 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTUM2TWIN: Introducing the Large-Scale Multimodal Urban Digital Twin Benchmark Dataset
May 13, 2025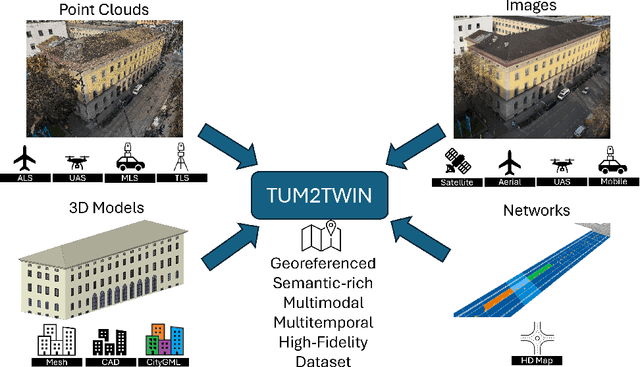
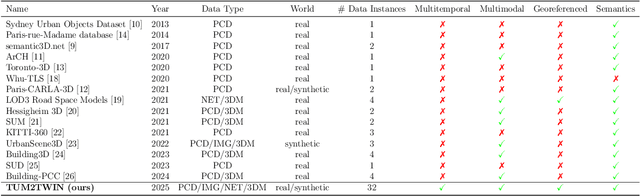

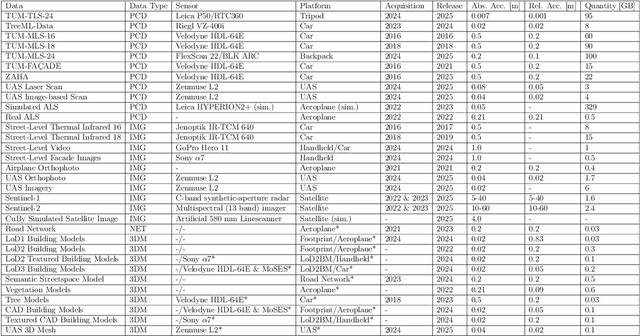
Urban Digital Twins (UDTs) have become essential for managing cities and integrating complex, heterogeneous data from diverse sources. Creating UDTs involves challenges at multiple process stages, including acquiring accurate 3D source data, reconstructing high-fidelity 3D models, maintaining models' updates, and ensuring seamless interoperability to downstream tasks. Current datasets are usually limited to one part of the processing chain, hampering comprehensive UDTs validation. To address these challenges, we introduce the first comprehensive multimodal Urban Digital Twin benchmark dataset: TUM2TWIN. This dataset includes georeferenced, semantically aligned 3D models and networks along with various terrestrial, mobile, aerial, and satellite observations boasting 32 data subsets over roughly 100,000 $m^2$ and currently 767 GB of data. By ensuring georeferenced indoor-outdoor acquisition, high accuracy, and multimodal data integration, the benchmark supports robust analysis of sensors and the development of advanced reconstruction methods. Additionally, we explore downstream tasks demonstrating the potential of TUM2TWIN, including novel view synthesis of NeRF and Gaussian Splatting, solar potential analysis, point cloud semantic segmentation, and LoD3 building reconstruction. We are convinced this contribution lays a foundation for overcoming current limitations in UDT creation, fostering new research directions and practical solutions for smarter, data-driven urban environments. The project is available under: https://tum2t.win
Texture2LoD3: Enabling LoD3 Building Reconstruction With Panoramic Images
Apr 07, 2025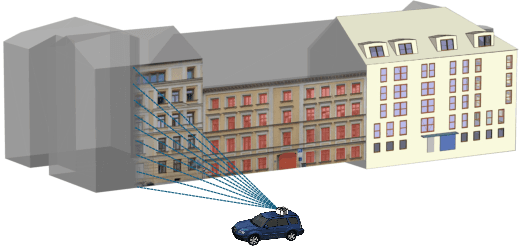
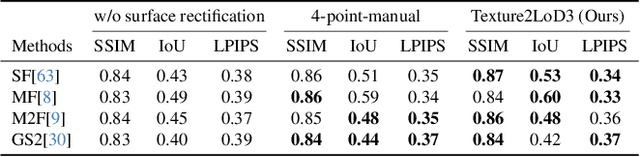
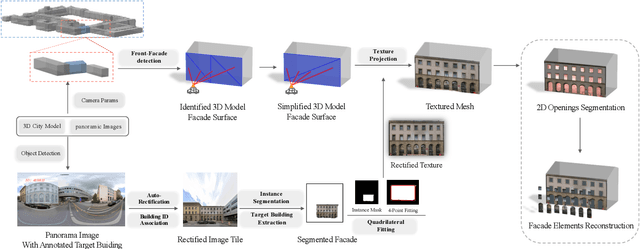

Despite recent advancements in surface reconstruction, Level of Detail (LoD) 3 building reconstruction remains an unresolved challenge. The main issue pertains to the object-oriented modelling paradigm, which requires georeferencing, watertight geometry, facade semantics, and low-poly representation -- Contrasting unstructured mesh-oriented models. In Texture2LoD3, we introduce a novel method leveraging the ubiquity of 3D building model priors and panoramic street-level images, enabling the reconstruction of LoD3 building models. We observe that prior low-detail building models can serve as valid planar targets for ortho-rectifying street-level panoramic images. Moreover, deploying segmentation on accurately textured low-level building surfaces supports maintaining essential georeferencing, watertight geometry, and low-poly representation for LoD3 reconstruction. In the absence of LoD3 validation data, we additionally introduce the ReLoD3 dataset, on which we experimentally demonstrate that our method leads to improved facade segmentation accuracy by 11% and can replace costly manual projections. We believe that Texture2LoD3 can scale the adoption of LoD3 models, opening applications in estimating building solar potential or enhancing autonomous driving simulations. The project website, code, and data are available here: https://wenzhaotang.github.io/Texture2LoD3/.
ZAHA: Introducing the Level of Facade Generalization and the Large-Scale Point Cloud Facade Semantic Segmentation Benchmark Dataset
Nov 07, 2024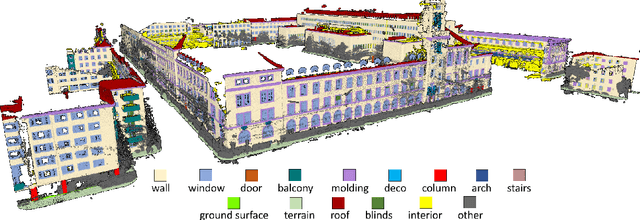
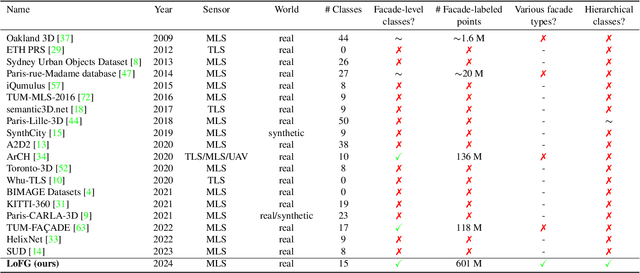
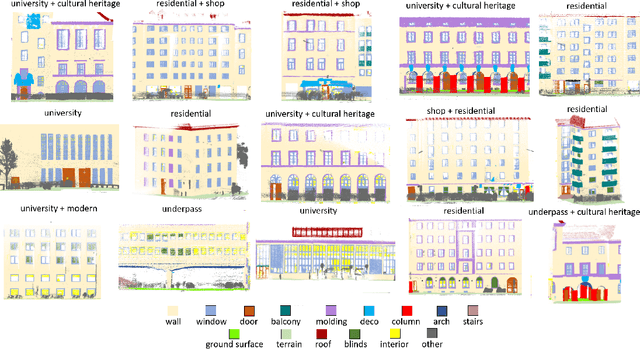
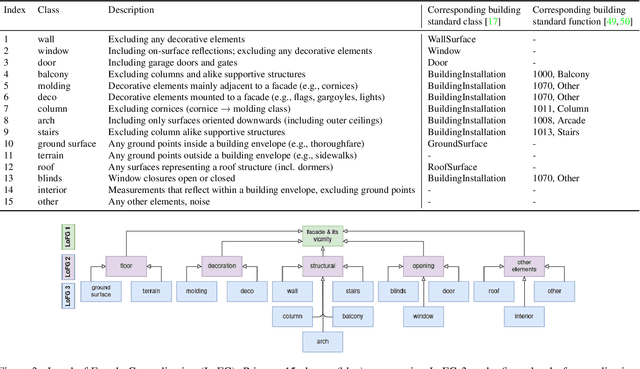
Facade semantic segmentation is a long-standing challenge in photogrammetry and computer vision. Although the last decades have witnessed the influx of facade segmentation methods, there is a lack of comprehensive facade classes and data covering the architectural variability. In ZAHA, we introduce Level of Facade Generalization (LoFG), novel hierarchical facade classes designed based on international urban modeling standards, ensuring compatibility with real-world challenging classes and uniform methods' comparison. Realizing the LoFG, we present to date the largest semantic 3D facade segmentation dataset, providing 601 million annotated points at five and 15 classes of LoFG2 and LoFG3, respectively. Moreover, we analyze the performance of baseline semantic segmentation methods on our introduced LoFG classes and data, complementing it with a discussion on the unresolved challenges for facade segmentation. We firmly believe that ZAHA shall facilitate further development of 3D facade semantic segmentation methods, enabling robust segmentation indispensable in creating urban digital twins.
Enriching thermal point clouds of buildings using semantic 3D building modelsenriching thermal point clouds of buildings using semantic 3D building models
Jul 31, 2024



Thermal point clouds integrate thermal radiation and laser point clouds effectively. However, the semantic information for the interpretation of building thermal point clouds can hardly be precisely inferred. Transferring the semantics encapsulated in 3D building models at LoD3 has a potential to fill this gap. In this work, we propose a workflow enriching thermal point clouds with the geo-position and semantics of LoD3 building models, which utilizes features of both modalities: The proposed method can automatically co-register the point clouds from different sources and enrich the thermal point cloud in facade-detailed semantics. The enriched thermal point cloud supports thermal analysis and can facilitate the development of currently scarce deep learning models operating directly on thermal point clouds.
Analyzing the impact of semantic LoD3 building models on image-based vehicle localization
Jul 31, 2024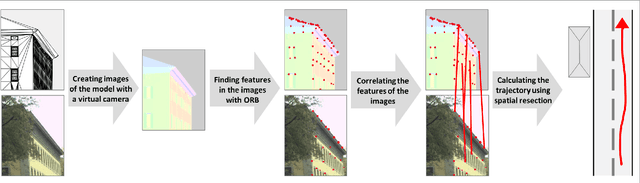
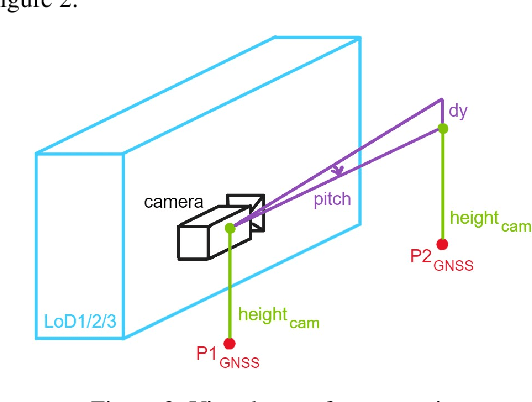
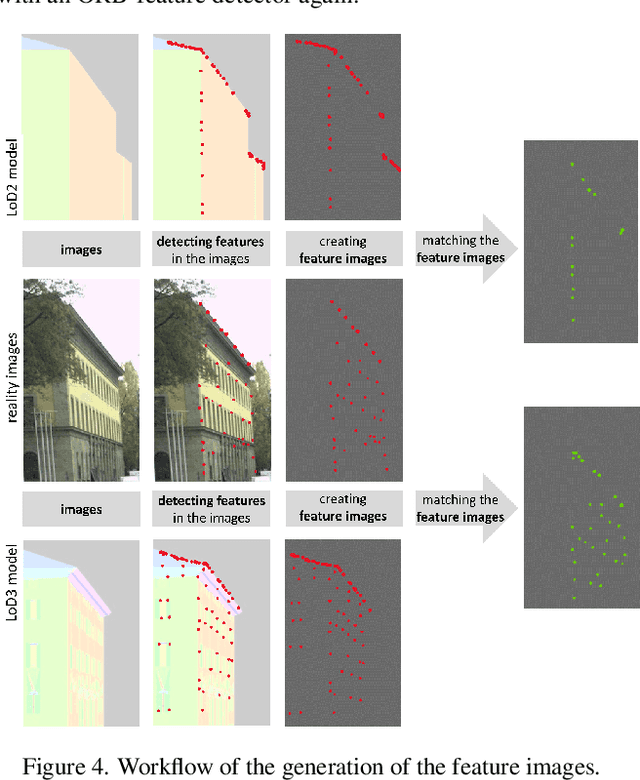
Numerous navigation applications rely on data from global navigation satellite systems (GNSS), even though their accuracy is compromised in urban areas, posing a significant challenge, particularly for precise autonomous car localization. Extensive research has focused on enhancing localization accuracy by integrating various sensor types to address this issue. This paper introduces a novel approach for car localization, leveraging image features that correspond with highly detailed semantic 3D building models. The core concept involves augmenting positioning accuracy by incorporating prior geometric and semantic knowledge into calculations. The work assesses outcomes using Level of Detail 2 (LoD2) and Level of Detail 3 (LoD3) models, analyzing whether facade-enriched models yield superior accuracy. This comprehensive analysis encompasses diverse methods, including off-the-shelf feature matching and deep learning, facilitating thorough discussion. Our experiments corroborate that LoD3 enables detecting up to 69\% more features than using LoD2 models. We believe that this study will contribute to the research of enhancing positioning accuracy in GNSS-denied urban canyons. It also shows a practical application of under-explored LoD3 building models on map-based car positioning.