 3D Reconstruction
Jun 17, 2025Some perspectives naturally provide more information than others. How can an AI system determine which viewpoint offers the most valuable insight for accurate and efficient 3D object reconstruction? Active view selection (AVS) for 3D reconstruction remains a fundamental challenge in computer vision. The aim is to identify the minimal set of views that yields the most accurate 3D reconstruction. Instead of learning radiance fields, like NeRF or 3D Gaussian Splatting, from a current observation and computing uncertainty for each candidate viewpoint, we introduce a novel AVS approach guided by neural uncertainty maps predicted by a lightweight feedforward deep neural network, named UPNet. UPNet takes a single input image of a 3D object and outputs a predicted uncertainty map, representing uncertainty values across all possible candidate viewpoints. By leveraging heuristics derived from observing many natural objects and their associated uncertainty patterns, we train UPNet to learn a direct mapping from viewpoint appearance to uncertainty in the underlying volumetric representations. Next, our approach aggregates all previously predicted neural uncertainty maps to suppress redundant candidate viewpoints and effectively select the most informative one. Using these selected viewpoints, we train 3D neural rendering models and evaluate the quality of novel view synthesis against other competitive AVS methods. Remarkably, despite using half of the viewpoints than the upper bound, our method achieves comparable reconstruction accuracy. In addition, it significantly reduces computational overhead during AVS, achieving up to a 400 times speedup along with over 50\% reductions in CPU, RAM, and GPU usage compared to baseline methods. Notably, our approach generalizes effectively to AVS tasks involving novel object categories, without requiring any additional training.
From Grunts to Grammar: Emergent Language from Cooperative Foraging
May 19, 2025Early cavemen relied on gestures, vocalizations, and simple signals to coordinate, plan, avoid predators, and share resources. Today, humans collaborate using complex languages to achieve remarkable results. What drives this evolution in communication? How does language emerge, adapt, and become vital for teamwork? Understanding the origins of language remains a challenge. A leading hypothesis in linguistics and anthropology posits that language evolved to meet the ecological and social demands of early human cooperation. Language did not arise in isolation, but through shared survival goals. Inspired by this view, we investigate the emergence of language in multi-agent Foraging Games. These environments are designed to reflect the cognitive and ecological constraints believed to have influenced the evolution of communication. Agents operate in a shared grid world with only partial knowledge about other agents and the environment, and must coordinate to complete games like picking up high-value targets or executing temporally ordered actions. Using end-to-end deep reinforcement learning, agents learn both actions and communication strategies from scratch. We find that agents develop communication protocols with hallmark features of natural language: arbitrariness, interchangeability, displacement, cultural transmission, and compositionality. We quantify each property and analyze how different factors, such as population size and temporal dependencies, shape specific aspects of the emergent language. Our framework serves as a platform for studying how language can evolve from partial observability, temporal reasoning, and cooperative goals in embodied multi-agent settings. We will release all data, code, and models publicly.
Seeing Sound, Hearing Sight: Uncovering Modality Bias and Conflict of AI models in Sound Localization
May 16, 2025Imagine hearing a dog bark and turning toward the sound only to see a parked car, while the real, silent dog sits elsewhere. Such sensory conflicts test perception, yet humans reliably resolve them by prioritizing sound over misleading visuals. Despite advances in multimodal AI integrating vision and audio, little is known about how these systems handle cross-modal conflicts or whether they favor one modality. In this study, we systematically examine modality bias and conflict resolution in AI sound localization. We assess leading multimodal models and benchmark them against human performance in psychophysics experiments across six audiovisual conditions, including congruent, conflicting, and absent cues. Humans consistently outperform AI, demonstrating superior resilience to conflicting or missing visuals by relying on auditory information. In contrast, AI models often default to visual input, degrading performance to near chance levels. To address this, we finetune a state-of-the-art model using a stereo audio-image dataset generated via 3D simulations. Even with limited training data, the refined model surpasses existing benchmarks. Notably, it also mirrors human-like horizontal localization bias favoring left-right precision-likely due to the stereo audio structure reflecting human ear placement. These findings underscore how sensory input quality and system architecture shape multimodal representation accuracy.
Unforgettable Lessons from Forgettable Images: Intra-Class Memorability Matters in Computer Vision Tasks
Dec 30, 2024



We introduce intra-class memorability, where certain images within the same class are more memorable than others despite shared category characteristics. To investigate what features make one object instance more memorable than others, we design and conduct human behavior experiments, where participants are shown a series of images one at a time, and they must identify when the current item matches the item presented a few steps back in the sequence. To quantify memorability, we propose the Intra-Class Memorability score (ICMscore), a novel metric that incorporates the temporal intervals between repeated image presentations into its calculation. Our contributions open new pathways in understanding intra-class memorability by scrutinizing fine-grained visual features that result in the least and most memorable images and laying the groundwork for real-world applications in cognitive science and computer vision.
Gazing at Rewards: Eye Movements as a Lens into Human and AI Decision-Making in Hybrid Visual Foraging
Nov 14, 2024
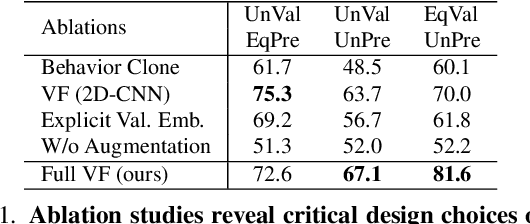


Imagine searching a collection of coins for quarters ($0.25$), dimes ($0.10$), nickels ($0.05$), and pennies ($0.01$)-a hybrid foraging task where observers look for multiple instances of multiple target types. In such tasks, how do target values and their prevalence influence foraging and eye movement behaviors (e.g., should you prioritize rare quarters or common nickels)? To explore this, we conducted human psychophysics experiments, revealing that humans are proficient reward foragers. Their eye fixations are drawn to regions with higher average rewards, fixation durations are longer on more valuable targets, and their cumulative rewards exceed chance, approaching the upper bound of optimal foragers. To probe these decision-making processes of humans, we developed a transformer-based Visual Forager (VF) model trained via reinforcement learning. Our VF model takes a series of targets, their corresponding values, and the search image as inputs, processes the images using foveated vision, and produces a sequence of eye movements along with decisions on whether to collect each fixated item. Our model outperforms all baselines, achieves cumulative rewards comparable to those of humans, and approximates human foraging behavior in eye movements and foraging biases within time-limited environments. Furthermore, stress tests on out-of-distribution tasks with novel targets, unseen values, and varying set sizes demonstrate the VF model's effective generalization. Our work offers valuable insights into the relationship between eye movements and decision-making, with our model serving as a powerful tool for further exploration of this connection. All data, code, and models will be made publicly available.
Object-Centric Temporal Consistency via Conditional Autoregressive Inductive Biases
Oct 21, 2024



Unsupervised object-centric learning from videos is a promising approach towards learning compositional representations that can be applied to various downstream tasks, such as prediction and reasoning. Recently, it was shown that pretrained Vision Transformers (ViTs) can be useful to learn object-centric representations on real-world video datasets. However, while these approaches succeed at extracting objects from the scenes, the slot-based representations fail to maintain temporal consistency across consecutive frames in a video, i.e. the mapping of objects to slots changes across the video. To address this, we introduce Conditional Autoregressive Slot Attention (CA-SA), a framework that enhances the temporal consistency of extracted object-centric representations in video-centric vision tasks. Leveraging an autoregressive prior network to condition representations on previous timesteps and a novel consistency loss function, CA-SA predicts future slot representations and imposes consistency across frames. We present qualitative and quantitative results showing that our proposed method outperforms the considered baselines on downstream tasks, such as video prediction and visual question-answering tasks.
Unsupervised Prior Learning: Discovering Categorical Pose Priors from Videos
Oct 04, 2024A prior represents a set of beliefs or assumptions about a system, aiding inference and decision-making. In this work, we introduce the challenge of unsupervised prior learning in pose estimation, where AI models learn pose priors of animate objects from videos in a self-supervised manner. These videos present objects performing various actions, providing crucial information about their keypoints and connectivity. While priors are effective in pose estimation, acquiring them can be difficult. We propose a novel method, named Pose Prior Learner (PPL), to learn general pose priors applicable to any object category. PPL uses a hierarchical memory to store compositional parts of prototypical poses, from which we distill a general pose prior. This prior enhances pose estimation accuracy through template transformation and image reconstruction. PPL learns meaningful pose priors without any additional human annotations or interventions, outperforming competitive baselines on both human and animal pose estimation datasets. Notably, our experimental results reveal the effectiveness of PPL using learnt priors for pose estimation on occluded images. Through iterative inference, PPL leverages priors to refine estimated poses, regressing them to any prototypical poses stored in memory. Our code, model, and data will be publicly available.