 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLS2LoD3: Refining low LoDs building models with MLS point clouds to reconstruct semantic LoD3 building models
Feb 09, 2024Although highly-detailed LoD3 building models reveal great potential in various applications, they have yet to be available. The primary challenges in creating such models concern not only automatic detection and reconstruction but also standard-consistent modeling. In this paper, we introduce a novel refinement strategy enabling LoD3 reconstruction by leveraging the ubiquity of lower LoD building models and the accuracy of MLS point clouds. Such a strategy promises at-scale LoD3 reconstruction and unlocks LoD3 applications, which we also describe and illustrate in this paper. Additionally, we present guidelines for reconstructing LoD3 facade elements and their embedding into the CityGML standard model, disseminating gained knowledge to academics and professionals. We believe that our method can foster development of LoD3 reconstruction algorithms and subsequently enable their wider adoption.
Classifying point clouds at the facade-level using geometric features and deep learning networks
Feb 09, 2024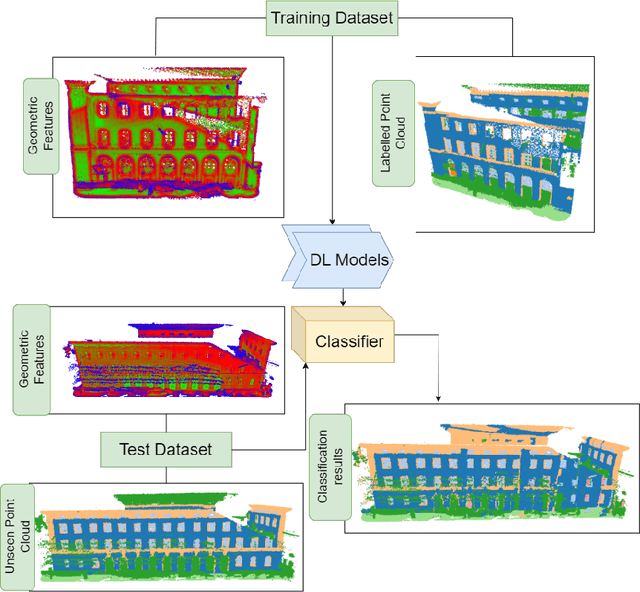
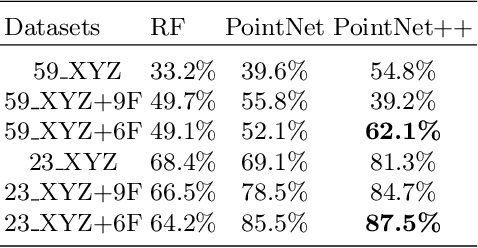
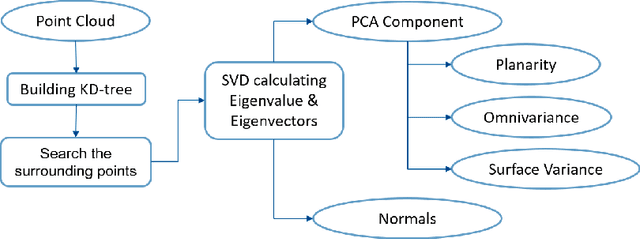
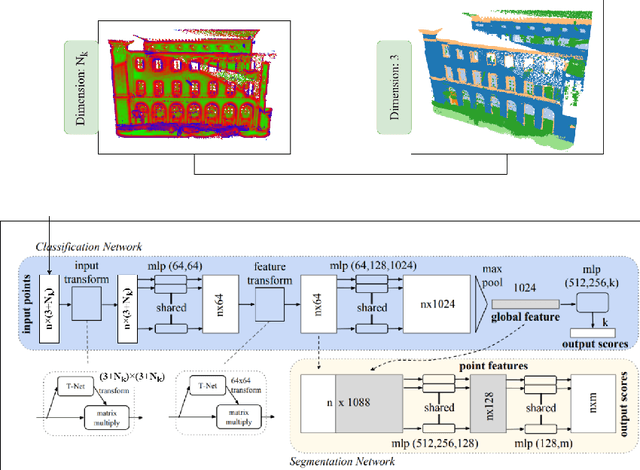
3D building models with facade details are playing an important role in many applications now. Classifying point clouds at facade-level is key to create such digital replicas of the real world. However, few studies have focused on such detailed classification with deep neural networks. We propose a method fusing geometric features with deep learning networks for point cloud classification at facade-level. Our experiments conclude that such early-fused features improve deep learning methods' performance. This method can be applied for compensating deep learning networks' ability in capturing local geometric information and promoting the advancement of semantic segmentation.
Reconstructing facade details using MLS point clouds and Bag-of-Words approach
Feb 09, 2024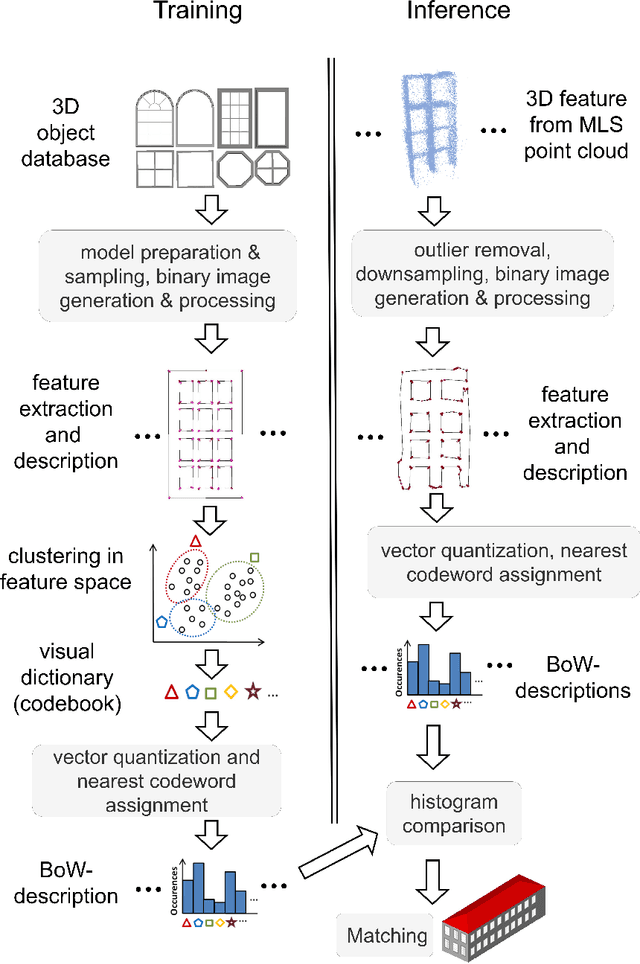



In the reconstruction of fa\c{c}ade elements, the identification of specific object types remains challenging and is often circumvented by rectangularity assumptions or the use of bounding boxes. We propose a new approach for the reconstruction of 3D fa\c{c}ade details. We combine MLS point clouds and a pre-defined 3D model library using a BoW concept, which we augment by incorporating semi-global features. We conduct experiments on the models superimposed with random noise and on the TUM-FA\c{C}ADE dataset. Our method demonstrates promising results, improving the conventional BoW approach. It holds the potential to be utilized for more realistic facade reconstruction without rectangularity assumptions, which can be used in applications such as testing automated driving functions or estimating fa\c{c}ade solar potential.
Transferring facade labels between point clouds with semantic octrees while considering change detection
Feb 09, 2024Point clouds and high-resolution 3D data have become increasingly important in various fields, including surveying, construction, and virtual reality. However, simply having this data is not enough; to extract useful information, semantic labeling is crucial. In this context, we propose a method to transfer annotations from a labeled to an unlabeled point cloud using an octree structure. The structure also analyses changes between the point clouds. Our experiments confirm that our method effectively transfers annotations while addressing changes. The primary contribution of this project is the development of the method for automatic label transfer between two different point clouds that represent the same real-world object. The proposed method can be of great importance for data-driven deep learning algorithms as it can also allow circumventing stochastic transfer learning by deterministic label transfer between datasets depicting the same objects.
Scan2LoD3: Reconstructing semantic 3D building models at LoD3 using ray casting and Bayesian networks
May 10, 2023



Reconstructing semantic 3D building models at the level of detail (LoD) 3 is a long-standing challenge. Unlike mesh-based models, they require watertight geometry and object-wise semantics at the fa\c{c}ade level. The principal challenge of such demanding semantic 3D reconstruction is reliable fa\c{c}ade-level semantic segmentation of 3D input data. We present a novel method, called Scan2LoD3, that accurately reconstructs semantic LoD3 building models by improving fa\c{c}ade-level semantic 3D segmentation. To this end, we leverage laser physics and 3D building model priors to probabilistically identify model conflicts. These probabilistic physical conflicts propose locations of model openings: Their final semantics and shapes are inferred in a Bayesian network fusing multimodal probabilistic maps of conflicts, 3D point clouds, and 2D images. To fulfill demanding LoD3 requirements, we use the estimated shapes to cut openings in 3D building priors and fit semantic 3D objects from a library of fa\c{c}ade objects. Extensive experiments on the TUM city campus datasets demonstrate the superior performance of the proposed Scan2LoD3 over the state-of-the-art methods in fa\c{c}ade-level detection, semantic segmentation, and LoD3 building model reconstruction. We believe our method can foster the development of probability-driven semantic 3D reconstruction at LoD3 since not only the high-definition reconstruction but also reconstruction confidence becomes pivotal for various applications such as autonomous driving and urban simulations.
TUM-FAÇADE: Reviewing and enriching point cloud benchmarks for façade segmentation
Apr 14, 2023Point clouds are widely regarded as one of the best dataset types for urban mapping purposes. Hence, point cloud datasets are commonly investigated as benchmark types for various urban interpretation methods. Yet, few researchers have addressed the use of point cloud benchmarks for fa\c{c}ade segmentation. Robust fa\c{c}ade segmentation is becoming a key factor in various applications ranging from simulating autonomous driving functions to preserving cultural heritage. In this work, we present a method of enriching existing point cloud datasets with fa\c{c}ade-related classes that have been designed to facilitate fa\c{c}ade segmentation testing. We propose how to efficiently extend existing datasets and comprehensively assess their potential for fa\c{c}ade segmentation. We use the method to create the TUM-FA\c{C}ADE dataset, which extends the capabilities of TUM-MLS-2016. Not only can TUM-FA\c{C}ADE facilitate the development of point-cloud-based fa\c{c}ade segmentation tasks, but our procedure can also be applied to enrich further datasets.
* 3D-ARCH 2022, Mantova, Italy, 2022, ISPRS conference
Combining visibility analysis and deep learning for refinement of semantic 3D building models by conflict classification
Mar 10, 2023Semantic 3D building models are widely available and used in numerous applications. Such 3D building models display rich semantics but no fa\c{c}ade openings, chiefly owing to their aerial acquisition techniques. Hence, refining models' fa\c{c}ades using dense, street-level, terrestrial point clouds seems a promising strategy. In this paper, we propose a method of combining visibility analysis and neural networks for enriching 3D models with window and door features. In the method, occupancy voxels are fused with classified point clouds, which provides semantics to voxels. Voxels are also used to identify conflicts between laser observations and 3D models. The semantic voxels and conflicts are combined in a Bayesian network to classify and delineate fa\c{c}ade openings, which are reconstructed using a 3D model library. Unaffected building semantics is preserved while the updated one is added, thereby upgrading the building model to LoD3. Moreover, Bayesian network results are back-projected onto point clouds to improve points' classification accuracy. We tested our method on a municipal CityGML LoD2 repository and the open point cloud datasets: TUM-MLS-2016 and TUM-FA\c{C}ADE. Validation results revealed that the method improves the accuracy of point cloud semantic segmentation and upgrades buildings with fa\c{c}ade elements. The method can be applied to enhance the accuracy of urban simulations and facilitate the development of semantic segmentation algorithms.
* ISPRS Annals, 3DGeoInfo 2022, Australia, Sydney
PVT3D: Point Voxel Transformers for Place Recognition from Sparse Lidar Scans
Nov 22, 2022Place recognition based on point cloud (LiDAR) scans is an important module for achieving robust autonomy in robots or self-driving vehicles. Training deep networks to match such scans presents a difficult trade-off: a higher spatial resolution of the network's intermediate representations is needed to perform fine-grained matching of subtle geometric features, but growing it too large makes the memory requirements infeasible. In this work, we propose a Point-Voxel Transformer network (PVT3D) that achieves robust fine-grained matching with low memory requirements. It leverages a sparse voxel branch to extract and aggregate information at a lower resolution and a point-wise branch to obtain fine-grained local information. A novel hierarchical cross-attention transformer (HCAT) uses queries from one branch to try to match structures in the other branch, ensuring that both extract self-contained descriptors of the point cloud (rather than one branch dominating), but using both to inform the output global descriptor of the point cloud. Extensive experiments show that the proposed PVT3D method surpasses the state-of-the-art by a large amount on several datasets (Oxford RobotCar, TUM, USyd). For instance, we achieve AR@1 of 85.6% on the TUM dataset, which surpasses the strongest prior model by ~15%.
A Lightweight and Detector-free 3D Single Object Tracker on Point Clouds
Mar 08, 2022



Recent works on 3D single object tracking treat the tracking as a target-specific 3D detection task, where an off-the-shelf 3D detector is commonly employed for tracking. However, it is non-trivial to perform accurate target-specific detection since the point cloud of objects in raw LiDAR scans is usually sparse and incomplete. In this paper, we address this issue by explicitly leveraging temporal motion cues and propose DMT, a Detector-free Motion prediction based 3D Tracking network that totally removes the usage of complicated 3D detectors, which is lighter, faster, and more accurate than previous trackers. Specifically, the motion prediction module is firstly introduced to estimate a potential target center of the current frame in a point-cloud free way. Then, an explicit voting module is proposed to directly regress the 3D box from the estimated target center. Extensive experiments on KITTI and NuScenes datasets demonstrate that our DMT, without applying any complicated 3D detectors, can still achieve better performance (~10% improvement on the NuScenes dataset) and faster tracking speed (i.e., 72 FPS) than state-of-the-art approaches. Our codes will be released publicly.
MODISSA: a multipurpose platform for the prototypical realization of vehicle-related applications using optical sensors
May 28, 2021

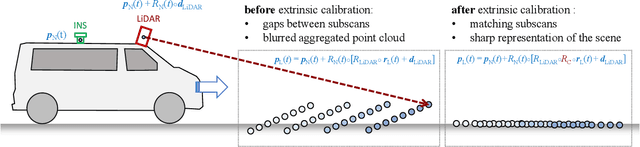

We present the current state of development of the sensor-equipped car MODISSA, with which Fraunhofer IOSB realizes a configurable experimental platform for hardware evaluation and software development in the context of mobile mapping and vehicle-related safety and protection. MODISSA is based on a van that has successively been equipped with a variety of optical sensors over the past few years, and contains hardware for complete raw data acquisition, georeferencing, real-time data analysis, and immediate visualization on in-car displays. We demonstrate the capabilities of MODISSA by giving a deeper insight into experiments with its specific configuration in the scope of three different applications. Other research groups can benefit from these experiences when setting up their own mobile sensor system, especially regarding the selection of hardware and software, the knowledge of possible sources of error, and the handling of the acquired sensor data.
* Authors' version of an article accepted for publication in Applied Optics, 9 May 2021