 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransNormal: Dense Visual Semantics for Diffusion-based Transparent Object Normal Estimation
Jan 31, 2026Monocular normal estimation for transparent objects is critical for laboratory automation, yet it remains challenging due to complex light refraction and reflection. These optical properties often lead to catastrophic failures in conventional depth and normal sensors, hindering the deployment of embodied AI in scientific environments. We propose TransNormal, a novel framework that adapts pre-trained diffusion priors for single-step normal regression. To handle the lack of texture in transparent surfaces, TransNormal integrates dense visual semantics from DINOv3 via a cross-attention mechanism, providing strong geometric cues. Furthermore, we employ a multi-task learning objective and wavelet-based regularization to ensure the preservation of fine-grained structural details. To support this task, we introduce TransNormal-Synthetic, a physics-based dataset with high-fidelity normal maps for transparent labware. Extensive experiments demonstrate that TransNormal significantly outperforms state-of-the-art methods: on the ClearGrasp benchmark, it reduces mean error by 24.4% and improves 11.25° accuracy by 22.8%; on ClearPose, it achieves a 15.2% reduction in mean error. The code and dataset will be made publicly available at https://longxiang-ai.github.io/TransNormal.
Prismatic World Model: Learning Compositional Dynamics for Planning in Hybrid Systems
Dec 09, 2025Model-based planning in robotic domains is fundamentally challenged by the hybrid nature of physical dynamics, where continuous motion is punctuated by discrete events such as contacts and impacts. Conventional latent world models typically employ monolithic neural networks that enforce global continuity, inevitably over-smoothing the distinct dynamic modes (e.g., sticking vs. sliding, flight vs. stance). For a planner, this smoothing results in catastrophic compounding errors during long-horizon lookaheads, rendering the search process unreliable at physical boundaries. To address this, we introduce the Prismatic World Model (PRISM-WM), a structured architecture designed to decompose complex hybrid dynamics into composable primitives. PRISM-WM leverages a context-aware Mixture-of-Experts (MoE) framework where a gating mechanism implicitly identifies the current physical mode, and specialized experts predict the associated transition dynamics. We further introduce a latent orthogonalization objective to ensure expert diversity, effectively preventing mode collapse. By accurately modeling the sharp mode transitions in system dynamics, PRISM-WM significantly reduces rollout drift. Extensive experiments on challenging continuous control benchmarks, including high-dimensional humanoids and diverse multi-task settings, demonstrate that PRISM-WM provides a superior high-fidelity substrate for trajectory optimization algorithms (e.g., TD-MPC), proving its potential as a powerful foundational model for next-generation model-based agents.
TSGS: Improving Gaussian Splatting for Transparent Surface Reconstruction via Normal and De-lighting Priors
Apr 17, 2025Reconstructing transparent surfaces is essential for tasks such as robotic manipulation in labs, yet it poses a significant challenge for 3D reconstruction techniques like 3D Gaussian Splatting (3DGS). These methods often encounter a transparency-depth dilemma, where the pursuit of photorealistic rendering through standard $\alpha$-blending undermines geometric precision, resulting in considerable depth estimation errors for transparent materials. To address this issue, we introduce Transparent Surface Gaussian Splatting (TSGS), a new framework that separates geometry learning from appearance refinement. In the geometry learning stage, TSGS focuses on geometry by using specular-suppressed inputs to accurately represent surfaces. In the second stage, TSGS improves visual fidelity through anisotropic specular modeling, crucially maintaining the established opacity to ensure geometric accuracy. To enhance depth inference, TSGS employs a first-surface depth extraction method. This technique uses a sliding window over $\alpha$-blending weights to pinpoint the most likely surface location and calculates a robust weighted average depth. To evaluate the transparent surface reconstruction task under realistic conditions, we collect a TransLab dataset that includes complex transparent laboratory glassware. Extensive experiments on TransLab show that TSGS achieves accurate geometric reconstruction and realistic rendering of transparent objects simultaneously within the efficient 3DGS framework. Specifically, TSGS significantly surpasses current leading methods, achieving a 37.3% reduction in chamfer distance and an 8.0% improvement in F1 score compared to the top baseline. The code and dataset will be released at https://longxiang-ai.github.io/TSGS/.
DreamRenderer: Taming Multi-Instance Attribute Control in Large-Scale Text-to-Image Models
Mar 17, 2025Image-conditioned generation methods, such as depth- and canny-conditioned approaches, have demonstrated remarkable abilities for precise image synthesis. However, existing models still struggle to accurately control the content of multiple instances (or regions). Even state-of-the-art models like FLUX and 3DIS face challenges, such as attribute leakage between instances, which limits user control. To address these issues, we introduce DreamRenderer, a training-free approach built upon the FLUX model. DreamRenderer enables users to control the content of each instance via bounding boxes or masks, while ensuring overall visual harmony. We propose two key innovations: 1) Bridge Image Tokens for Hard Text Attribute Binding, which uses replicated image tokens as bridge tokens to ensure that T5 text embeddings, pre-trained solely on text data, bind the correct visual attributes for each instance during Joint Attention; 2) Hard Image Attribute Binding applied only to vital layers. Through our analysis of FLUX, we identify the critical layers responsible for instance attribute rendering and apply Hard Image Attribute Binding only in these layers, using soft binding in the others. This approach ensures precise control while preserving image quality. Evaluations on the COCO-POS and COCO-MIG benchmarks demonstrate that DreamRenderer improves the Image Success Ratio by 17.7% over FLUX and enhances the performance of layout-to-image models like GLIGEN and 3DIS by up to 26.8%. Project Page: https://limuloo.github.io/DreamRenderer/.
Iterative Tree Analysis for Medical Critics
Jan 18, 2025Large Language Models (LLMs) have been widely adopted across various domains, yet their application in the medical field poses unique challenges, particularly concerning the generation of hallucinations. Hallucinations in open-ended long medical text manifest as misleading critical claims, which are difficult to verify due to two reasons. First, critical claims are often deeply entangled within the text and cannot be extracted based solely on surface-level presentation. Second, verifying these claims is challenging because surface-level token-based retrieval often lacks precise or specific evidence, leaving the claims unverifiable without deeper mechanism-based analysis. In this paper, we introduce a novel method termed Iterative Tree Analysis (ITA) for medical critics. ITA is designed to extract implicit claims from long medical texts and verify each claim through an iterative and adaptive tree-like reasoning process. This process involves a combination of top-down task decomposition and bottom-up evidence consolidation, enabling precise verification of complex medical claims through detailed mechanism-level reasoning. Our extensive experiments demonstrate that ITA significantly outperforms previous methods in detecting factual inaccuracies in complex medical text verification tasks by 10%. Additionally, we will release a comprehensive test set to the public, aiming to foster further advancements in research within this domain.
Heterogeneous Subgraph Network with Prompt Learning for Interpretable Depression Detection on Social Media
Jul 12, 2024



Massive social media data can reflect people's authentic thoughts, emotions, communication, etc., and therefore can be analyzed for early detection of mental health problems such as depression. Existing works about early depression detection on social media lacked interpretability and neglected the heterogeneity of social media data. Furthermore, they overlooked the global interaction among users. To address these issues, we develop a novel method that leverages a Heterogeneous Subgraph Network with Prompt Learning(HSNPL) and contrastive learning mechanisms. Specifically, prompt learning is employed to map users' implicit psychological symbols with excellent interpretability while deep semantic and diverse behavioral features are incorporated by a heterogeneous information network. Then, the heterogeneous graph network with a dual attention mechanism is constructed to model the relationships among heterogeneous social information at the feature level. Furthermore, the heterogeneous subgraph network integrating subgraph attention and self-supervised contrastive learning is developed to explore complicated interactions among users and groups at the user level. Extensive experimental results demonstrate that our proposed method significantly outperforms state-of-the-art methods for depression detection on social media.
CUPID: Contextual Understanding of Prompt-conditioned Image Distributions
Jun 11, 2024We present CUPID: a visualization method for the contextual understanding of prompt-conditioned image distributions. CUPID targets the visual analysis of distributions produced by modern text-to-image generative models, wherein a user can specify a scene via natural language, and the model generates a set of images, each intended to satisfy the user's description. CUPID is designed to help understand the resulting distribution, using contextual cues to facilitate analysis: objects mentioned in the prompt, novel, synthesized objects not explicitly mentioned, and their potential relationships. Central to CUPID is a novel method for visualizing high-dimensional distributions, wherein contextualized embeddings of objects, those found within images, are mapped to a low-dimensional space via density-based embeddings. We show how such embeddings allows one to discover salient styles of objects within a distribution, as well as identify anomalous, or rare, object styles. Moreover, we introduce conditional density embeddings, whereby conditioning on a given object allows one to compare object dependencies within the distribution. We employ CUPID for analyzing image distributions produced by large-scale diffusion models, where our experimental results offer insights on language misunderstanding from such models and biases in object composition, while also providing an interface for discovery of typical, or rare, synthesized scenes.
Graphical Perception of Saliency-based Model Explanations
Jun 11, 2024In recent years, considerable work has been devoted to explaining predictive, deep learning-based models, and in turn how to evaluate explanations. An important class of evaluation methods are ones that are human-centered, which typically require the communication of explanations through visualizations. And while visualization plays a critical role in perceiving and understanding model explanations, how visualization design impacts human perception of explanations remains poorly understood. In this work, we study the graphical perception of model explanations, specifically, saliency-based explanations for visual recognition models. We propose an experimental design to investigate how human perception is influenced by visualization design, wherein we study the task of alignment assessment, or whether a saliency map aligns with an object in an image. Our findings show that factors related to visualization design decisions, the type of alignment, and qualities of the saliency map all play important roles in how humans perceive saliency-based visual explanations.
Human101: Training 100+FPS Human Gaussians in 100s from 1 View
Dec 23, 2023Reconstructing the human body from single-view videos plays a pivotal role in the virtual reality domain. One prevalent application scenario necessitates the rapid reconstruction of high-fidelity 3D digital humans while simultaneously ensuring real-time rendering and interaction. Existing methods often struggle to fulfill both requirements. In this paper, we introduce Human101, a novel framework adept at producing high-fidelity dynamic 3D human reconstructions from 1-view videos by training 3D Gaussians in 100 seconds and rendering in 100+ FPS. Our method leverages the strengths of 3D Gaussian Splatting, which provides an explicit and efficient representation of 3D humans. Standing apart from prior NeRF-based pipelines, Human101 ingeniously applies a Human-centric Forward Gaussian Animation method to deform the parameters of 3D Gaussians, thereby enhancing rendering speed (i.e., rendering 1024-resolution images at an impressive 60+ FPS and rendering 512-resolution images at 100+ FPS). Experimental results indicate that our approach substantially eclipses current methods, clocking up to a 10 times surge in frames per second and delivering comparable or superior rendering quality. Code and demos will be released at https://github.com/longxiang-ai/Human101.
UnProjection: Leveraging Inverse-Projections for Visual Analytics of High-Dimensional Data
Nov 02, 2021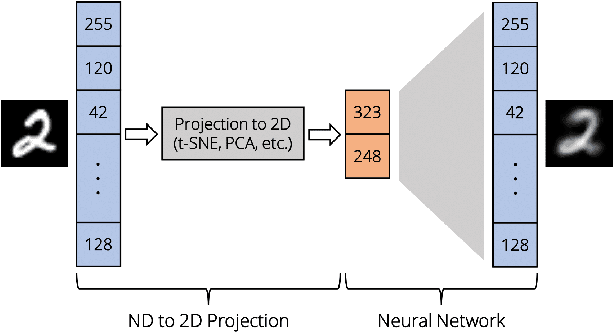
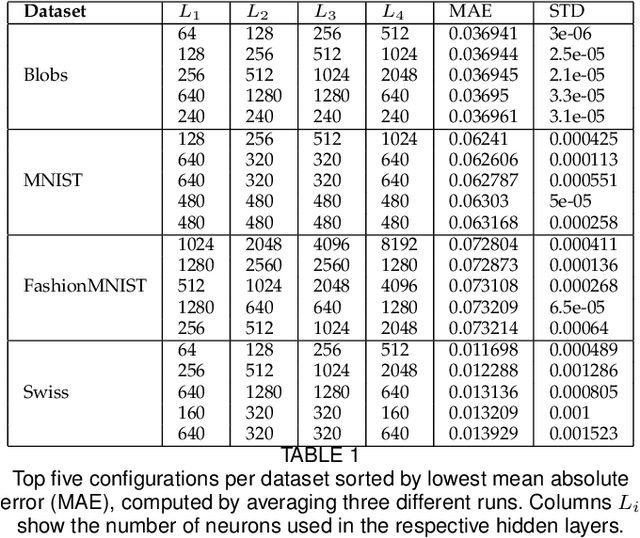

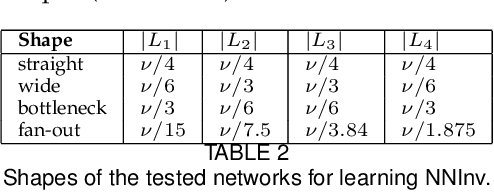
Projection techniques are often used to visualize high-dimensional data, allowing users to better understand the overall structure of multi-dimensional spaces on a 2D screen. Although many such methods exist, comparably little work has been done on generalizable methods of inverse-projection -- the process of mapping the projected points, or more generally, the projection space back to the original high-dimensional space. In this paper we present NNInv, a deep learning technique with the ability to approximate the inverse of any projection or mapping. NNInv learns to reconstruct high-dimensional data from any arbitrary point on a 2D projection space, giving users the ability to interact with the learned high-dimensional representation in a visual analytics system. We provide an analysis of the parameter space of NNInv, and offer guidance in selecting these parameters. We extend validation of the effectiveness of NNInv through a series of quantitative and qualitative analyses. We then demonstrate the method's utility by applying it to three visualization tasks: interactive instance interpolation, classifier agreement, and gradient visualization.