 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaPoint: Unlocking Precise Spatial Control in Agentic Visual Generation
Jun 03, 2026Generative visual models fundamentally struggle with precise spatial control. This arises from a core disconnect: models can process textual descriptions of space but cannot directly map numerical coordinates onto the 2D image canvas. We introduce MetaPoint, a method that bridges this gap by representing a continuous 2D coordinate as a single, special token. Crucially, MetaPoint requires no new architectural components; it directly leverages the model's inherent positional encoding schemes to interpret these coordinates, treating our token as a virtual point on the canvas. This lightweight approach enables pixel-level control of an object's position with one token or its bounding box with two, all without requiring architectural changes or bespoke attention masking. The MetaPoint tokens are designed to be compositional, serving as spatial primitives. This allows a planner agent to decompose a high-level user request into a structured sequence of primitives for the generator. By providing a simple, precise, and scalable building block for spatial control, MetaPoint unlocks more powerful compositional generative agents and enables intuitive, interactive editing systems.
ClawMark: A Living-World Benchmark for Multi-Turn, Multi-Day, Multimodal Coworker Agents
Apr 26, 2026Language-model agents are increasingly used as persistent coworkers that assist users across multiple working days. During such workflows, the surrounding environment may change independently of the agent: new emails arrive, calendar entries shift, knowledge-base records are updated, and evidence appears across images, scanned PDFs, audio, video, and spreadsheets. Existing benchmarks do not adequately evaluate this setting because they typically run within a single static episode and remain largely text-centric. We introduce \bench{}, a benchmark for coworker agents built around multi-turn multi-day tasks, a stateful sandboxed service environment whose state evolves between turns, and rule-based verification. The current release contains 100 tasks across 13 professional scenarios, executed against five stateful sandboxed services (filesystem, email, calendar, knowledge base, spreadsheet) and scored by 1537 deterministic Python checkers over post-execution service state; no LLM-as-judge is invoked during scoring. We benchmark seven frontier agent systems. The strongest model reaches 75.8 weighted score, but the best strict Task Success is only 20.0\%, indicating that partial progress is common while complete end-to-end workflow completion remains rare. Turn-level analysis shows that performance drops after the first exogenous environment update, highlighting adaptation to changing state as a key open challenge. We release the benchmark, evaluation harness, and construction pipeline to support reproducible coworker-agent evaluation.
Unified Video Editing with Temporal Reasoner
Dec 08, 2025Existing video editing methods face a critical trade-off: expert models offer precision but rely on task-specific priors like masks, hindering unification; conversely, unified temporal in-context learning models are mask-free but lack explicit spatial cues, leading to weak instruction-to-region mapping and imprecise localization. To resolve this conflict, we propose VideoCoF, a novel Chain-of-Frames approach inspired by Chain-of-Thought reasoning. VideoCoF enforces a ``see, reason, then edit" procedure by compelling the video diffusion model to first predict reasoning tokens (edit-region latents) before generating the target video tokens. This explicit reasoning step removes the need for user-provided masks while achieving precise instruction-to-region alignment and fine-grained video editing. Furthermore, we introduce a RoPE alignment strategy that leverages these reasoning tokens to ensure motion alignment and enable length extrapolation beyond the training duration. We demonstrate that with a minimal data cost of only 50k video pairs, VideoCoF achieves state-of-the-art performance on VideoCoF-Bench, validating the efficiency and effectiveness of our approach. Our code, weight, data are available at https://github.com/knightyxp/VideoCoF.
Reconstruction Alignment Improves Unified Multimodal Models
Sep 08, 2025Unified multimodal models (UMMs) unify visual understanding and generation within a single architecture. However, conventional training relies on image-text pairs (or sequences) whose captions are typically sparse and miss fine-grained visual details--even when they use hundreds of words to describe a simple image. We introduce Reconstruction Alignment (RecA), a resource-efficient post-training method that leverages visual understanding encoder embeddings as dense "text prompts," providing rich supervision without captions. Concretely, RecA conditions a UMM on its own visual understanding embeddings and optimizes it to reconstruct the input image with a self-supervised reconstruction loss, thereby realigning understanding and generation. Despite its simplicity, RecA is broadly applicable: across autoregressive, masked-autoregressive, and diffusion-based UMMs, it consistently improves generation and editing fidelity. With only 27 GPU-hours, post-training with RecA substantially improves image generation performance on GenEval (0.73$\rightarrow$0.90) and DPGBench (80.93$\rightarrow$88.15), while also boosting editing benchmarks (ImgEdit 3.38$\rightarrow$3.75, GEdit 6.94$\rightarrow$7.25). Notably, RecA surpasses much larger open-source models and applies broadly across diverse UMM architectures, establishing it as an efficient and general post-training alignment strategy for UMMs
Beyond Scaling Law: A Data-Efficient Distillation Framework for Reasoning
Aug 13, 2025Large language models (LLMs) demonstrate remarkable reasoning capabilities in tasks such as algorithmic coding and mathematical problem-solving. Recent methods have improved reasoning through expanded corpus and multistage training combining reinforcement learning and supervised fine-tuning. Although some methods suggest that small but targeted dataset can incentivize reasoning via only distillation, a reasoning scaling laws is still taking shape, increasing computational costs. To address this, we propose a data-efficient distillation framework (DED) that optimizes the Pareto frontier of reasoning distillation. Inspired by the on-policy learning and diverse roll-out strategies of reinforcement learning, the key idea of our approach is threefold: (1) We identify that benchmark scores alone do not determine an effective teacher model. Through comprehensive comparisons of leading reasoning LLMs, we develop a method to select an optimal teacher model. (2) While scaling distillation can enhance reasoning, it often degrades out-of-domain performance. A carefully curated, smaller corpus achieves a balanced trade-off between in-domain and out-of-domain capabilities. (3) Diverse reasoning trajectories encourage the student model to develop robust reasoning skills. We validate our method through evaluations on mathematical reasoning (AIME 2024/2025, MATH-500) and code generation (LiveCodeBench), achieving state-of-the-art results with only 0.8k carefully curated examples, bypassing the need for extensive scaling. Our systematic analysis demonstrates that DED outperforms existing methods by considering factors beyond superficial hardness, token length, or teacher model capability. This work offers a practical and efficient pathway to advanced reasoning while preserving general capabilities.
Seeing Sound, Hearing Sight: Uncovering Modality Bias and Conflict of AI models in Sound Localization
May 16, 2025Imagine hearing a dog bark and turning toward the sound only to see a parked car, while the real, silent dog sits elsewhere. Such sensory conflicts test perception, yet humans reliably resolve them by prioritizing sound over misleading visuals. Despite advances in multimodal AI integrating vision and audio, little is known about how these systems handle cross-modal conflicts or whether they favor one modality. In this study, we systematically examine modality bias and conflict resolution in AI sound localization. We assess leading multimodal models and benchmark them against human performance in psychophysics experiments across six audiovisual conditions, including congruent, conflicting, and absent cues. Humans consistently outperform AI, demonstrating superior resilience to conflicting or missing visuals by relying on auditory information. In contrast, AI models often default to visual input, degrading performance to near chance levels. To address this, we finetune a state-of-the-art model using a stereo audio-image dataset generated via 3D simulations. Even with limited training data, the refined model surpasses existing benchmarks. Notably, it also mirrors human-like horizontal localization bias favoring left-right precision-likely due to the stereo audio structure reflecting human ear placement. These findings underscore how sensory input quality and system architecture shape multimodal representation accuracy.
In-Context Edit: Enabling Instructional Image Editing with In-Context Generation in Large Scale Diffusion Transformer
Apr 29, 2025Instruction-based image editing enables robust image modification via natural language prompts, yet current methods face a precision-efficiency tradeoff. Fine-tuning methods demand significant computational resources and large datasets, while training-free techniques struggle with instruction comprehension and edit quality. We resolve this dilemma by leveraging large-scale Diffusion Transformer (DiT)' enhanced generation capacity and native contextual awareness. Our solution introduces three contributions: (1) an in-context editing framework for zero-shot instruction compliance using in-context prompting, avoiding structural changes; (2) a LoRA-MoE hybrid tuning strategy that enhances flexibility with efficient adaptation and dynamic expert routing, without extensive retraining; and (3) an early filter inference-time scaling method using vision-language models (VLMs) to select better initial noise early, improving edit quality. Extensive evaluations demonstrate our method's superiority: it outperforms state-of-the-art approaches while requiring only 0.5% training data and 1% trainable parameters compared to conventional baselines. This work establishes a new paradigm that enables high-precision yet efficient instruction-guided editing. Codes and demos can be found in https://river-zhang.github.io/ICEdit-gh-pages/.
3DIS-FLUX: simple and efficient multi-instance generation with DiT rendering
Jan 09, 2025The growing demand for controllable outputs in text-to-image generation has driven significant advancements in multi-instance generation (MIG), enabling users to define both instance layouts and attributes. Currently, the state-of-the-art methods in MIG are primarily adapter-based. However, these methods necessitate retraining a new adapter each time a more advanced model is released, resulting in significant resource consumption. A methodology named Depth-Driven Decoupled Instance Synthesis (3DIS) has been introduced, which decouples MIG into two distinct phases: 1) depth-based scene construction and 2) detail rendering with widely pre-trained depth control models. The 3DIS method requires adapter training solely during the scene construction phase, while enabling various models to perform training-free detail rendering. Initially, 3DIS focused on rendering techniques utilizing U-Net architectures such as SD1.5, SD2, and SDXL, without exploring the potential of recent DiT-based models like FLUX. In this paper, we present 3DIS-FLUX, an extension of the 3DIS framework that integrates the FLUX model for enhanced rendering capabilities. Specifically, we employ the FLUX.1-Depth-dev model for depth map controlled image generation and introduce a detail renderer that manipulates the Attention Mask in FLUX's Joint Attention mechanism based on layout information. This approach allows for the precise rendering of fine-grained attributes of each instance. Our experimental results indicate that 3DIS-FLUX, leveraging the FLUX model, outperforms the original 3DIS method, which utilized SD2 and SDXL, and surpasses current state-of-the-art adapter-based methods in terms of both performance and image quality. Project Page: https://limuloo.github.io/3DIS/.
3DIS: Depth-Driven Decoupled Instance Synthesis for Text-to-Image Generation
Oct 16, 2024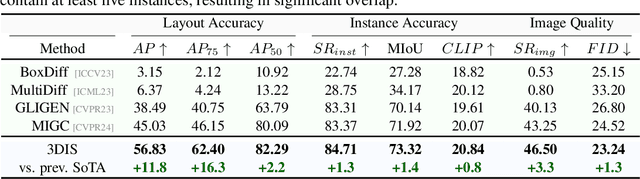
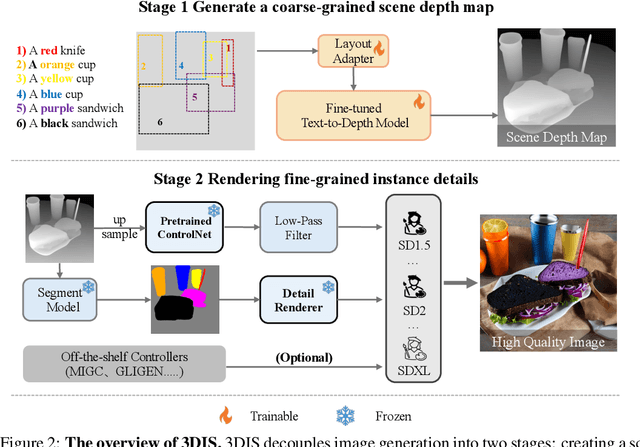

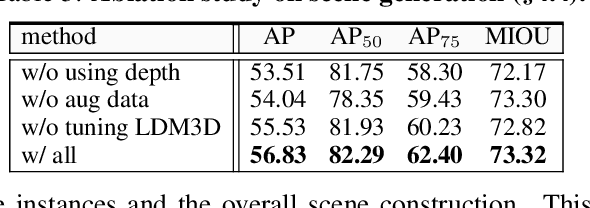
The increasing demand for controllable outputs in text-to-image generation has spurred advancements in multi-instance generation (MIG), allowing users to define both instance layouts and attributes. However, unlike image-conditional generation methods such as ControlNet, MIG techniques have not been widely adopted in state-of-the-art models like SD2 and SDXL, primarily due to the challenge of building robust renderers that simultaneously handle instance positioning and attribute rendering. In this paper, we introduce Depth-Driven Decoupled Instance Synthesis (3DIS), a novel framework that decouples the MIG process into two stages: (i) generating a coarse scene depth map for accurate instance positioning and scene composition, and (ii) rendering fine-grained attributes using pre-trained ControlNet on any foundational model, without additional training. Our 3DIS framework integrates a custom adapter into LDM3D for precise depth-based layouts and employs a finetuning-free method for enhanced instance-level attribute rendering. Extensive experiments on COCO-Position and COCO-MIG benchmarks demonstrate that 3DIS significantly outperforms existing methods in both layout precision and attribute rendering. Notably, 3DIS offers seamless compatibility with diverse foundational models, providing a robust, adaptable solution for advanced multi-instance generation. The code is available at: https://github.com/limuloo/3DIS.