 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObject Pose Transformer: Unifying Unseen Object Pose Estimation
Mar 24, 2026Learning model-free object pose estimation for unseen instances remains a fundamental challenge in 3D vision. Existing methods typically fall into two disjoint paradigms: category-level approaches predict absolute poses in a canonical space but rely on predefined taxonomies, while relative pose methods estimate cross-view transformations but cannot recover single-view absolute pose. In this work, we propose Object Pose Transformer (\ours{}), a unified feed-forward framework that bridges these paradigms through task factorization within a single model. \ours{} jointly predicts depth, point maps, camera parameters, and normalized object coordinates (NOCS) from RGB inputs, enabling both category-level absolute SA(3) pose and unseen-object relative SE(3) pose. Our approach leverages contrastive object-centric latent embeddings for canonicalization without requiring semantic labels at inference time, and uses point maps as a camera-space representation to enable multi-view relative geometric reasoning. Through cross-frame feature interaction and shared object embeddings, our model leverages relative geometric consistency across views to improve absolute pose estimation, reducing ambiguity in single-view predictions. Furthermore, \ours{} is camera-agnostic, learning camera intrinsics on-the-fly and supporting optional depth input for metric-scale recovery, while remaining fully functional in RGB-only settings. Extensive experiments on diverse benchmarks (NOCS, HouseCat6D, Omni6DPose, Toyota-Light) demonstrate state-of-the-art performance in both absolute and relative pose estimation tasks within a single unified architecture.
Generative 6D Pose Estimation via Conditional Flow Matching
Feb 23, 2026Existing methods for instance-level 6D pose estimation typically rely on neural networks that either directly regress the pose in $\mathrm{SE}(3)$ or estimate it indirectly via local feature matching. The former struggle with object symmetries, while the latter fail in the absence of distinctive local features. To overcome these limitations, we propose a novel formulation of 6D pose estimation as a conditional flow matching problem in $\mathbb{R}^3$. We introduce Flose, a generative method that infers object poses via a denoising process conditioned on local features. While prior approaches based on conditional flow matching perform denoising solely based on geometric guidance, Flose integrates appearance-based semantic features to mitigate ambiguities caused by object symmetries. We further incorporate RANSAC-based registration to handle outliers. We validate Flose on five datasets from the established BOP benchmark. Flose outperforms prior methods with an average improvement of +4.5 Average Recall. Project Website : https://tev-fbk.github.io/Flose/
SurgGoal: Rethinking Surgical Planning Evaluation via Goal-Satisfiability
Jan 15, 2026Surgical planning integrates visual perception, long-horizon reasoning, and procedural knowledge, yet it remains unclear whether current evaluation protocols reliably assess vision-language models (VLMs) in safety-critical settings. Motivated by a goal-oriented view of surgical planning, we define planning correctness via phase-goal satisfiability, where plan validity is determined by expert-defined surgical rules. Based on this definition, we introduce a multicentric meta-evaluation benchmark with valid procedural variations and invalid plans containing order and content errors. Using this benchmark, we show that sequence similarity metrics systematically misjudge planning quality, penalizing valid plans while failing to identify invalid ones. We therefore adopt a rule-based goal-satisfiability metric as a high-precision meta-evaluation reference to assess Video-LLMs under progressively constrained settings, revealing failures due to perception errors and under-constrained reasoning. Structural knowledge consistently improves performance, whereas semantic guidance alone is unreliable and benefits larger models only when combined with structural constraints.
Texture2LoD3: Enabling LoD3 Building Reconstruction With Panoramic Images
Apr 07, 2025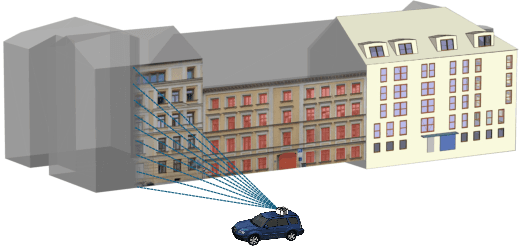
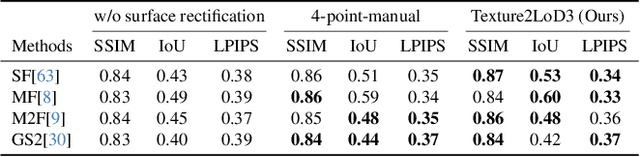
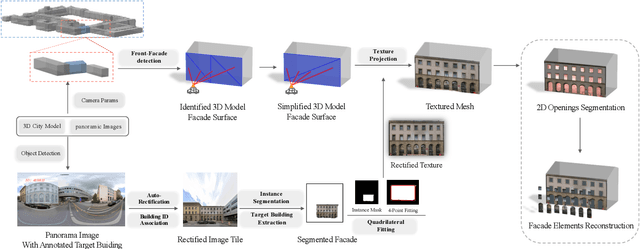

Despite recent advancements in surface reconstruction, Level of Detail (LoD) 3 building reconstruction remains an unresolved challenge. The main issue pertains to the object-oriented modelling paradigm, which requires georeferencing, watertight geometry, facade semantics, and low-poly representation -- Contrasting unstructured mesh-oriented models. In Texture2LoD3, we introduce a novel method leveraging the ubiquity of 3D building model priors and panoramic street-level images, enabling the reconstruction of LoD3 building models. We observe that prior low-detail building models can serve as valid planar targets for ortho-rectifying street-level panoramic images. Moreover, deploying segmentation on accurately textured low-level building surfaces supports maintaining essential georeferencing, watertight geometry, and low-poly representation for LoD3 reconstruction. In the absence of LoD3 validation data, we additionally introduce the ReLoD3 dataset, on which we experimentally demonstrate that our method leads to improved facade segmentation accuracy by 11% and can replace costly manual projections. We believe that Texture2LoD3 can scale the adoption of LoD3 models, opening applications in estimating building solar potential or enhancing autonomous driving simulations. The project website, code, and data are available here: https://wenzhaotang.github.io/Texture2LoD3/.
GCE-Pose: Global Context Enhancement for Category-level Object Pose Estimation
Feb 06, 2025A key challenge in model-free category-level pose estimation is the extraction of contextual object features that generalize across varying instances within a specific category. Recent approaches leverage foundational features to capture semantic and geometry cues from data. However, these approaches fail under partial visibility. We overcome this with a first-complete-then-aggregate strategy for feature extraction utilizing class priors. In this paper, we present GCE-Pose, a method that enhances pose estimation for novel instances by integrating category-level global context prior. GCE-Pose performs semantic shape reconstruction with a proposed Semantic Shape Reconstruction (SSR) module. Given an unseen partial RGB-D object instance, our SSR module reconstructs the instance's global geometry and semantics by deforming category-specific 3D semantic prototypes through a learned deep Linear Shape Model. We further introduce a Global Context Enhanced (GCE) feature fusion module that effectively fuses features from partial RGB-D observations and the reconstructed global context. Extensive experiments validate the impact of our global context prior and the effectiveness of the GCE fusion module, demonstrating that GCE-Pose significantly outperforms existing methods on challenging real-world datasets HouseCat6D and NOCS-REAL275. Our project page is available at https://colin-de.github.io/GCE-Pose/.
DynSUP: Dynamic Gaussian Splatting from An Unposed Image Pair
Dec 01, 2024
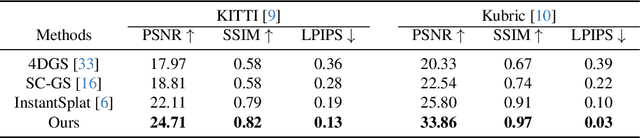
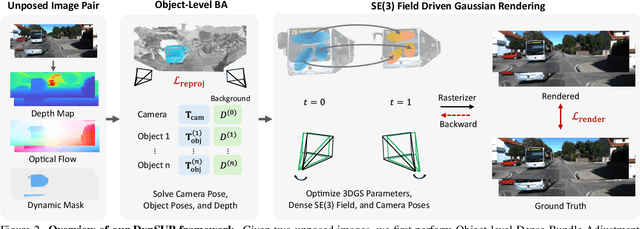
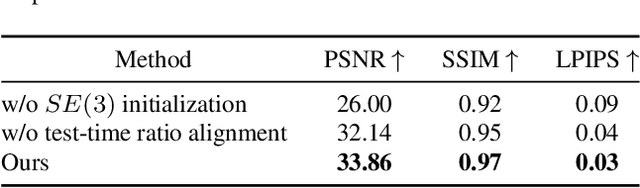
Recent advances in 3D Gaussian Splatting have shown promising results. Existing methods typically assume static scenes and/or multiple images with prior poses. Dynamics, sparse views, and unknown poses significantly increase the problem complexity due to insufficient geometric constraints. To overcome this challenge, we propose a method that can use only two images without prior poses to fit Gaussians in dynamic environments. To achieve this, we introduce two technical contributions. First, we propose an object-level two-view bundle adjustment. This strategy decomposes dynamic scenes into piece-wise rigid components, and jointly estimates the camera pose and motions of dynamic objects. Second, we design an SE(3) field-driven Gaussian training method. It enables fine-grained motion modeling through learnable per-Gaussian transformations. Our method leads to high-fidelity novel view synthesis of dynamic scenes while accurately preserving temporal consistency and object motion. Experiments on both synthetic and real-world datasets demonstrate that our method significantly outperforms state-of-the-art approaches designed for the cases of static environments, multiple images, and/or known poses. Our project page is available at https://colin-de.github.io/DynSUP/.
SCRREAM : SCan, Register, REnder And Map:A Framework for Annotating Accurate and Dense 3D Indoor Scenes with a Benchmark
Oct 30, 2024



Traditionally, 3d indoor datasets have generally prioritized scale over ground-truth accuracy in order to obtain improved generalization. However, using these datasets to evaluate dense geometry tasks, such as depth rendering, can be problematic as the meshes of the dataset are often incomplete and may produce wrong ground truth to evaluate the details. In this paper, we propose SCRREAM, a dataset annotation framework that allows annotation of fully dense meshes of objects in the scene and registers camera poses on the real image sequence, which can produce accurate ground truth for both sparse 3D as well as dense 3D tasks. We show the details of the dataset annotation pipeline and showcase four possible variants of datasets that can be obtained from our framework with example scenes, such as indoor reconstruction and SLAM, scene editing & object removal, human reconstruction and 6d pose estimation. Recent pipelines for indoor reconstruction and SLAM serve as new benchmarks. In contrast to previous indoor dataset, our design allows to evaluate dense geometry tasks on eleven sample scenes against accurately rendered ground truth depth maps.
Deep unrolling Shrinkage Network for Dynamic MR imaging
Jul 19, 2023Deep unrolling networks that utilize sparsity priors have achieved great success in dynamic magnetic resonance (MR) imaging. The convolutional neural network (CNN) is usually utilized to extract the transformed domain, and then the soft thresholding (ST) operator is applied to the CNN-transformed data to enforce the sparsity priors. However, the ST operator is usually constrained to be the same across all channels of the CNN-transformed data. In this paper, we propose a novel operator, called soft thresholding with channel attention (AST), that learns the threshold for each channel. In particular, we put forward a novel deep unrolling shrinkage network (DUS-Net) by unrolling the alternating direction method of multipliers (ADMM) for optimizing the transformed $l_1$ norm dynamic MR reconstruction model. Experimental results on an open-access dynamic cine MR dataset demonstrate that the proposed DUS-Net outperforms the state-of-the-art methods. The source code is available at \url{https://github.com/yhao-z/DUS-Net}.