 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDreamRenderer: Taming Multi-Instance Attribute Control in Large-Scale Text-to-Image Models
Mar 17, 2025Image-conditioned generation methods, such as depth- and canny-conditioned approaches, have demonstrated remarkable abilities for precise image synthesis. However, existing models still struggle to accurately control the content of multiple instances (or regions). Even state-of-the-art models like FLUX and 3DIS face challenges, such as attribute leakage between instances, which limits user control. To address these issues, we introduce DreamRenderer, a training-free approach built upon the FLUX model. DreamRenderer enables users to control the content of each instance via bounding boxes or masks, while ensuring overall visual harmony. We propose two key innovations: 1) Bridge Image Tokens for Hard Text Attribute Binding, which uses replicated image tokens as bridge tokens to ensure that T5 text embeddings, pre-trained solely on text data, bind the correct visual attributes for each instance during Joint Attention; 2) Hard Image Attribute Binding applied only to vital layers. Through our analysis of FLUX, we identify the critical layers responsible for instance attribute rendering and apply Hard Image Attribute Binding only in these layers, using soft binding in the others. This approach ensures precise control while preserving image quality. Evaluations on the COCO-POS and COCO-MIG benchmarks demonstrate that DreamRenderer improves the Image Success Ratio by 17.7% over FLUX and enhances the performance of layout-to-image models like GLIGEN and 3DIS by up to 26.8%. Project Page: https://limuloo.github.io/DreamRenderer/.
3DIS-FLUX: simple and efficient multi-instance generation with DiT rendering
Jan 09, 2025The growing demand for controllable outputs in text-to-image generation has driven significant advancements in multi-instance generation (MIG), enabling users to define both instance layouts and attributes. Currently, the state-of-the-art methods in MIG are primarily adapter-based. However, these methods necessitate retraining a new adapter each time a more advanced model is released, resulting in significant resource consumption. A methodology named Depth-Driven Decoupled Instance Synthesis (3DIS) has been introduced, which decouples MIG into two distinct phases: 1) depth-based scene construction and 2) detail rendering with widely pre-trained depth control models. The 3DIS method requires adapter training solely during the scene construction phase, while enabling various models to perform training-free detail rendering. Initially, 3DIS focused on rendering techniques utilizing U-Net architectures such as SD1.5, SD2, and SDXL, without exploring the potential of recent DiT-based models like FLUX. In this paper, we present 3DIS-FLUX, an extension of the 3DIS framework that integrates the FLUX model for enhanced rendering capabilities. Specifically, we employ the FLUX.1-Depth-dev model for depth map controlled image generation and introduce a detail renderer that manipulates the Attention Mask in FLUX's Joint Attention mechanism based on layout information. This approach allows for the precise rendering of fine-grained attributes of each instance. Our experimental results indicate that 3DIS-FLUX, leveraging the FLUX model, outperforms the original 3DIS method, which utilized SD2 and SDXL, and surpasses current state-of-the-art adapter-based methods in terms of both performance and image quality. Project Page: https://limuloo.github.io/3DIS/.
3DIS: Depth-Driven Decoupled Instance Synthesis for Text-to-Image Generation
Oct 16, 2024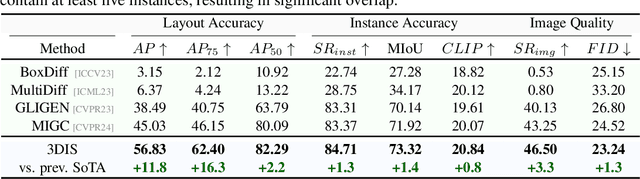
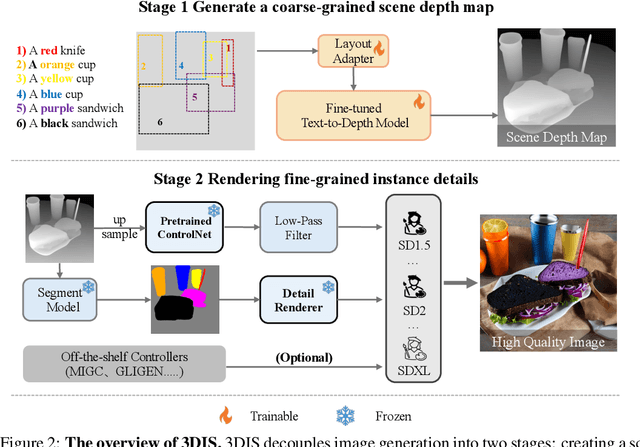

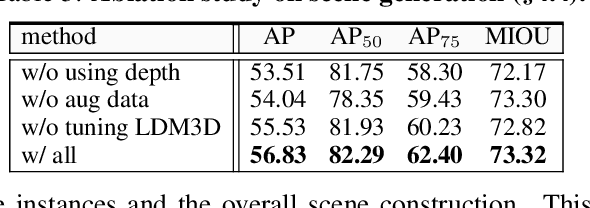
The increasing demand for controllable outputs in text-to-image generation has spurred advancements in multi-instance generation (MIG), allowing users to define both instance layouts and attributes. However, unlike image-conditional generation methods such as ControlNet, MIG techniques have not been widely adopted in state-of-the-art models like SD2 and SDXL, primarily due to the challenge of building robust renderers that simultaneously handle instance positioning and attribute rendering. In this paper, we introduce Depth-Driven Decoupled Instance Synthesis (3DIS), a novel framework that decouples the MIG process into two stages: (i) generating a coarse scene depth map for accurate instance positioning and scene composition, and (ii) rendering fine-grained attributes using pre-trained ControlNet on any foundational model, without additional training. Our 3DIS framework integrates a custom adapter into LDM3D for precise depth-based layouts and employs a finetuning-free method for enhanced instance-level attribute rendering. Extensive experiments on COCO-Position and COCO-MIG benchmarks demonstrate that 3DIS significantly outperforms existing methods in both layout precision and attribute rendering. Notably, 3DIS offers seamless compatibility with diverse foundational models, providing a robust, adaptable solution for advanced multi-instance generation. The code is available at: https://github.com/limuloo/3DIS.
MIGC++: Advanced Multi-Instance Generation Controller for Image Synthesis
Jul 02, 2024



We introduce the Multi-Instance Generation (MIG) task, which focuses on generating multiple instances within a single image, each accurately placed at predefined positions with attributes such as category, color, and shape, strictly following user specifications. MIG faces three main challenges: avoiding attribute leakage between instances, supporting diverse instance descriptions, and maintaining consistency in iterative generation. To address attribute leakage, we propose the Multi-Instance Generation Controller (MIGC). MIGC generates multiple instances through a divide-and-conquer strategy, breaking down multi-instance shading into single-instance tasks with singular attributes, later integrated. To provide more types of instance descriptions, we developed MIGC++. MIGC++ allows attribute control through text \& images and position control through boxes \& masks. Lastly, we introduced the Consistent-MIG algorithm to enhance the iterative MIG ability of MIGC and MIGC++. This algorithm ensures consistency in unmodified regions during the addition, deletion, or modification of instances, and preserves the identity of instances when their attributes are changed. We introduce the COCO-MIG and Multimodal-MIG benchmarks to evaluate these methods. Extensive experiments on these benchmarks, along with the COCO-Position benchmark and DrawBench, demonstrate that our methods substantially outperform existing techniques, maintaining precise control over aspects including position, attribute, and quantity. Project page: https://github.com/limuloo/MIGC.
MIGC: Multi-Instance Generation Controller for Text-to-Image Synthesis
Feb 08, 2024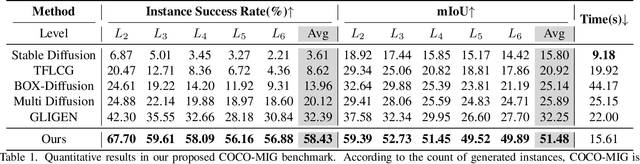



We present a Multi-Instance Generation (MIG) task, simultaneously generating multiple instances with diverse controls in one image. Given a set of predefined coordinates and their corresponding descriptions, the task is to ensure that generated instances are accurately at the designated locations and that all instances' attributes adhere to their corresponding description. This broadens the scope of current research on Single-instance generation, elevating it to a more versatile and practical dimension. Inspired by the idea of divide and conquer, we introduce an innovative approach named Multi-Instance Generation Controller (MIGC) to address the challenges of the MIG task. Initially, we break down the MIG task into several subtasks, each involving the shading of a single instance. To ensure precise shading for each instance, we introduce an instance enhancement attention mechanism. Lastly, we aggregate all the shaded instances to provide the necessary information for accurately generating multiple instances in stable diffusion (SD). To evaluate how well generation models perform on the MIG task, we provide a COCO-MIG benchmark along with an evaluation pipeline. Extensive experiments were conducted on the proposed COCO-MIG benchmark, as well as on various commonly used benchmarks. The evaluation results illustrate the exceptional control capabilities of our model in terms of quantity, position, attribute, and interaction.
Pyramid Diffusion Models For Low-light Image Enhancement
May 17, 2023Recovering noise-covered details from low-light images is challenging, and the results given by previous methods leave room for improvement. Recent diffusion models show realistic and detailed image generation through a sequence of denoising refinements and motivate us to introduce them to low-light image enhancement for recovering realistic details. However, we found two problems when doing this, i.e., 1) diffusion models keep constant resolution in one reverse process, which limits the speed; 2) diffusion models sometimes result in global degradation (e.g., RGB shift). To address the above problems, this paper proposes a Pyramid Diffusion model (PyDiff) for low-light image enhancement. PyDiff uses a novel pyramid diffusion method to perform sampling in a pyramid resolution style (i.e., progressively increasing resolution in one reverse process). Pyramid diffusion makes PyDiff much faster than vanilla diffusion models and introduces no performance degradation. Furthermore, PyDiff uses a global corrector to alleviate the global degradation that may occur in the reverse process, significantly improving the performance and making the training of diffusion models easier with little additional computational consumption. Extensive experiments on popular benchmarks show that PyDiff achieves superior performance and efficiency. Moreover, PyDiff can generalize well to unseen noise and illumination distributions.