 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeU3M: Unbiased Multiscale Modal Fusion Model for Multimodal Semantic Segmentation
Paper and Code
May 24, 2024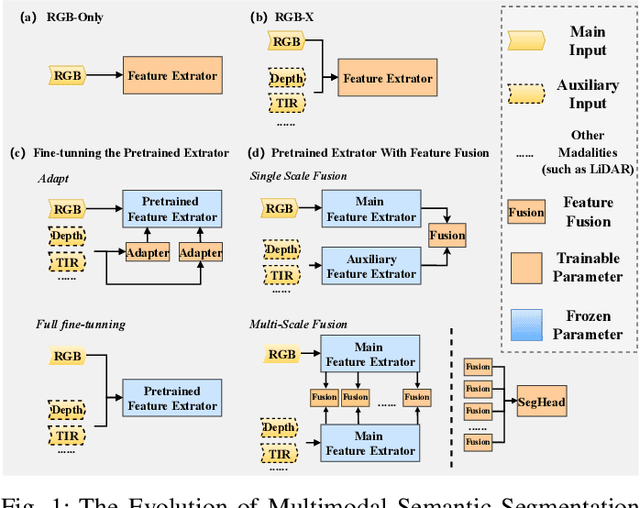
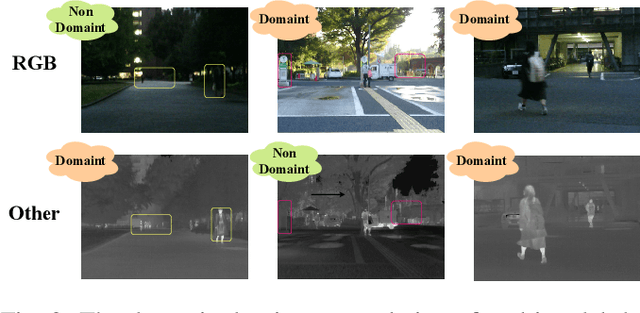
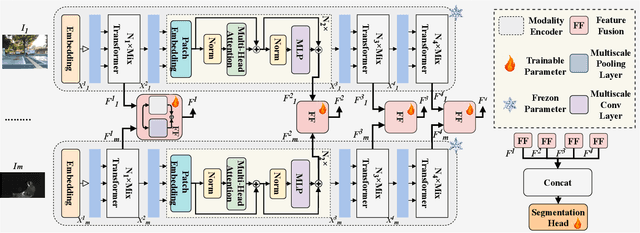
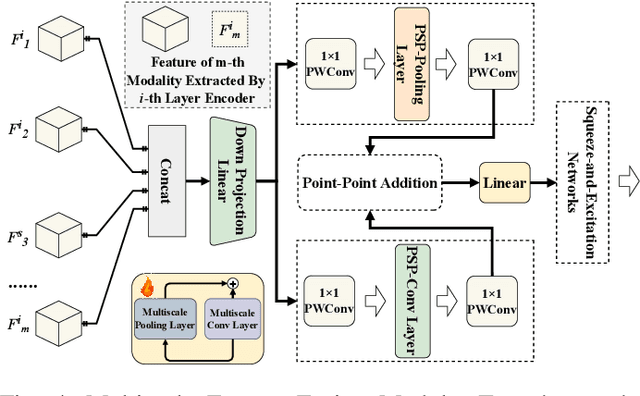
Multimodal semantic segmentation is a pivotal component of computer vision and typically surpasses unimodal methods by utilizing rich information set from various sources.Current models frequently adopt modality-specific frameworks that inherently biases toward certain modalities. Although these biases might be advantageous in specific situations, they generally limit the adaptability of the models across different multimodal contexts, thereby potentially impairing performance. To address this issue, we leverage the inherent capabilities of the model itself to discover the optimal equilibrium in multimodal fusion and introduce U3M: An Unbiased Multiscale Modal Fusion Model for Multimodal Semantic Segmentation. Specifically, this method involves an unbiased integration of multimodal visual data. Additionally, we employ feature fusion at multiple scales to ensure the effective extraction and integration of both global and local features. Experimental results demonstrate that our approach achieves superior performance across multiple datasets, verifing its efficacy in enhancing the robustness and versatility of semantic segmentation in diverse settings. Our code is available at U3M-multimodal-semantic-segmentation.