 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Open-Source Benchmark and Baseline for Multi-temporal Referring Segmentation
May 31, 2026Large Vision-Language Models (LVLMs) have shown strong visual understanding and language-guided grounding abilities, yet their capacity for multi-temporal visual reasoning remains underexplored. To bridge this gap, we introduce \textbf{Multi-temporal Referring Segmentation (MTRS)}, a new task that aims to segment language-described temporal changes from multi-temporal images. MTRS extends conventional referring segmentation and change detection by jointly requiring temporal correspondence reasoning, language grounding, and pixel-level mask prediction. We propose \textbf{CRAFT-Agent}, an automated data construction pipeline with human auditing, and build \textbf{MTRefSeg-21K}, the first MTRS benchmark, containing 21K high-quality multi-temporal image-text-mask triplets across diverse scenes, viewpoints, and domains. Benchmarking a broad set of VLM- and LVLM-based models reveals that direct inference performs poorly, while task-specific fine-tuning remains limited. To address this, we propose \textbf{MTRefSeg-R1}, a change-aware LVLM framework trained with a two-stage strategy. It first learns general temporal-change perception from 20K vision-only bi-temporal samples, and is then fine-tuned on MTRefSeg-21K for fine-grained language-guided temporal localization. MTRefSeg-R1 explicitly models cross-temporal visual differences, aligns language instructions with temporal variations, and predicts referred change masks. Extensive experiments show that MTRefSeg-R1 achieves strong and often superior performance compared with existing LVLM baselines, demonstrating the challenge and potential of MTRS.
MedMamba: Multi-View State Space Models with Adaptive Graph Learning for Medical Time Series Classification
May 24, 2026Medical time series are central to healthcare, enabling continuous monitoring and supporting timely clinical decisions. Despite recent progress, existing methods struggle to jointly model local-global dynamics and handle nonstationarities like baseline drift, while often failing to capture latent channel interactions. To address these challenges, we propose MedMamba, an end-to-end architecture that integrates state space models with domain-specific inductive biases. Specifically, MedMamba first employs multi-scale convolutional embeddings to capture discriminative local morphology. Second, to mitigate nonstationarity, we introduce a tri-branch differential state space encoder that processes raw, temporal-difference, and frequency-domain views, fusing them to emphasize informative patterns while suppressing drift. Furthermore, to uncover latent channel correlations, we design a spatial graph Mamba module that learns a directed dependency structure regularized toward sparsity and acyclicity, which obviates the need for predefined graphs. Extensive experiments on five real-world datasets demonstrate that MedMamba achieves state-of-the-art performance while maintaining linear computational complexity, and ablation studies validate each component's contribution.Code is available at https://github.com/zhangda1018/MedMamba.
Prototype-Based Low Altitude UAV Semantic Segmentation
Apr 02, 2026Semantic segmentation of low-altitude UAV imagery presents unique challenges due to extreme scale variations, complex object boundaries, and limited computational resources on edge devices. Existing transformer-based segmentation methods achieve remarkable performance but incur high computational overhead, while lightweight approaches struggle to capture fine-grained details in high-resolution aerial scenes. To address these limitations, we propose PBSeg, an efficient prototype-based segmentation framework tailored for UAV applications. PBSeg introduces a novel prototype-based cross-attention (PBCA) that exploits feature redundancy to reduce computational complexity while maintaining segmentation quality. The framework incorporates an efficient multi-scale feature extraction module that combines deformable convolutions (DConv) with context-aware modulation (CAM) to capture both local details and global semantics. Experiments on two challenging UAV datasets demonstrate the effectiveness of the proposed approach. PBSeg achieves 71.86\% mIoU on UAVid and 80.92\% mIoU on UDD6, establishing competitive performance while maintaining computational efficiency. Code is available at https://github.com/zhangda1018/PBSeg.
Boosting Quantitive and Spatial Awareness for Zero-Shot Object Counting
Mar 17, 2026Zero-shot object counting (ZSOC) aims to enumerate objects of arbitrary categories specified by text descriptions without requiring visual exemplars. However, existing methods often treat counting as a coarse retrieval task, suffering from a lack of fine-grained quantity awareness. Furthermore, they frequently exhibit spatial insensitivity and degraded generalization due to feature space distortion during model adaptation.To address these challenges, we present \textbf{QICA}, a novel framework that synergizes \underline{q}uantity percept\underline{i}on with robust spatial \underline{c}ast \underline{a}ggregation. Specifically, we introduce a Synergistic Prompting Strategy (\textbf{SPS}) that adapts vision and language encoders through numerically conditioned prompts, bridging the gap between semantic recognition and quantitative reasoning. To mitigate feature distortion, we propose a Cost Aggregation Decoder (\textbf{CAD}) that operates directly on vision-text similarity maps. By refining these maps through spatial aggregation, CAD prevents overfitting while preserving zero-shot transferability. Additionally, a multi-level quantity alignment loss ($\mathcal{L}_{MQA}$) is employed to enforce numerical consistency across the entire pipeline. Extensive experiments on FSC-147 demonstrate competitive performance, while zero-shot evaluation on CARPK and ShanghaiTech-A validates superior generalization to unseen domains.
IntroSVG: Learning from Rendering Feedback for Text-to-SVG Generation via an Introspective Generator-Critic Framework
Mar 10, 2026Scalable Vector Graphics (SVG) are central to digital design due to their inherent scalability and editability. Despite significant advancements in content generation enabled by Visual Language Models (VLMs), existing text-to-SVG generation methods are limited by a core challenge: the autoregressive training process does not incorporate visual perception of the final rendered image, which fundamentally constrains generation quality. To address this limitation, we propose an Introspective SVG Generation Framework (IntroSVG). At its core, the framework instantiates a unified VLM that operates in a closed loop, assuming dual roles of both generator and critic. Specifically, through Supervised Fine-Tuning (SFT), the model learns to draft SVGs and to provide feedback on their rendered outputs; moreover, we systematically convert early-stage failures into high-quality error-correction training data, thereby enhancing model robustness. Subsequently, we leverage a high-capacity teacher VLM to construct a preference dataset and further align the generator's policy through Direct Preference Optimization (DPO). During inference, the optimized generator and critic operate collaboratively in an iterative "generate-review-refine" cycle, starting from imperfect intermediate drafts to autonomously improve output quality. Experimental results demonstrate that our method achieves state-of-the-art performance across several key evaluation metrics, generating SVGs with more complex structures, stronger semantic alignment, and greater editability. These results corroborate the effectiveness of incorporating explicit visual feedback into the generation loop.
FusAD: Time-Frequency Fusion with Adaptive Denoising for General Time Series Analysis
Dec 16, 2025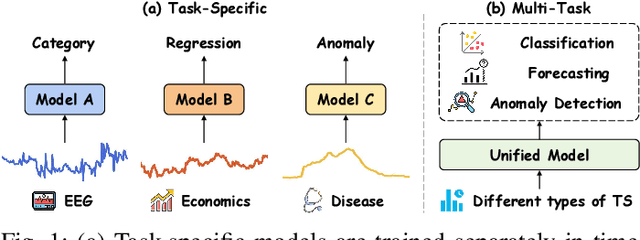
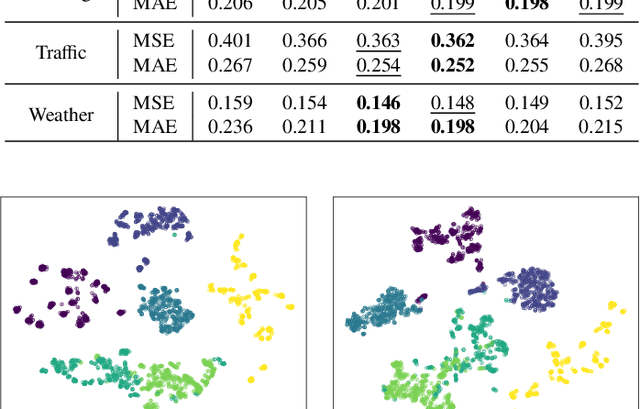


Time series analysis plays a vital role in fields such as finance, healthcare, industry, and meteorology, underpinning key tasks including classification, forecasting, and anomaly detection. Although deep learning models have achieved remarkable progress in these areas in recent years, constructing an efficient, multi-task compatible, and generalizable unified framework for time series analysis remains a significant challenge. Existing approaches are often tailored to single tasks or specific data types, making it difficult to simultaneously handle multi-task modeling and effectively integrate information across diverse time series types. Moreover, real-world data are often affected by noise, complex frequency components, and multi-scale dynamic patterns, which further complicate robust feature extraction and analysis. To ameliorate these challenges, we propose FusAD, a unified analysis framework designed for diverse time series tasks. FusAD features an adaptive time-frequency fusion mechanism, integrating both Fourier and Wavelet transforms to efficiently capture global-local and multi-scale dynamic features. With an adaptive denoising mechanism, FusAD automatically senses and filters various types of noise, highlighting crucial sequence variations and enabling robust feature extraction in complex environments. In addition, the framework integrates a general information fusion and decoding structure, combined with masked pre-training, to promote efficient learning and transfer of multi-granularity representations. Extensive experiments demonstrate that FusAD consistently outperforms state-of-the-art models on mainstream time series benchmarks for classification, forecasting, and anomaly detection tasks, while maintaining high efficiency and scalability. Code is available at https://github.com/zhangda1018/FusAD.
Exploring the Underwater World Segmentation without Extra Training
Nov 11, 2025Accurate segmentation of marine organisms is vital for biodiversity monitoring and ecological assessment, yet existing datasets and models remain largely limited to terrestrial scenes. To bridge this gap, we introduce \textbf{AquaOV255}, the first large-scale and fine-grained underwater segmentation dataset containing 255 categories and over 20K images, covering diverse categories for open-vocabulary (OV) evaluation. Furthermore, we establish the first underwater OV segmentation benchmark, \textbf{UOVSBench}, by integrating AquaOV255 with five additional underwater datasets to enable comprehensive evaluation. Alongside, we present \textbf{Earth2Ocean}, a training-free OV segmentation framework that transfers terrestrial vision--language models (VLMs) to underwater domains without any additional underwater training. Earth2Ocean consists of two core components: a Geometric-guided Visual Mask Generator (\textbf{GMG}) that refines visual features via self-similarity geometric priors for local structure perception, and a Category-visual Semantic Alignment (\textbf{CSA}) module that enhances text embeddings through multimodal large language model reasoning and scene-aware template construction. Extensive experiments on the UOVSBench benchmark demonstrate that Earth2Ocean achieves significant performance improvement on average while maintaining efficient inference.
Robust and Efficient Quantum Reservoir Computing with Discrete Time Crystal
Aug 21, 2025The rapid development of machine learning and quantum computing has placed quantum machine learning at the forefront of research. However, existing quantum machine learning algorithms based on quantum variational algorithms face challenges in trainability and noise robustness. In order to address these challenges, we introduce a gradient-free, noise-robust quantum reservoir computing algorithm that harnesses discrete time crystal dynamics as a reservoir. We first calibrate the memory, nonlinear, and information scrambling capacities of the quantum reservoir, revealing their correlation with dynamical phases and non-equilibrium phase transitions. We then apply the algorithm to the binary classification task and establish a comparative quantum kernel advantage. For ten-class classification, both noisy simulations and experimental results on superconducting quantum processors match ideal simulations, demonstrating the enhanced accuracy with increasing system size and confirming the topological noise robustness. Our work presents the first experimental demonstration of quantum reservoir computing for image classification based on digital quantum simulation. It establishes the correlation between quantum many-body non-equilibrium phase transitions and quantum machine learning performance, providing new design principles for quantum reservoir computing and broader quantum machine learning algorithms in the NISQ era.
FGAseg: Fine-Grained Pixel-Text Alignment for Open-Vocabulary Semantic Segmentation
Jan 03, 2025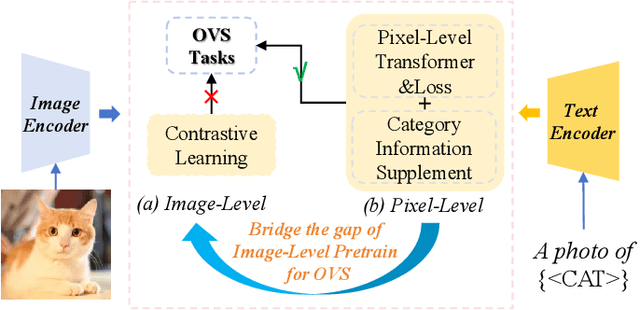
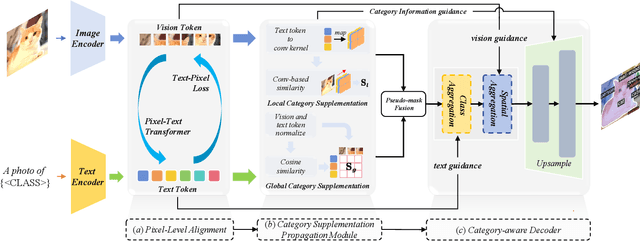
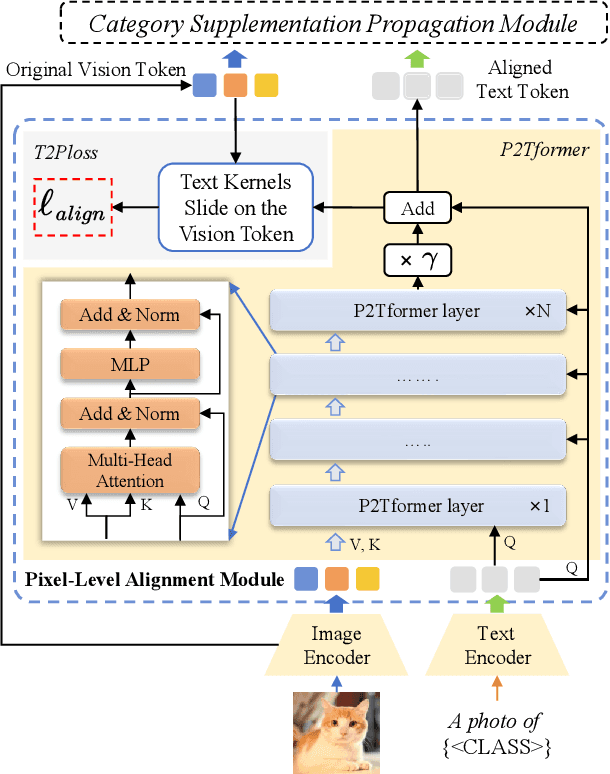
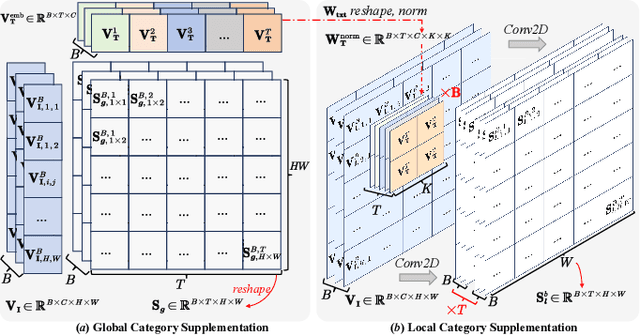
Open-vocabulary segmentation aims to identify and segment specific regions and objects based on text-based descriptions. A common solution is to leverage powerful vision-language models (VLMs), such as CLIP, to bridge the gap between vision and text information. However, VLMs are typically pretrained for image-level vision-text alignment, focusing on global semantic features. In contrast, segmentation tasks require fine-grained pixel-level alignment and detailed category boundary information, which VLMs alone cannot provide. As a result, information extracted directly from VLMs can't meet the requirements of segmentation tasks. To address this limitation, we propose FGAseg, a model designed for fine-grained pixel-text alignment and category boundary supplementation. The core of FGAseg is a Pixel-Level Alignment module that employs a cross-modal attention mechanism and a text-pixel alignment loss to refine the coarse-grained alignment from CLIP, achieving finer-grained pixel-text semantic alignment. Additionally, to enrich category boundary information, we introduce the alignment matrices as optimizable pseudo-masks during forward propagation and propose Category Information Supplementation module. These pseudo-masks, derived from cosine and convolutional similarity, provide essential global and local boundary information between different categories. By combining these two strategies, FGAseg effectively enhances pixel-level alignment and category boundary information, addressing key challenges in open-vocabulary segmentation. Extensive experiments demonstrate that FGAseg outperforms existing methods on open-vocabulary semantic segmentation benchmarks.
Quantum-inspired Interpretable Deep Learning Architecture for Text Sentiment Analysis
Aug 15, 2024Text has become the predominant form of communication on social media, embedding a wealth of emotional nuances. Consequently, the extraction of emotional information from text is of paramount importance. Despite previous research making some progress, existing text sentiment analysis models still face challenges in integrating diverse semantic information and lack interpretability. To address these issues, we propose a quantum-inspired deep learning architecture that combines fundamental principles of quantum mechanics (QM principles) with deep learning models for text sentiment analysis. Specifically, we analyze the commonalities between text representation and QM principles to design a quantum-inspired text representation method and further develop a quantum-inspired text embedding layer. Additionally, we design a feature extraction layer based on long short-term memory (LSTM) networks and self-attention mechanisms (SAMs). Finally, we calculate the text density matrix using the quantum complex numbers principle and apply 2D-convolution neural networks (CNNs) for feature condensation and dimensionality reduction. Through a series of visualization, comparative, and ablation experiments, we demonstrate that our model not only shows significant advantages in accuracy and efficiency compared to previous related models but also achieves a certain level of interpretability by integrating QM principles. Our code is available at QISA.