 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusAD: Time-Frequency Fusion with Adaptive Denoising for General Time Series Analysis
Dec 16, 2025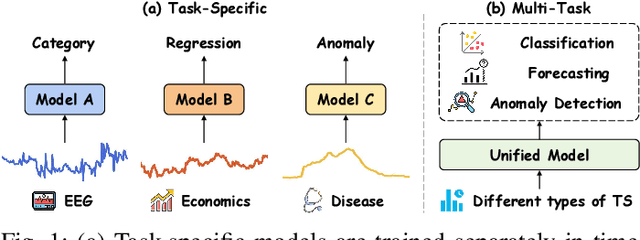
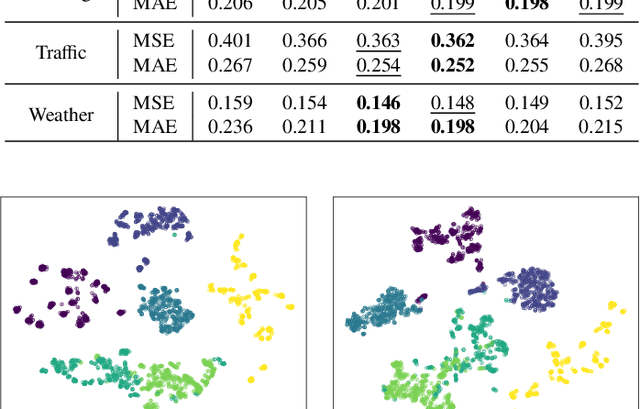


Time series analysis plays a vital role in fields such as finance, healthcare, industry, and meteorology, underpinning key tasks including classification, forecasting, and anomaly detection. Although deep learning models have achieved remarkable progress in these areas in recent years, constructing an efficient, multi-task compatible, and generalizable unified framework for time series analysis remains a significant challenge. Existing approaches are often tailored to single tasks or specific data types, making it difficult to simultaneously handle multi-task modeling and effectively integrate information across diverse time series types. Moreover, real-world data are often affected by noise, complex frequency components, and multi-scale dynamic patterns, which further complicate robust feature extraction and analysis. To ameliorate these challenges, we propose FusAD, a unified analysis framework designed for diverse time series tasks. FusAD features an adaptive time-frequency fusion mechanism, integrating both Fourier and Wavelet transforms to efficiently capture global-local and multi-scale dynamic features. With an adaptive denoising mechanism, FusAD automatically senses and filters various types of noise, highlighting crucial sequence variations and enabling robust feature extraction in complex environments. In addition, the framework integrates a general information fusion and decoding structure, combined with masked pre-training, to promote efficient learning and transfer of multi-granularity representations. Extensive experiments demonstrate that FusAD consistently outperforms state-of-the-art models on mainstream time series benchmarks for classification, forecasting, and anomaly detection tasks, while maintaining high efficiency and scalability. Code is available at https://github.com/zhangda1018/FusAD.
Exploring the Underwater World Segmentation without Extra Training
Nov 11, 2025Accurate segmentation of marine organisms is vital for biodiversity monitoring and ecological assessment, yet existing datasets and models remain largely limited to terrestrial scenes. To bridge this gap, we introduce \textbf{AquaOV255}, the first large-scale and fine-grained underwater segmentation dataset containing 255 categories and over 20K images, covering diverse categories for open-vocabulary (OV) evaluation. Furthermore, we establish the first underwater OV segmentation benchmark, \textbf{UOVSBench}, by integrating AquaOV255 with five additional underwater datasets to enable comprehensive evaluation. Alongside, we present \textbf{Earth2Ocean}, a training-free OV segmentation framework that transfers terrestrial vision--language models (VLMs) to underwater domains without any additional underwater training. Earth2Ocean consists of two core components: a Geometric-guided Visual Mask Generator (\textbf{GMG}) that refines visual features via self-similarity geometric priors for local structure perception, and a Category-visual Semantic Alignment (\textbf{CSA}) module that enhances text embeddings through multimodal large language model reasoning and scene-aware template construction. Extensive experiments on the UOVSBench benchmark demonstrate that Earth2Ocean achieves significant performance improvement on average while maintaining efficient inference.
AutoCBT: An Autonomous Multi-agent Framework for Cognitive Behavioral Therapy in Psychological Counseling
Jan 16, 2025



Traditional in-person psychological counseling remains primarily niche, often chosen by individuals with psychological issues, while online automated counseling offers a potential solution for those hesitant to seek help due to feelings of shame. Cognitive Behavioral Therapy (CBT) is an essential and widely used approach in psychological counseling. The advent of large language models (LLMs) and agent technology enables automatic CBT diagnosis and treatment. However, current LLM-based CBT systems use agents with a fixed structure, limiting their self-optimization capabilities, or providing hollow, unhelpful suggestions due to redundant response patterns. In this work, we utilize Quora-like and YiXinLi single-round consultation models to build a general agent framework that generates high-quality responses for single-turn psychological consultation scenarios. We use a bilingual dataset to evaluate the quality of single-response consultations generated by each framework. Then, we incorporate dynamic routing and supervisory mechanisms inspired by real psychological counseling to construct a CBT-oriented autonomous multi-agent framework, demonstrating its general applicability. Experimental results indicate that AutoCBT can provide higher-quality automated psychological counseling services.
FGAseg: Fine-Grained Pixel-Text Alignment for Open-Vocabulary Semantic Segmentation
Jan 03, 2025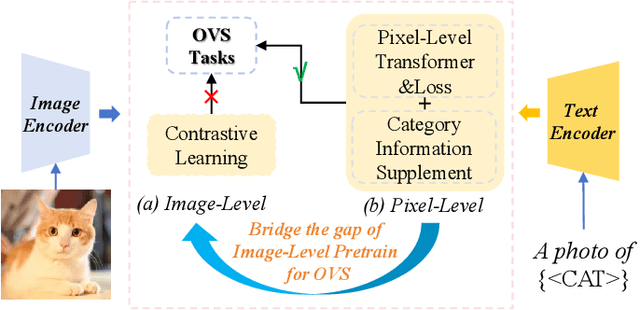
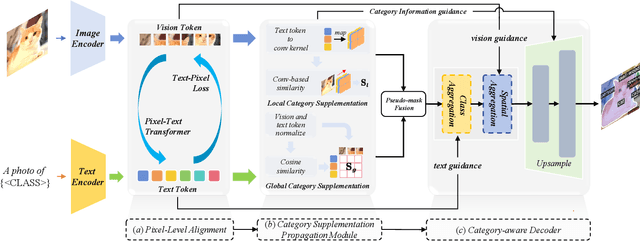
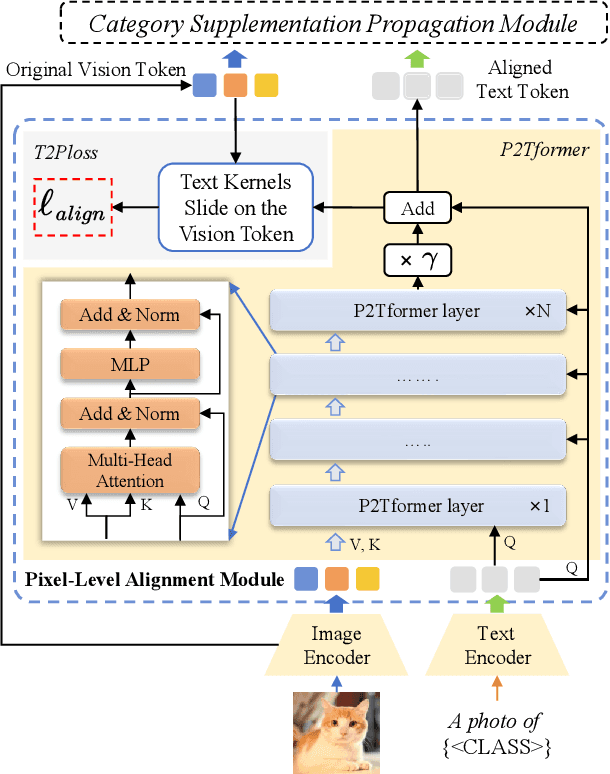
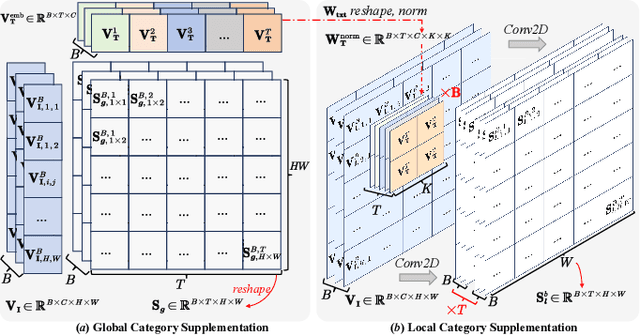
Open-vocabulary segmentation aims to identify and segment specific regions and objects based on text-based descriptions. A common solution is to leverage powerful vision-language models (VLMs), such as CLIP, to bridge the gap between vision and text information. However, VLMs are typically pretrained for image-level vision-text alignment, focusing on global semantic features. In contrast, segmentation tasks require fine-grained pixel-level alignment and detailed category boundary information, which VLMs alone cannot provide. As a result, information extracted directly from VLMs can't meet the requirements of segmentation tasks. To address this limitation, we propose FGAseg, a model designed for fine-grained pixel-text alignment and category boundary supplementation. The core of FGAseg is a Pixel-Level Alignment module that employs a cross-modal attention mechanism and a text-pixel alignment loss to refine the coarse-grained alignment from CLIP, achieving finer-grained pixel-text semantic alignment. Additionally, to enrich category boundary information, we introduce the alignment matrices as optimizable pseudo-masks during forward propagation and propose Category Information Supplementation module. These pseudo-masks, derived from cosine and convolutional similarity, provide essential global and local boundary information between different categories. By combining these two strategies, FGAseg effectively enhances pixel-level alignment and category boundary information, addressing key challenges in open-vocabulary segmentation. Extensive experiments demonstrate that FGAseg outperforms existing methods on open-vocabulary semantic segmentation benchmarks.
Generalize Your Face Forgery Detectors: An Insertable Adaptation Module Is All You Need
Dec 30, 2024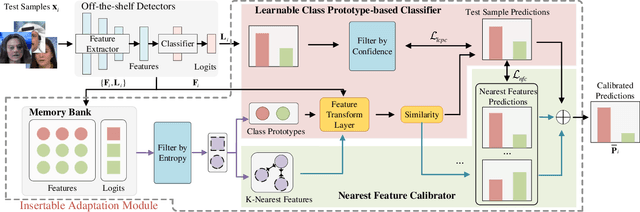
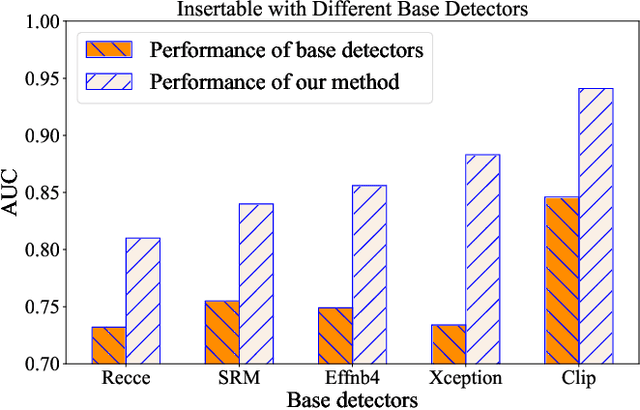
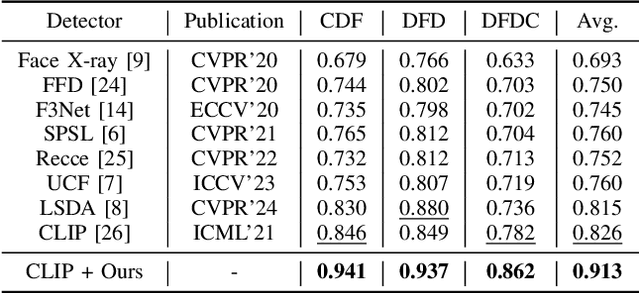

A plethora of face forgery detectors exist to tackle facial deepfake risks. However, their practical application is hindered by the challenge of generalizing to forgeries unseen during the training stage. To this end, we introduce an insertable adaptation module that can adapt a trained off-the-shelf detector using only online unlabeled test data, without requiring modifications to the architecture or training process. Specifically, we first present a learnable class prototype-based classifier that generates predictions from the revised features and prototypes, enabling effective handling of various forgery clues and domain gaps during online testing. Additionally, we propose a nearest feature calibrator to further improve prediction accuracy and reduce the impact of noisy pseudo-labels during self-training. Experiments across multiple datasets show that our module achieves superior generalization compared to state-of-the-art methods. Moreover, it functions as a plug-and-play component that can be combined with various detectors to enhance the overall performance.
Boosting the Targeted Transferability of Adversarial Examples via Salient Region & Weighted Feature Drop
Nov 11, 2024



Deep neural networks can be vulnerable to adversarially crafted examples, presenting significant risks to practical applications. A prevalent approach for adversarial attacks relies on the transferability of adversarial examples, which are generated from a substitute model and leveraged to attack unknown black-box models. Despite various proposals aimed at improving transferability, the success of these attacks in targeted black-box scenarios is often hindered by the tendency for adversarial examples to overfit to the surrogate models. In this paper, we introduce a novel framework based on Salient region & Weighted Feature Drop (SWFD) designed to enhance the targeted transferability of adversarial examples. Drawing from the observation that examples with higher transferability exhibit smoother distributions in the deep-layer outputs, we propose the weighted feature drop mechanism to modulate activation values according to weights scaled by norm distribution, effectively addressing the overfitting issue when generating adversarial examples. Additionally, by leveraging salient region within the image to construct auxiliary images, our method enables the adversarial example's features to be transferred to the target category in a model-agnostic manner, thereby enhancing the transferability. Comprehensive experiments confirm that our approach outperforms state-of-the-art methods across diverse configurations. On average, the proposed SWFD raises the attack success rate for normally trained models and robust models by 16.31% and 7.06% respectively.
Quantum-inspired Interpretable Deep Learning Architecture for Text Sentiment Analysis
Aug 15, 2024Text has become the predominant form of communication on social media, embedding a wealth of emotional nuances. Consequently, the extraction of emotional information from text is of paramount importance. Despite previous research making some progress, existing text sentiment analysis models still face challenges in integrating diverse semantic information and lack interpretability. To address these issues, we propose a quantum-inspired deep learning architecture that combines fundamental principles of quantum mechanics (QM principles) with deep learning models for text sentiment analysis. Specifically, we analyze the commonalities between text representation and QM principles to design a quantum-inspired text representation method and further develop a quantum-inspired text embedding layer. Additionally, we design a feature extraction layer based on long short-term memory (LSTM) networks and self-attention mechanisms (SAMs). Finally, we calculate the text density matrix using the quantum complex numbers principle and apply 2D-convolution neural networks (CNNs) for feature condensation and dimensionality reduction. Through a series of visualization, comparative, and ablation experiments, we demonstrate that our model not only shows significant advantages in accuracy and efficiency compared to previous related models but also achieves a certain level of interpretability by integrating QM principles. Our code is available at QISA.
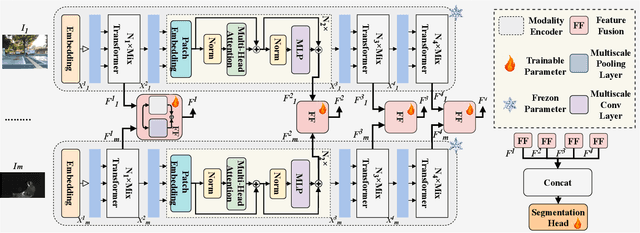
StitchFusion: Weaving Any Visual Modalities to Enhance Multimodal Semantic Segmentation
Aug 02, 2024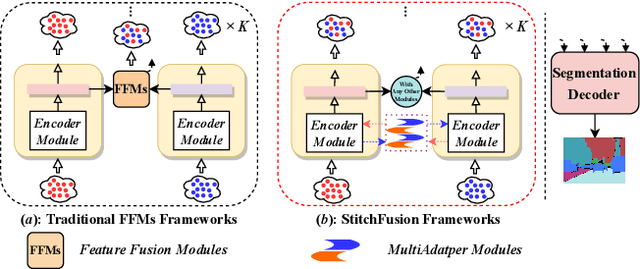
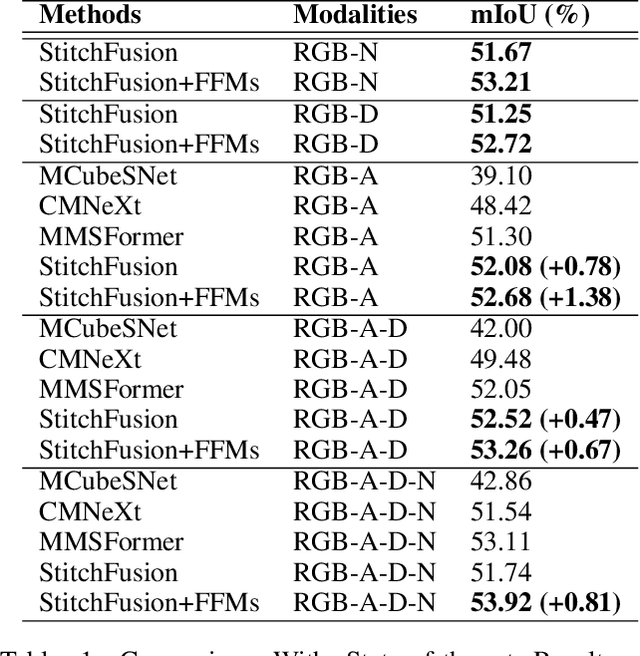
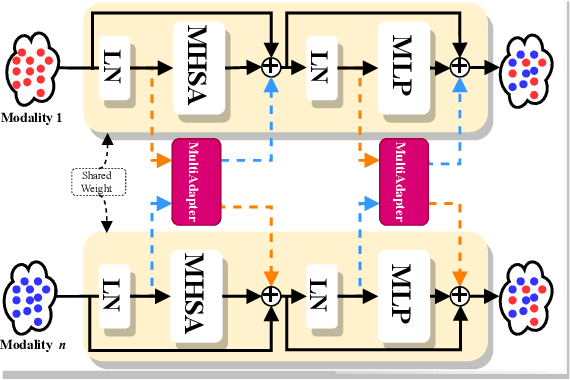
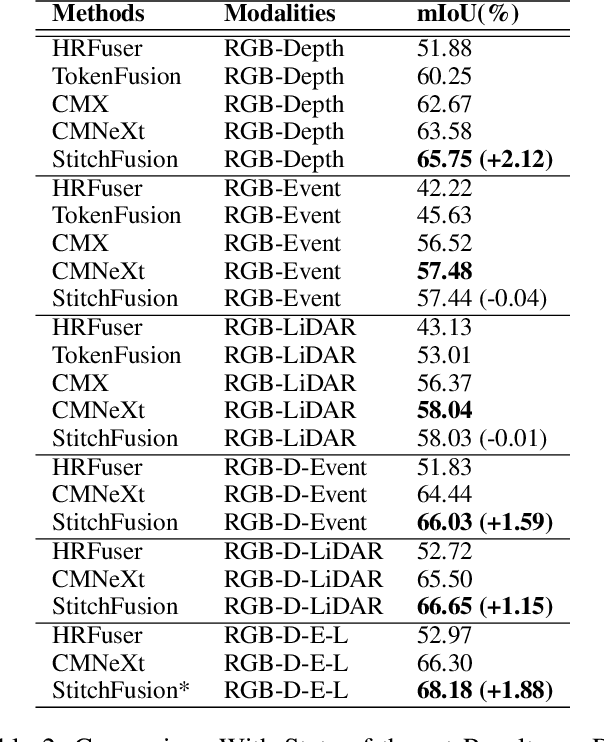
Multimodal semantic segmentation shows significant potential for enhancing segmentation accuracy in complex scenes. However, current methods often incorporate specialized feature fusion modules tailored to specific modalities, thereby restricting input flexibility and increasing the number of training parameters. To address these challenges, we propose StitchFusion, a straightforward yet effective modal fusion framework that integrates large-scale pre-trained models directly as encoders and feature fusers. This approach facilitates comprehensive multi-modal and multi-scale feature fusion, accommodating any visual modal inputs. Specifically, Our framework achieves modal integration during encoding by sharing multi-modal visual information. To enhance information exchange across modalities, we introduce a multi-directional adapter module (MultiAdapter) to enable cross-modal information transfer during encoding. By leveraging MultiAdapter to propagate multi-scale information across pre-trained encoders during the encoding process, StitchFusion achieves multi-modal visual information integration during encoding. Extensive comparative experiments demonstrate that our model achieves state-of-the-art performance on four multi-modal segmentation datasets with minimal additional parameters. Furthermore, the experimental integration of MultiAdapter with existing Feature Fusion Modules (FFMs) highlights their complementary nature. Our code is available at StitchFusion_repo.
U3M: Unbiased Multiscale Modal Fusion Model for Multimodal Semantic Segmentation
May 24, 2024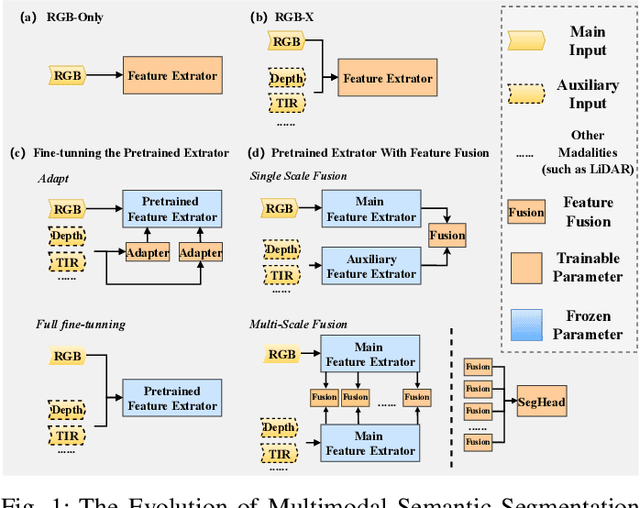
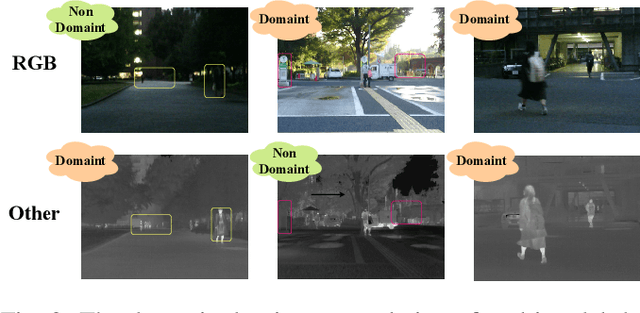
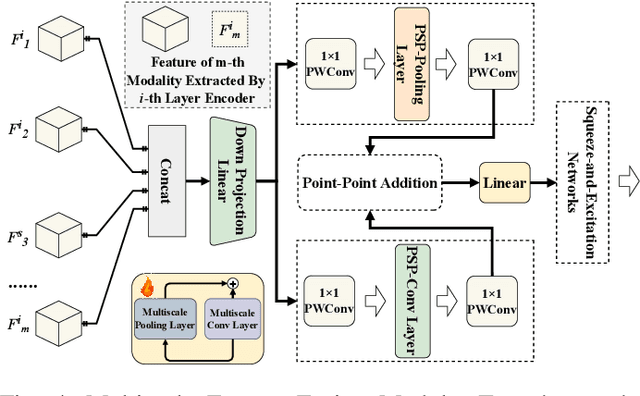
Multimodal semantic segmentation is a pivotal component of computer vision and typically surpasses unimodal methods by utilizing rich information set from various sources.Current models frequently adopt modality-specific frameworks that inherently biases toward certain modalities. Although these biases might be advantageous in specific situations, they generally limit the adaptability of the models across different multimodal contexts, thereby potentially impairing performance. To address this issue, we leverage the inherent capabilities of the model itself to discover the optimal equilibrium in multimodal fusion and introduce U3M: An Unbiased Multiscale Modal Fusion Model for Multimodal Semantic Segmentation. Specifically, this method involves an unbiased integration of multimodal visual data. Additionally, we employ feature fusion at multiple scales to ensure the effective extraction and integration of both global and local features. Experimental results demonstrate that our approach achieves superior performance across multiple datasets, verifing its efficacy in enhancing the robustness and versatility of semantic segmentation in diverse settings. Our code is available at U3M-multimodal-semantic-segmentation.
CREST: Cross-modal Resonance through Evidential Deep Learning for Enhanced Zero-Shot Learning
Apr 15, 2024



Zero-shot learning (ZSL) enables the recognition of novel classes by leveraging semantic knowledge transfer from known to unknown categories. This knowledge, typically encapsulated in attribute descriptions, aids in identifying class-specific visual features, thus facilitating visual-semantic alignment and improving ZSL performance. However, real-world challenges such as distribution imbalances and attribute co-occurrence among instances often hinder the discernment of local variances in images, a problem exacerbated by the scarcity of fine-grained, region-specific attribute annotations. Moreover, the variability in visual presentation within categories can also skew attribute-category associations. In response, we propose a bidirectional cross-modal ZSL approach CREST. It begins by extracting representations for attribute and visual localization and employs Evidential Deep Learning (EDL) to measure underlying epistemic uncertainty, thereby enhancing the model's resilience against hard negatives. CREST incorporates dual learning pathways, focusing on both visual-category and attribute-category alignments, to ensure robust correlation between latent and observable spaces. Moreover, we introduce an uncertainty-informed cross-modal fusion technique to refine visual-attribute inference. Extensive experiments demonstrate our model's effectiveness and unique explainability across multiple datasets. Our code and data are available at: Comments: Ongoing work; 10 pages, 2 Tables, 9 Figures; Repo is available at https://github.com/JethroJames/CREST.