 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStitchFusion: Weaving Any Visual Modalities to Enhance Multimodal Semantic Segmentation
Paper and Code
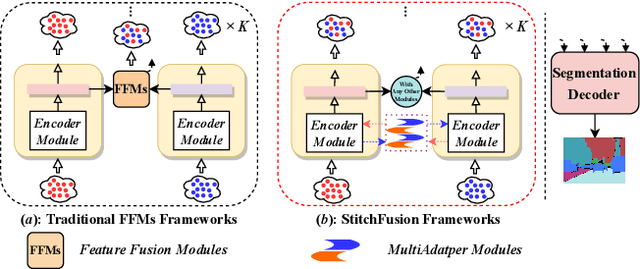
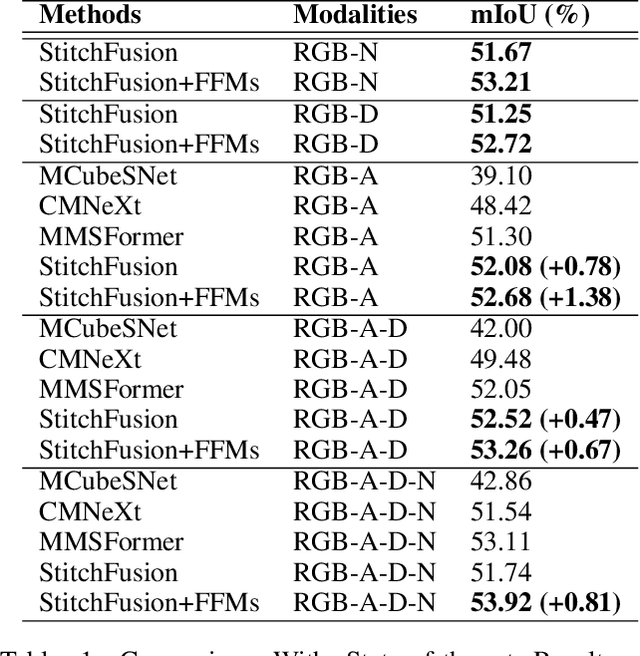
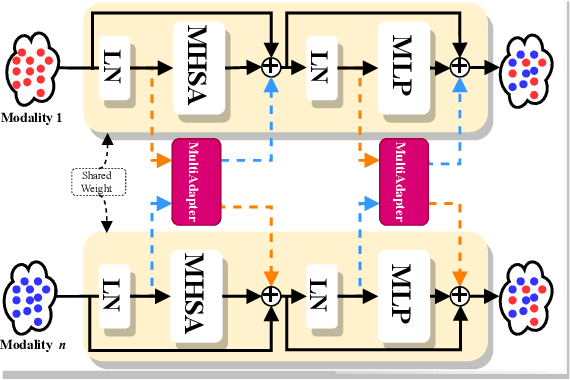
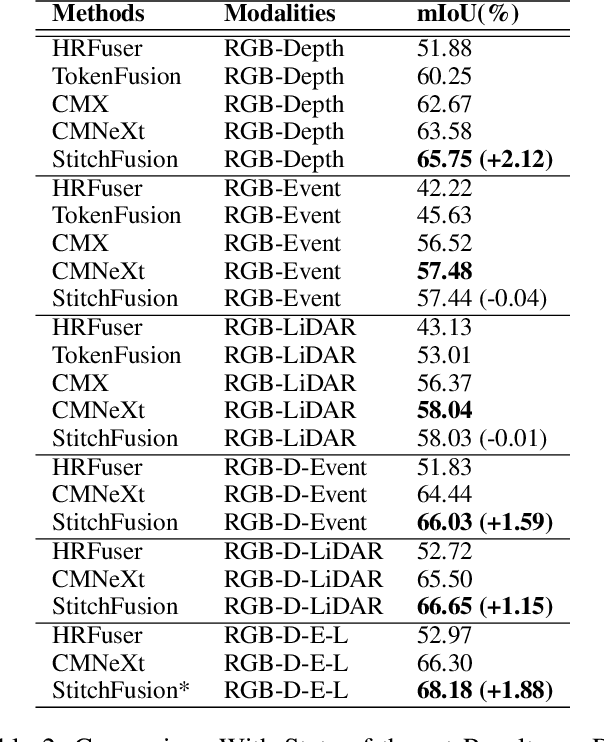
Multimodal semantic segmentation shows significant potential for enhancing segmentation accuracy in complex scenes. However, current methods often incorporate specialized feature fusion modules tailored to specific modalities, thereby restricting input flexibility and increasing the number of training parameters. To address these challenges, we propose StitchFusion, a straightforward yet effective modal fusion framework that integrates large-scale pre-trained models directly as encoders and feature fusers. This approach facilitates comprehensive multi-modal and multi-scale feature fusion, accommodating any visual modal inputs. Specifically, Our framework achieves modal integration during encoding by sharing multi-modal visual information. To enhance information exchange across modalities, we introduce a multi-directional adapter module (MultiAdapter) to enable cross-modal information transfer during encoding. By leveraging MultiAdapter to propagate multi-scale information across pre-trained encoders during the encoding process, StitchFusion achieves multi-modal visual information integration during encoding. Extensive comparative experiments demonstrate that our model achieves state-of-the-art performance on four multi-modal segmentation datasets with minimal additional parameters. Furthermore, the experimental integration of MultiAdapter with existing Feature Fusion Modules (FFMs) highlights their complementary nature. Our code is available at StitchFusion_repo.