 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrueCity: Real and Simulated Urban Data for Cross-Domain 3D Scene Understanding
Nov 10, 2025
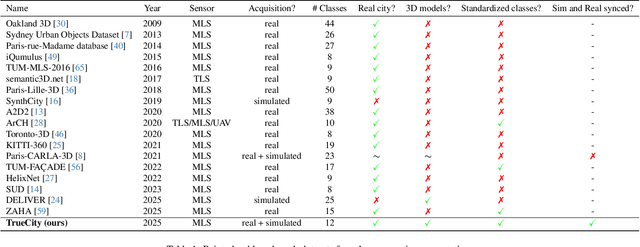
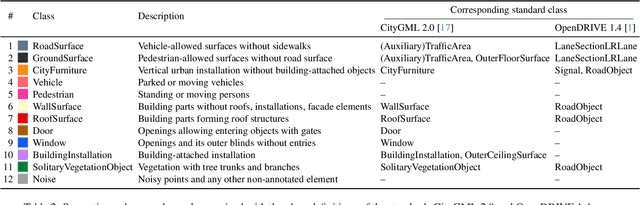
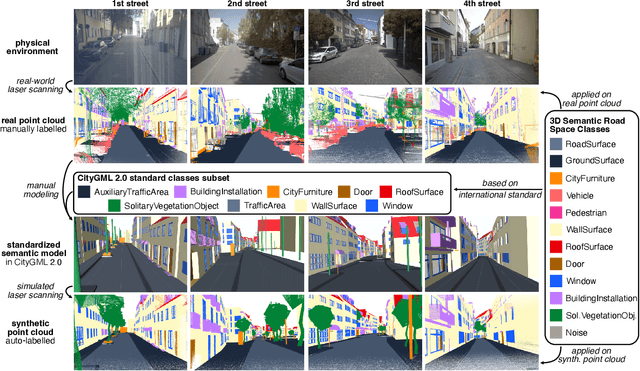
3D semantic scene understanding remains a long-standing challenge in the 3D computer vision community. One of the key issues pertains to limited real-world annotated data to facilitate generalizable models. The common practice to tackle this issue is to simulate new data. Although synthetic datasets offer scalability and perfect labels, their designer-crafted scenes fail to capture real-world complexity and sensor noise, resulting in a synthetic-to-real domain gap. Moreover, no benchmark provides synchronized real and simulated point clouds for segmentation-oriented domain shift analysis. We introduce TrueCity, the first urban semantic segmentation benchmark with cm-accurate annotated real-world point clouds, semantic 3D city models, and annotated simulated point clouds representing the same city. TrueCity proposes segmentation classes aligned with international 3D city modeling standards, enabling consistent evaluation of synthetic-to-real gap. Our extensive experiments on common baselines quantify domain shift and highlight strategies for exploiting synthetic data to enhance real-world 3D scene understanding. We are convinced that the TrueCity dataset will foster further development of sim-to-real gap quantification and enable generalizable data-driven models. The data, code, and 3D models are available online: https://tum-gis.github.io/TrueCity/
InfraDiffusion: zero-shot depth map restoration with diffusion models and prompted segmentation from sparse infrastructure point clouds
Sep 03, 2025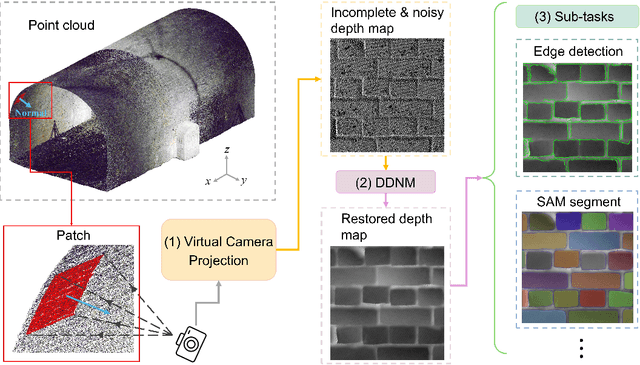
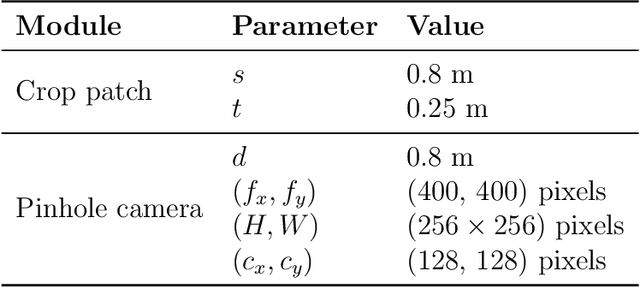
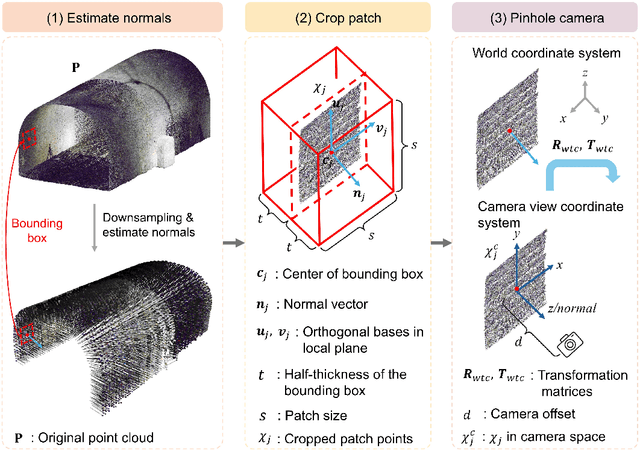
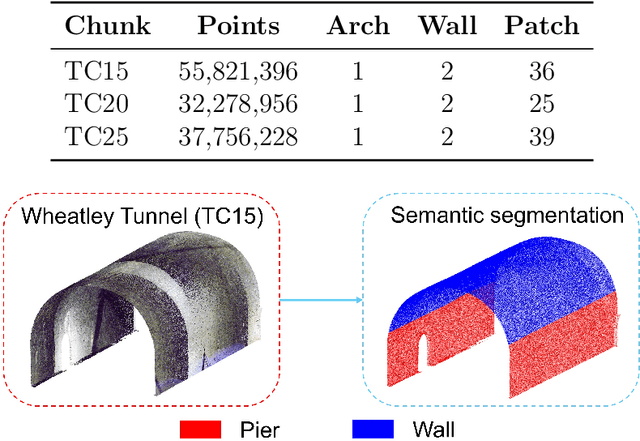
Point clouds are widely used for infrastructure monitoring by providing geometric information, where segmentation is required for downstream tasks such as defect detection. Existing research has automated semantic segmentation of structural components, while brick-level segmentation (identifying defects such as spalling and mortar loss) has been primarily conducted from RGB images. However, acquiring high-resolution images is impractical in low-light environments like masonry tunnels. Point clouds, though robust to dim lighting, are typically unstructured, sparse, and noisy, limiting fine-grained segmentation. We present InfraDiffusion, a zero-shot framework that projects masonry point clouds into depth maps using virtual cameras and restores them by adapting the Denoising Diffusion Null-space Model (DDNM). Without task-specific training, InfraDiffusion enhances visual clarity and geometric consistency of depth maps. Experiments on masonry bridge and tunnel point cloud datasets show significant improvements in brick-level segmentation using the Segment Anything Model (SAM), underscoring its potential for automated inspection of masonry assets. Our code and data is available at https://github.com/Jingyixiong/InfraDiffusion-official-implement.
GS4Buildings: Prior-Guided Gaussian Splatting for 3D Building Reconstruction
Aug 10, 2025



Recent advances in Gaussian Splatting (GS) have demonstrated its effectiveness in photo-realistic rendering and 3D reconstruction. Among these, 2D Gaussian Splatting (2DGS) is particularly suitable for surface reconstruction due to its flattened Gaussian representation and integrated normal regularization. However, its performance often degrades in large-scale and complex urban scenes with frequent occlusions, leading to incomplete building reconstructions. We propose GS4Buildings, a novel prior-guided Gaussian Splatting method leveraging the ubiquity of semantic 3D building models for robust and scalable building surface reconstruction. Instead of relying on traditional Structure-from-Motion (SfM) pipelines, GS4Buildings initializes Gaussians directly from low-level Level of Detail (LoD)2 semantic 3D building models. Moreover, we generate prior depth and normal maps from the planar building geometry and incorporate them into the optimization process, providing strong geometric guidance for surface consistency and structural accuracy. We also introduce an optional building-focused mode that limits reconstruction to building regions, achieving a 71.8% reduction in Gaussian primitives and enabling a more efficient and compact representation. Experiments on urban datasets demonstrate that GS4Buildings improves reconstruction completeness by 20.5% and geometric accuracy by 32.8%. These results highlight the potential of semantic building model integration to advance GS-based reconstruction toward real-world urban applications such as smart cities and digital twins. Our project is available: https://github.com/zqlin0521/GS4Buildings.
Mind the Domain Gap: Measuring the Domain Gap Between Real-World and Synthetic Point Clouds for Automated Driving Development
May 23, 2025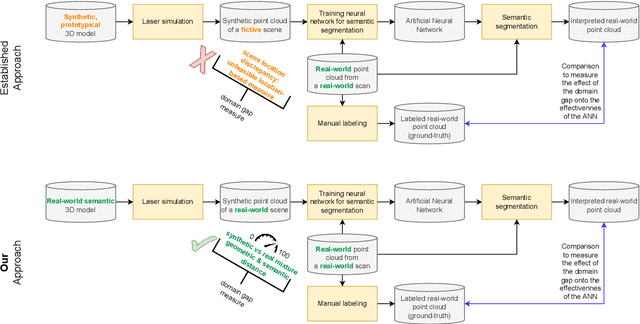

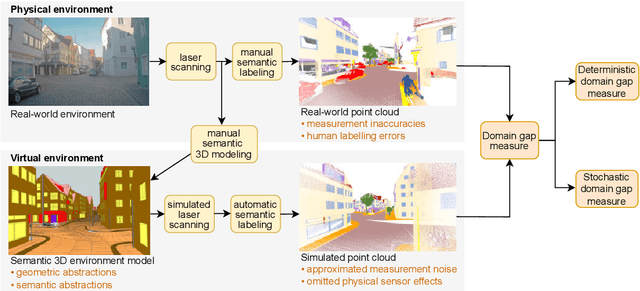
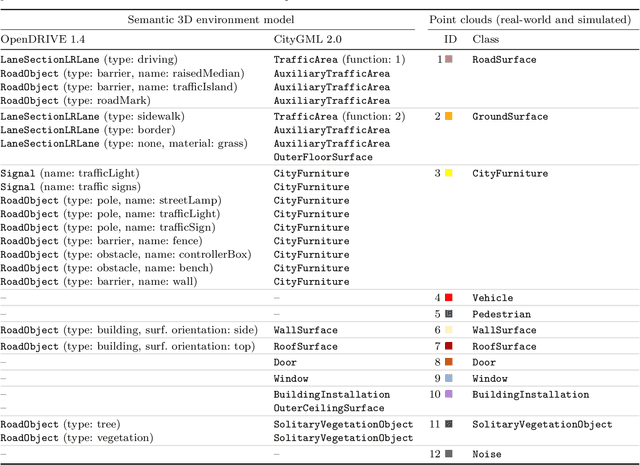
Owing to the typical long-tail data distribution issues, simulating domain-gap-free synthetic data is crucial in robotics, photogrammetry, and computer vision research. The fundamental challenge pertains to credibly measuring the difference between real and simulated data. Such a measure is vital for safety-critical applications, such as automated driving, where out-of-domain samples may impact a car's perception and cause fatal accidents. Previous work has commonly focused on simulating data on one scene and analyzing performance on a different, real-world scene, hampering the disjoint analysis of domain gap coming from networks' deficiencies, class definitions, and object representation. In this paper, we propose a novel approach to measuring the domain gap between the real world sensor observations and simulated data representing the same location, enabling comprehensive domain gap analysis. To measure such a domain gap, we introduce a novel metric DoGSS-PCL and evaluation assessing the geometric and semantic quality of the simulated point cloud. Our experiments corroborate that the introduced approach can be used to measure the domain gap. The tests also reveal that synthetic semantic point clouds may be used for training deep neural networks, maintaining the performance at the 50/50 real-to-synthetic ratio. We strongly believe that this work will facilitate research on credible data simulation and allow for at-scale deployment in automated driving testing and digital twinning.
To Glue or Not to Glue? Classical vs Learned Image Matching for Mobile Mapping Cameras to Textured Semantic 3D Building Models
May 23, 2025Feature matching is a necessary step for many computer vision and photogrammetry applications such as image registration, structure-from-motion, and visual localization. Classical handcrafted methods such as SIFT feature detection and description combined with nearest neighbour matching and RANSAC outlier removal have been state-of-the-art for mobile mapping cameras. With recent advances in deep learning, learnable methods have been introduced and proven to have better robustness and performance under complex conditions. Despite their growing adoption, a comprehensive comparison between classical and learnable feature matching methods for the specific task of semantic 3D building camera-to-model matching is still missing. This submission systematically evaluates the effectiveness of different feature-matching techniques in visual localization using textured CityGML LoD2 models. We use standard benchmark datasets (HPatches, MegaDepth-1500) and custom datasets consisting of facade textures and corresponding camera images (terrestrial and drone). For the latter, we evaluate the achievable accuracy of the absolute pose estimated using a Perspective-n-Point (PnP) algorithm, with geometric ground truth derived from geo-referenced trajectory data. The results indicate that the learnable feature matching methods vastly outperform traditional approaches regarding accuracy and robustness on our challenging custom datasets with zero to 12 RANSAC-inliers and zero to 0.16 area under the curve. We believe that this work will foster the development of model-based visual localization methods. Link to the code: https://github.com/simBauer/To\_Glue\_or\_not\_to\_Glue
TUM2TWIN: Introducing the Large-Scale Multimodal Urban Digital Twin Benchmark Dataset
May 13, 2025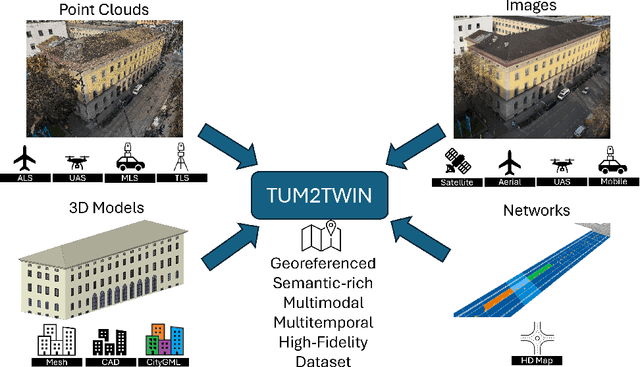
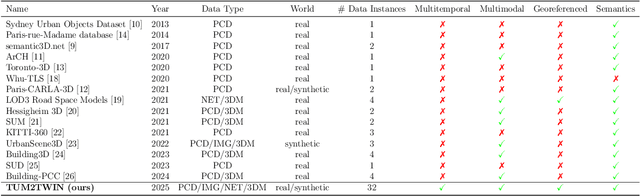

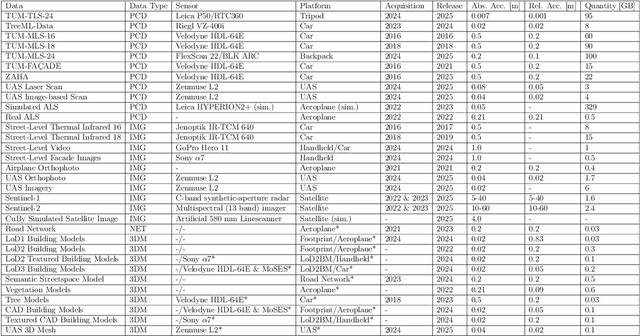
Urban Digital Twins (UDTs) have become essential for managing cities and integrating complex, heterogeneous data from diverse sources. Creating UDTs involves challenges at multiple process stages, including acquiring accurate 3D source data, reconstructing high-fidelity 3D models, maintaining models' updates, and ensuring seamless interoperability to downstream tasks. Current datasets are usually limited to one part of the processing chain, hampering comprehensive UDTs validation. To address these challenges, we introduce the first comprehensive multimodal Urban Digital Twin benchmark dataset: TUM2TWIN. This dataset includes georeferenced, semantically aligned 3D models and networks along with various terrestrial, mobile, aerial, and satellite observations boasting 32 data subsets over roughly 100,000 $m^2$ and currently 767 GB of data. By ensuring georeferenced indoor-outdoor acquisition, high accuracy, and multimodal data integration, the benchmark supports robust analysis of sensors and the development of advanced reconstruction methods. Additionally, we explore downstream tasks demonstrating the potential of TUM2TWIN, including novel view synthesis of NeRF and Gaussian Splatting, solar potential analysis, point cloud semantic segmentation, and LoD3 building reconstruction. We are convinced this contribution lays a foundation for overcoming current limitations in UDT creation, fostering new research directions and practical solutions for smarter, data-driven urban environments. The project is available under: https://tum2t.win
OPAL: Visibility-aware LiDAR-to-OpenStreetMap Place Recognition via Adaptive Radial Fusion
Apr 30, 2025LiDAR place recognition is a critical capability for autonomous navigation and cross-modal localization in large-scale outdoor environments. Existing approaches predominantly depend on pre-built 3D dense maps or aerial imagery, which impose significant storage overhead and lack real-time adaptability. In this paper, we propose OPAL, a novel network for LiDAR place recognition that leverages OpenStreetMap (OSM) as a lightweight and up-to-date prior. Our key innovation lies in bridging the domain disparity between sparse LiDAR scans and structured OSM data through two carefully designed components. First, a cross-modal visibility mask that identifies maximal observable regions from both modalities to guide feature learning. Second, an adaptive radial fusion module that dynamically consolidates radial features into discriminative global descriptors. Extensive experiments on the KITTI and KITTI-360 datasets demonstrate OPAL's superiority, achieving 15.98% higher recall at @1m threshold for top-1 retrieved matches, along with 12x faster inference speed compared to the state-of-the-art approach. Code and datasets will be publicly available.
RADLER: Radar Object Detection Leveraging Semantic 3D City Models and Self-Supervised Radar-Image Learning
Apr 16, 2025Semantic 3D city models are worldwide easy-accessible, providing accurate, object-oriented, and semantic-rich 3D priors. To date, their potential to mitigate the noise impact on radar object detection remains under-explored. In this paper, we first introduce a unique dataset, RadarCity, comprising 54K synchronized radar-image pairs and semantic 3D city models. Moreover, we propose a novel neural network, RADLER, leveraging the effectiveness of contrastive self-supervised learning (SSL) and semantic 3D city models to enhance radar object detection of pedestrians, cyclists, and cars. Specifically, we first obtain the robust radar features via a SSL network in the radar-image pretext task. We then use a simple yet effective feature fusion strategy to incorporate semantic-depth features from semantic 3D city models. Having prior 3D information as guidance, RADLER obtains more fine-grained details to enhance radar object detection. We extensively evaluate RADLER on the collected RadarCity dataset and demonstrate average improvements of 5.46% in mean avarage precision (mAP) and 3.51% in mean avarage recall (mAR) over previous radar object detection methods. We believe this work will foster further research on semantic-guided and map-supported radar object detection. Our project page is publicly available athttps://gpp-communication.github.io/RADLER .
Texture2LoD3: Enabling LoD3 Building Reconstruction With Panoramic Images
Apr 07, 2025
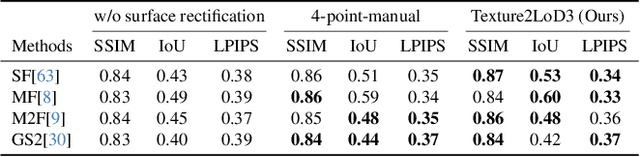
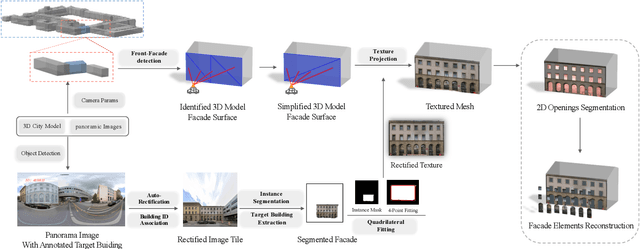

Despite recent advancements in surface reconstruction, Level of Detail (LoD) 3 building reconstruction remains an unresolved challenge. The main issue pertains to the object-oriented modelling paradigm, which requires georeferencing, watertight geometry, facade semantics, and low-poly representation -- Contrasting unstructured mesh-oriented models. In Texture2LoD3, we introduce a novel method leveraging the ubiquity of 3D building model priors and panoramic street-level images, enabling the reconstruction of LoD3 building models. We observe that prior low-detail building models can serve as valid planar targets for ortho-rectifying street-level panoramic images. Moreover, deploying segmentation on accurately textured low-level building surfaces supports maintaining essential georeferencing, watertight geometry, and low-poly representation for LoD3 reconstruction. In the absence of LoD3 validation data, we additionally introduce the ReLoD3 dataset, on which we experimentally demonstrate that our method leads to improved facade segmentation accuracy by 11% and can replace costly manual projections. We believe that Texture2LoD3 can scale the adoption of LoD3 models, opening applications in estimating building solar potential or enhancing autonomous driving simulations. The project website, code, and data are available here: https://wenzhaotang.github.io/Texture2LoD3/.
CDGS: Confidence-Aware Depth Regularization for 3D Gaussian Splatting
Feb 20, 20253D Gaussian Splatting (3DGS) has shown significant advantages in novel view synthesis (NVS), particularly in achieving high rendering speeds and high-quality results. However, its geometric accuracy in 3D reconstruction remains limited due to the lack of explicit geometric constraints during optimization. This paper introduces CDGS, a confidence-aware depth regularization approach developed to enhance 3DGS. We leverage multi-cue confidence maps of monocular depth estimation and sparse Structure-from-Motion depth to adaptively adjust depth supervision during the optimization process. Our method demonstrates improved geometric detail preservation in early training stages and achieves competitive performance in both NVS quality and geometric accuracy. Experiments on the publicly available Tanks and Temples benchmark dataset show that our method achieves more stable convergence behavior and more accurate geometric reconstruction results, with improvements of up to 2.31 dB in PSNR for NVS and consistently lower geometric errors in M3C2 distance metrics. Notably, our method reaches comparable F-scores to the original 3DGS with only 50% of the training iterations. We expect this work will facilitate the development of efficient and accurate 3D reconstruction systems for real-world applications such as digital twin creation, heritage preservation, or forestry applications.