 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultivariate Gaussian NeRF for Wide Field-of-View Ultrasound Reconstruction
Apr 27, 2026Wide Field-of-View (WFoV) reconstruction enhances 3D ultrasound imaging by providing valuable anatomical context for segmentation models and visualization. Clinical ultrasound volumes are predominantly acquired using convex probes, which generate expanding, diverging acoustic beams to maximize anatomical coverage. Stitching these sweeps together traditionally introduces significant compounding artifacts and aliasing due to depth-dependent resolution changes. Here, we introduce Ultra-Wide-NeRF, a Multivariate 3D Gaussian (MVG) NeRF-based method for WFoV ultrasound reconstruction. By explicitly modeling the complex beam geometry using distance-dependent convex volumetric sampling and anisotropic 3D Gaussians, our method inherently mitigates these compounding artifacts and provides anti-aliasing. Beyond simply reconstructing a static 3D grid, our NeRF-based approach yields a continuous neural representation of the tissue, enabling the synthesis of high-fidelity novel views from arbitrary virtual trajectories. We validate Ultra-Wide-NeRF for intracardiac echocardiography on phantom and porcine datasets, demonstrating that our method expands the spatial context important in intraoperative navigation. Code will be open-sourced upon publication.
UltraG-Ray: Physics-Based Gaussian Ray Casting for Novel Ultrasound View Synthesis
Mar 30, 2026Novel view synthesis (NVS) in ultrasound has gained attention as a technique for generating anatomically plausible views beyond the acquired frames, offering new capabilities for training clinicians or data augmentation. However, current methods struggle with complex tissue and view-dependent acoustic effects. Physics-based NVS aims to address these limitations by including the ultrasound image formation process into the simulation. Recent approaches combine a learnable implicit scene representation with an ultrasound-specific rendering module, yet a substantial gap between simulation and reality remains. In this work, we introduce UltraG-Ray, a novel ultrasound scene representation based on a learnable 3D Gaussian field, coupled to an efficient physics-based module for B-mode synthesis. We explicitly encode ultrasound-specific parameters, such as attenuation and reflection, into a Gaussian-based spatial representation and realize image synthesis within a novel ray casting scheme. In contrast to previous methods, this approach naturally captures view-dependent attenuation effects, thereby enabling the generation of physically informed B-mode images with increased realism. We compare our method to state-of-the-art and observe consistent gains in image quality metrics (up to 15% increase on MS-SSIM), demonstrating clear improvement in terms of realism of the synthesized ultrasound images.
OSCAR: Occupancy-based Shape Completion via Acoustic Neural Implicit Representations
Mar 09, 2026Accurate 3D reconstruction of vertebral anatomy from ultrasound is important for guiding minimally invasive spine interventions, but it remains challenging due to acoustic shadowing and view-dependent signal variations. We propose an occupancy-based shape completion method that reconstructs complete 3D anatomical geometry from partial ultrasound observations. Crucially for intra-operative applications, our approach extracts the anatomical surface directly from the image, avoiding the need for anatomical labels during inference. This label-free completion relies on a coupled latent space representing both the image appearance and the underlying anatomical shape. By leveraging a Neural Implicit Representation (NIR) that jointly models both spatial occupancy and acoustic interactions, the method uses acoustic parameters to become implicitly aware of the unseen regions without explicit shadowing labels through tracking acoustic signal transmission. We show that this method outperforms state-of-the-art shape completion for B-mode ultrasound by 80% in HD95 score. We validate our approach both in-silico and on phantom US images with registered mesh models from CT labels, demonstrating accurate reconstruction of occluded anatomy and robust generalization across diverse imaging conditions. Code and data will be released on publication.
UltrON: Ultrasound Occupancy Networks
Sep 10, 2025In free-hand ultrasound imaging, sonographers rely on expertise to mentally integrate partial 2D views into 3D anatomical shapes. Shape reconstruction can assist clinicians in this process. Central to this task is the choice of shape representation, as it determines how accurately and efficiently the structure can be visualized, analyzed, and interpreted. Implicit representations, such as SDF and occupancy function, offer a powerful alternative to traditional voxel- or mesh-based methods by modeling continuous, smooth surfaces with compact storage, avoiding explicit discretization. Recent studies demonstrate that SDF can be effectively optimized using annotations derived from segmented B-mode ultrasound images. Yet, these approaches hinge on precise annotations, overlooking the rich acoustic information embedded in B-mode intensity. Moreover, implicit representation approaches struggle with the ultrasound's view-dependent nature and acoustic shadowing artifacts, which impair reconstruction. To address the problems resulting from occlusions and annotation dependency, we propose an occupancy-based representation and introduce \gls{UltrON} that leverages acoustic features to improve geometric consistency in weakly-supervised optimization regime. We show that these features can be obtained from B-mode images without additional annotation cost. Moreover, we propose a novel loss function that compensates for view-dependency in the B-mode images and facilitates occupancy optimization from multiview ultrasound. By incorporating acoustic properties, \gls{UltrON} generalizes to shapes of the same anatomy. We show that \gls{UltrON} mitigates the limitations of occlusions and sparse labeling and paves the way for more accurate 3D reconstruction. Code and dataset will be available at https://github.com/magdalena-wysocki/ultron.
EgoExOR: An Ego-Exo-Centric Operating Room Dataset for Surgical Activity Understanding
May 30, 2025Operating rooms (ORs) demand precise coordination among surgeons, nurses, and equipment in a fast-paced, occlusion-heavy environment, necessitating advanced perception models to enhance safety and efficiency. Existing datasets either provide partial egocentric views or sparse exocentric multi-view context, but do not explore the comprehensive combination of both. We introduce EgoExOR, the first OR dataset and accompanying benchmark to fuse first-person and third-person perspectives. Spanning 94 minutes (84,553 frames at 15 FPS) of two emulated spine procedures, Ultrasound-Guided Needle Insertion and Minimally Invasive Spine Surgery, EgoExOR integrates egocentric data (RGB, gaze, hand tracking, audio) from wearable glasses, exocentric RGB and depth from RGB-D cameras, and ultrasound imagery. Its detailed scene graph annotations, covering 36 entities and 22 relations (568,235 triplets), enable robust modeling of clinical interactions, supporting tasks like action recognition and human-centric perception. We evaluate the surgical scene graph generation performance of two adapted state-of-the-art models and offer a new baseline that explicitly leverages EgoExOR's multimodal and multi-perspective signals. This new dataset and benchmark set a new foundation for OR perception, offering a rich, multimodal resource for next-generation clinical perception.
ZAHA: Introducing the Level of Facade Generalization and the Large-Scale Point Cloud Facade Semantic Segmentation Benchmark Dataset
Nov 07, 2024
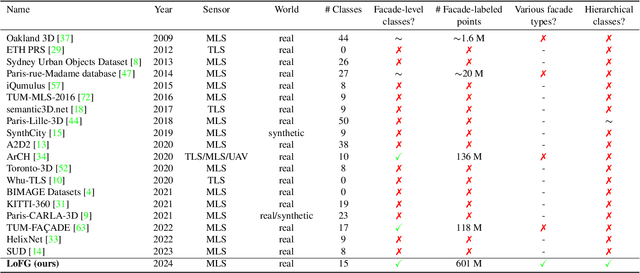
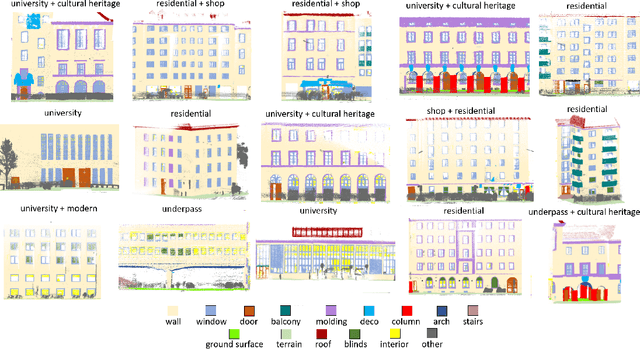
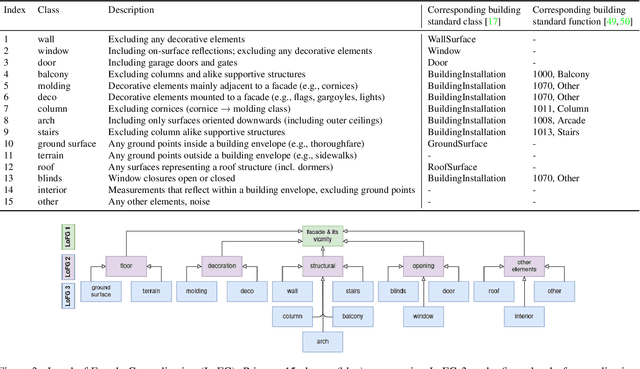
Facade semantic segmentation is a long-standing challenge in photogrammetry and computer vision. Although the last decades have witnessed the influx of facade segmentation methods, there is a lack of comprehensive facade classes and data covering the architectural variability. In ZAHA, we introduce Level of Facade Generalization (LoFG), novel hierarchical facade classes designed based on international urban modeling standards, ensuring compatibility with real-world challenging classes and uniform methods' comparison. Realizing the LoFG, we present to date the largest semantic 3D facade segmentation dataset, providing 601 million annotated points at five and 15 classes of LoFG2 and LoFG3, respectively. Moreover, we analyze the performance of baseline semantic segmentation methods on our introduced LoFG classes and data, complementing it with a discussion on the unresolved challenges for facade segmentation. We firmly believe that ZAHA shall facilitate further development of 3D facade semantic segmentation methods, enabling robust segmentation indispensable in creating urban digital twins.
PHOCUS: Physics-Based Deconvolution for Ultrasound Resolution Enhancement
Aug 07, 2024Ultrasound is widely used in medical diagnostics allowing for accessible and powerful imaging but suffers from resolution limitations due to diffraction and the finite aperture of the imaging system, which restricts diagnostic use. The impulse function of an ultrasound imaging system is called the point spread function (PSF), which is convolved with the spatial distribution of reflectors in the image formation process. Recovering high-resolution reflector distributions by removing image distortions induced by the convolution process improves image clarity and detail. Conventionally, deconvolution techniques attempt to rectify the imaging system's dependent PSF, working directly on the radio-frequency (RF) data. However, RF data is often not readily accessible. Therefore, we introduce a physics-based deconvolution process using a modeled PSF, working directly on the more commonly available B-mode images. By leveraging Implicit Neural Representations (INRs), we learn a continuous mapping from spatial locations to their respective echogenicity values, effectively compensating for the discretized image space. Our contribution consists of a novel methodology for retrieving a continuous echogenicity map directly from a B-mode image through a differentiable physics-based rendering pipeline for ultrasound resolution enhancement. We qualitatively and quantitatively evaluate our approach on synthetic data, demonstrating improvements over traditional methods in metrics such as PSNR and SSIM. Furthermore, we show qualitative enhancements on an ultrasound phantom and an in-vivo acquisition of a carotid artery.
Scan2LoD3: Reconstructing semantic 3D building models at LoD3 using ray casting and Bayesian networks
May 10, 2023



Reconstructing semantic 3D building models at the level of detail (LoD) 3 is a long-standing challenge. Unlike mesh-based models, they require watertight geometry and object-wise semantics at the fa\c{c}ade level. The principal challenge of such demanding semantic 3D reconstruction is reliable fa\c{c}ade-level semantic segmentation of 3D input data. We present a novel method, called Scan2LoD3, that accurately reconstructs semantic LoD3 building models by improving fa\c{c}ade-level semantic 3D segmentation. To this end, we leverage laser physics and 3D building model priors to probabilistically identify model conflicts. These probabilistic physical conflicts propose locations of model openings: Their final semantics and shapes are inferred in a Bayesian network fusing multimodal probabilistic maps of conflicts, 3D point clouds, and 2D images. To fulfill demanding LoD3 requirements, we use the estimated shapes to cut openings in 3D building priors and fit semantic 3D objects from a library of fa\c{c}ade objects. Extensive experiments on the TUM city campus datasets demonstrate the superior performance of the proposed Scan2LoD3 over the state-of-the-art methods in fa\c{c}ade-level detection, semantic segmentation, and LoD3 building model reconstruction. We believe our method can foster the development of probability-driven semantic 3D reconstruction at LoD3 since not only the high-definition reconstruction but also reconstruction confidence becomes pivotal for various applications such as autonomous driving and urban simulations.
Ultra-NeRF: Neural Radiance Fields for Ultrasound Imaging
Jan 25, 2023



We present a physics-enhanced implicit neural representation (INR) for ultrasound (US) imaging that learns tissue properties from overlapping US sweeps. Our proposed method leverages a ray-tracing-based neural rendering for novel view US synthesis. Recent publications demonstrated that INR models could encode a representation of a three-dimensional scene from a set of two-dimensional US frames. However, these models fail to consider the view-dependent changes in appearance and geometry intrinsic to US imaging. In our work, we discuss direction-dependent changes in the scene and show that a physics-inspired rendering improves the fidelity of US image synthesis. In particular, we demonstrate experimentally that our proposed method generates geometrically accurate B-mode images for regions with ambiguous representation owing to view-dependent differences of the US images. We conduct our experiments using simulated B-mode US sweeps of the liver and acquired US sweeps of a spine phantom tracked with a robotic arm. The experiments corroborate that our method generates US frames that enable consistent volume compounding from previously unseen views. To the best of our knowledge, the presented work is the first to address view-dependent US image synthesis using INR.