 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTUM2TWIN: Introducing the Large-Scale Multimodal Urban Digital Twin Benchmark Dataset
May 13, 2025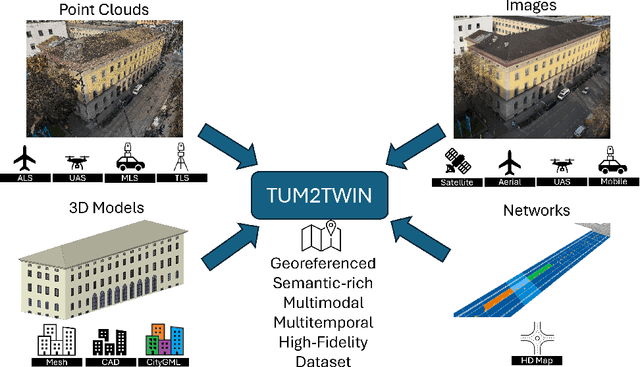
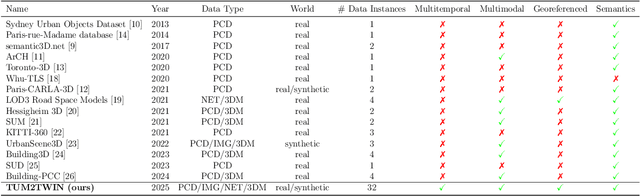

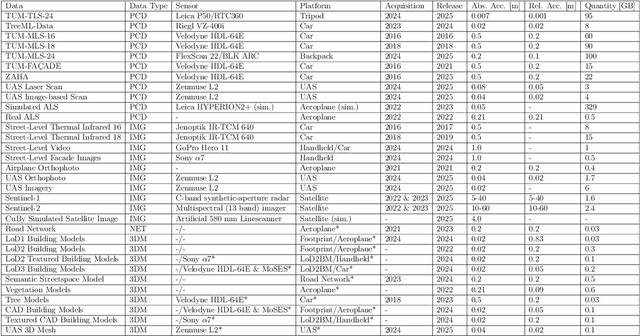
Urban Digital Twins (UDTs) have become essential for managing cities and integrating complex, heterogeneous data from diverse sources. Creating UDTs involves challenges at multiple process stages, including acquiring accurate 3D source data, reconstructing high-fidelity 3D models, maintaining models' updates, and ensuring seamless interoperability to downstream tasks. Current datasets are usually limited to one part of the processing chain, hampering comprehensive UDTs validation. To address these challenges, we introduce the first comprehensive multimodal Urban Digital Twin benchmark dataset: TUM2TWIN. This dataset includes georeferenced, semantically aligned 3D models and networks along with various terrestrial, mobile, aerial, and satellite observations boasting 32 data subsets over roughly 100,000 $m^2$ and currently 767 GB of data. By ensuring georeferenced indoor-outdoor acquisition, high accuracy, and multimodal data integration, the benchmark supports robust analysis of sensors and the development of advanced reconstruction methods. Additionally, we explore downstream tasks demonstrating the potential of TUM2TWIN, including novel view synthesis of NeRF and Gaussian Splatting, solar potential analysis, point cloud semantic segmentation, and LoD3 building reconstruction. We are convinced this contribution lays a foundation for overcoming current limitations in UDT creation, fostering new research directions and practical solutions for smarter, data-driven urban environments. The project is available under: https://tum2t.win
AutoCBT: An Autonomous Multi-agent Framework for Cognitive Behavioral Therapy in Psychological Counseling
Jan 16, 2025



Traditional in-person psychological counseling remains primarily niche, often chosen by individuals with psychological issues, while online automated counseling offers a potential solution for those hesitant to seek help due to feelings of shame. Cognitive Behavioral Therapy (CBT) is an essential and widely used approach in psychological counseling. The advent of large language models (LLMs) and agent technology enables automatic CBT diagnosis and treatment. However, current LLM-based CBT systems use agents with a fixed structure, limiting their self-optimization capabilities, or providing hollow, unhelpful suggestions due to redundant response patterns. In this work, we utilize Quora-like and YiXinLi single-round consultation models to build a general agent framework that generates high-quality responses for single-turn psychological consultation scenarios. We use a bilingual dataset to evaluate the quality of single-response consultations generated by each framework. Then, we incorporate dynamic routing and supervisory mechanisms inspired by real psychological counseling to construct a CBT-oriented autonomous multi-agent framework, demonstrating its general applicability. Experimental results indicate that AutoCBT can provide higher-quality automated psychological counseling services.
Enriching thermal point clouds of buildings using semantic 3D building modelsenriching thermal point clouds of buildings using semantic 3D building models
Jul 31, 2024



Thermal point clouds integrate thermal radiation and laser point clouds effectively. However, the semantic information for the interpretation of building thermal point clouds can hardly be precisely inferred. Transferring the semantics encapsulated in 3D building models at LoD3 has a potential to fill this gap. In this work, we propose a workflow enriching thermal point clouds with the geo-position and semantics of LoD3 building models, which utilizes features of both modalities: The proposed method can automatically co-register the point clouds from different sources and enrich the thermal point cloud in facade-detailed semantics. The enriched thermal point cloud supports thermal analysis and can facilitate the development of currently scarce deep learning models operating directly on thermal point clouds.
CollectiveSFT: Scaling Large Language Models for Chinese Medical Benchmark with Collective Instructions in Healthcare
Jul 29, 2024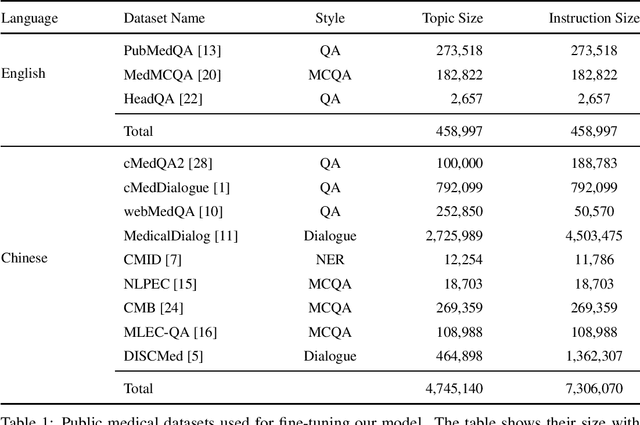

The rapid progress in Large Language Models (LLMs) has prompted the creation of numerous benchmarks to evaluate their capabilities.This study focuses on the Comprehensive Medical Benchmark in Chinese (CMB), showcasing how dataset diversity and distribution in supervised fine-tuning (SFT) may enhance LLM performance.Remarkably, We successfully trained a smaller base model to achieve scores comparable to larger models, indicating that a diverse and well-distributed dataset can optimize performance regardless of model size.This study suggests that even smaller models may reach high performance levels with carefully curated and varied datasets.By integrating a wide range of instructional content, our approach addresses potential issues such as data quality inconsistencies. Our results imply that a broader spectrum of training data may enhance a model's ability to generalize and perform effectively across different medical scenarios, highlighting the importance of dataset quality and diversity in fine-tuning processes.
CPsyCoun: A Report-based Multi-turn Dialogue Reconstruction and Evaluation Framework for Chinese Psychological Counseling
May 26, 2024
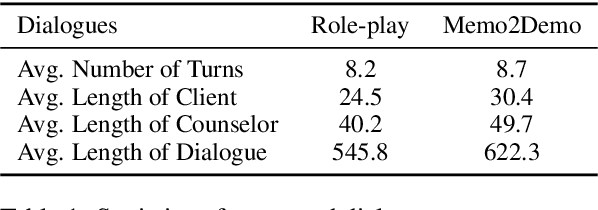

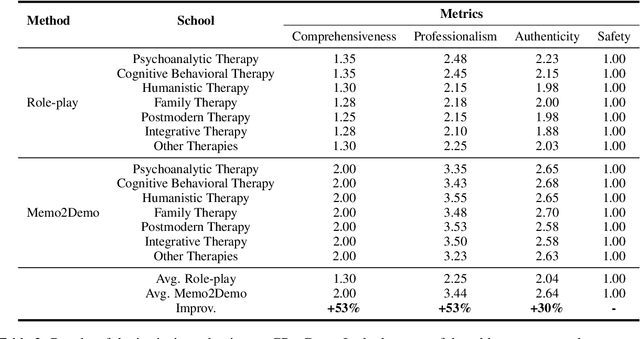
Using large language models (LLMs) to assist psychological counseling is a significant but challenging task at present. Attempts have been made on improving empathetic conversations or acting as effective assistants in the treatment with LLMs. However, the existing datasets lack consulting knowledge, resulting in LLMs lacking professional consulting competence. Moreover, how to automatically evaluate multi-turn dialogues within the counseling process remains an understudied area. To bridge the gap, we propose CPsyCoun, a report-based multi-turn dialogue reconstruction and evaluation framework for Chinese psychological counseling. To fully exploit psychological counseling reports, a two-phase approach is devised to construct high-quality dialogues while a comprehensive evaluation benchmark is developed for the effective automatic evaluation of multi-turn psychological consultations. Competitive experimental results demonstrate the effectiveness of our proposed framework in psychological counseling. We open-source the datasets and model for future research at https://github.com/CAS-SIAT-XinHai/CPsyCoun
CPsyExam: A Chinese Benchmark for Evaluating Psychology using Examinations
May 16, 2024



In this paper, we introduce a novel psychological benchmark, CPsyExam, constructed from questions sourced from Chinese language examinations. CPsyExam is designed to prioritize psychological knowledge and case analysis separately, recognizing the significance of applying psychological knowledge to real-world scenarios. From the pool of 22k questions, we utilize 4k to create the benchmark that offers balanced coverage of subjects and incorporates a diverse range of case analysis techniques.Furthermore, we evaluate a range of existing large language models~(LLMs), spanning from open-sourced to API-based models. Our experiments and analysis demonstrate that CPsyExam serves as an effective benchmark for enhancing the understanding of psychology within LLMs and enables the comparison of LLMs across various granularities.