 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCRREAM : SCan, Register, REnder And Map:A Framework for Annotating Accurate and Dense 3D Indoor Scenes with a Benchmark
Oct 30, 2024



Traditionally, 3d indoor datasets have generally prioritized scale over ground-truth accuracy in order to obtain improved generalization. However, using these datasets to evaluate dense geometry tasks, such as depth rendering, can be problematic as the meshes of the dataset are often incomplete and may produce wrong ground truth to evaluate the details. In this paper, we propose SCRREAM, a dataset annotation framework that allows annotation of fully dense meshes of objects in the scene and registers camera poses on the real image sequence, which can produce accurate ground truth for both sparse 3D as well as dense 3D tasks. We show the details of the dataset annotation pipeline and showcase four possible variants of datasets that can be obtained from our framework with example scenes, such as indoor reconstruction and SLAM, scene editing & object removal, human reconstruction and 6d pose estimation. Recent pipelines for indoor reconstruction and SLAM serve as new benchmarks. In contrast to previous indoor dataset, our design allows to evaluate dense geometry tasks on eleven sample scenes against accurately rendered ground truth depth maps.
Deformable 3D Gaussian Splatting for Animatable Human Avatars
Dec 22, 2023



Recent advances in neural radiance fields enable novel view synthesis of photo-realistic images in dynamic settings, which can be applied to scenarios with human animation. Commonly used implicit backbones to establish accurate models, however, require many input views and additional annotations such as human masks, UV maps and depth maps. In this work, we propose ParDy-Human (Parameterized Dynamic Human Avatar), a fully explicit approach to construct a digital avatar from as little as a single monocular sequence. ParDy-Human introduces parameter-driven dynamics into 3D Gaussian Splatting where 3D Gaussians are deformed by a human pose model to animate the avatar. Our method is composed of two parts: A first module that deforms canonical 3D Gaussians according to SMPL vertices and a consecutive module that further takes their designed joint encodings and predicts per Gaussian deformations to deal with dynamics beyond SMPL vertex deformations. Images are then synthesized by a rasterizer. ParDy-Human constitutes an explicit model for realistic dynamic human avatars which requires significantly fewer training views and images. Our avatars learning is free of additional annotations such as masks and can be trained with variable backgrounds while inferring full-resolution images efficiently even on consumer hardware. We provide experimental evidence to show that ParDy-Human outperforms state-of-the-art methods on ZJU-MoCap and THUman4.0 datasets both quantitatively and visually.
View-to-Label: Multi-View Consistency for Self-Supervised 3D Object Detection
May 29, 2023
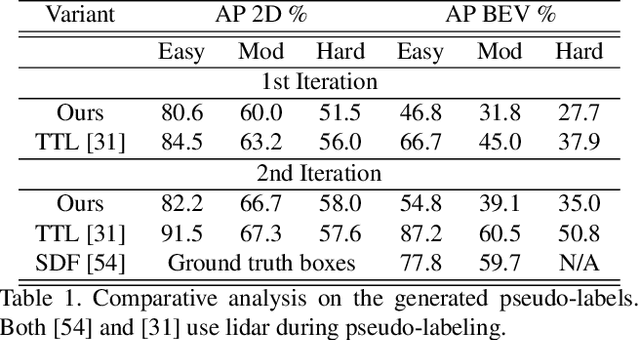
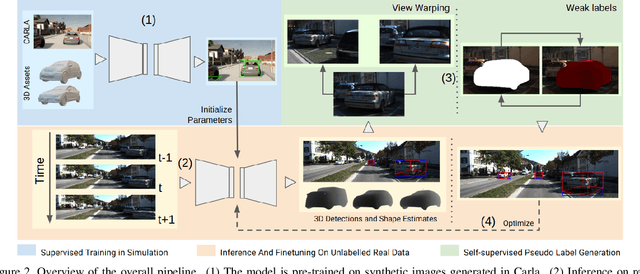

For autonomous vehicles, driving safely is highly dependent on the capability to correctly perceive the environment in 3D space, hence the task of 3D object detection represents a fundamental aspect of perception. While 3D sensors deliver accurate metric perception, monocular approaches enjoy cost and availability advantages that are valuable in a wide range of applications. Unfortunately, training monocular methods requires a vast amount of annotated data. Interestingly, self-supervised approaches have recently been successfully applied to ease the training process and unlock access to widely available unlabelled data. While related research leverages different priors including LIDAR scans and stereo images, such priors again limit usability. Therefore, in this work, we propose a novel approach to self-supervise 3D object detection purely from RGB sequences alone, leveraging multi-view constraints and weak labels. Our experiments on KITTI 3D dataset demonstrate performance on par with state-of-the-art self-supervised methods using LIDAR scans or stereo images.
On the Importance of Accurate Geometry Data for Dense 3D Vision Tasks
Mar 26, 2023



Learning-based methods to solve dense 3D vision problems typically train on 3D sensor data. The respectively used principle of measuring distances provides advantages and drawbacks. These are typically not compared nor discussed in the literature due to a lack of multi-modal datasets. Texture-less regions are problematic for structure from motion and stereo, reflective material poses issues for active sensing, and distances for translucent objects are intricate to measure with existing hardware. Training on inaccurate or corrupt data induces model bias and hampers generalisation capabilities. These effects remain unnoticed if the sensor measurement is considered as ground truth during the evaluation. This paper investigates the effect of sensor errors for the dense 3D vision tasks of depth estimation and reconstruction. We rigorously show the significant impact of sensor characteristics on the learned predictions and notice generalisation issues arising from various technologies in everyday household environments. For evaluation, we introduce a carefully designed dataset\footnote{dataset available at https://github.com/Junggy/HAMMER-dataset} comprising measurements from commodity sensors, namely D-ToF, I-ToF, passive/active stereo, and monocular RGB+P. Our study quantifies the considerable sensor noise impact and paves the way to improved dense vision estimates and targeted data fusion.
Is my Depth Ground-Truth Good Enough? HAMMER -- Highly Accurate Multi-Modal Dataset for DEnse 3D Scene Regression
May 09, 2022


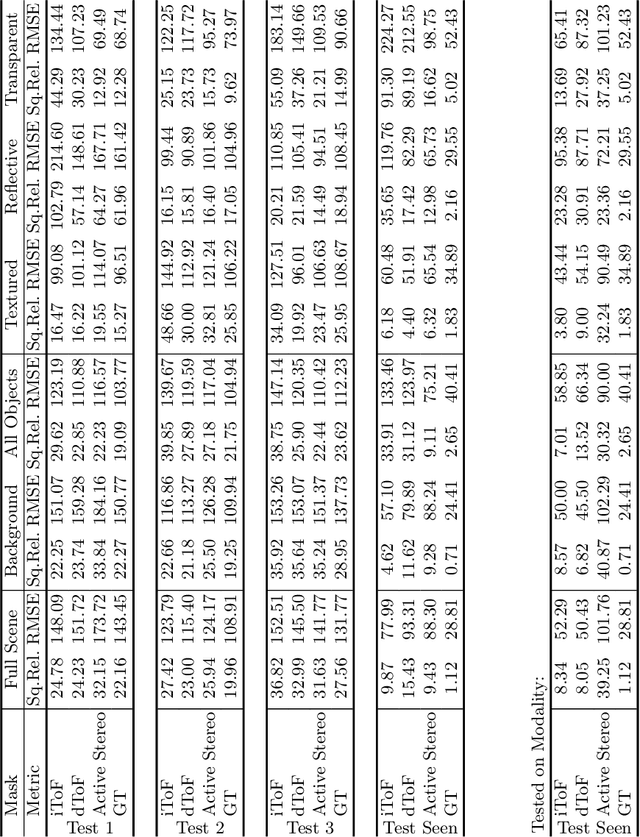
Depth estimation is a core task in 3D computer vision. Recent methods investigate the task of monocular depth trained with various depth sensor modalities. Every sensor has its advantages and drawbacks caused by the nature of estimates. In the literature, mostly mean average error of the depth is investigated and sensor capabilities are typically not discussed. Especially indoor environments, however, pose challenges for some devices. Textureless regions pose challenges for structure from motion, reflective materials are problematic for active sensing, and distances for translucent material are intricate to measure with existing sensors. This paper proposes HAMMER, a dataset comprising depth estimates from multiple commonly used sensors for indoor depth estimation, namely ToF, stereo, structured light together with monocular RGB+P data. We construct highly reliable ground truth depth maps with the help of 3D scanners and aligned renderings. A popular depth estimators is trained on this data and typical depth senosors. The estimates are extensively analyze on different scene structures. We notice generalization issues arising from various sensor technologies in household environments with challenging but everyday scene content. HAMMER, which we make publicly available, provides a reliable base to pave the way to targeted depth improvements and sensor fusion approaches.
Time-to-Label: Temporal Consistency for Self-Supervised Monocular 3D Object Detection
Mar 04, 2022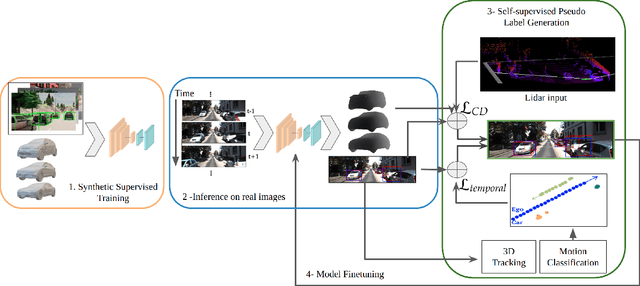
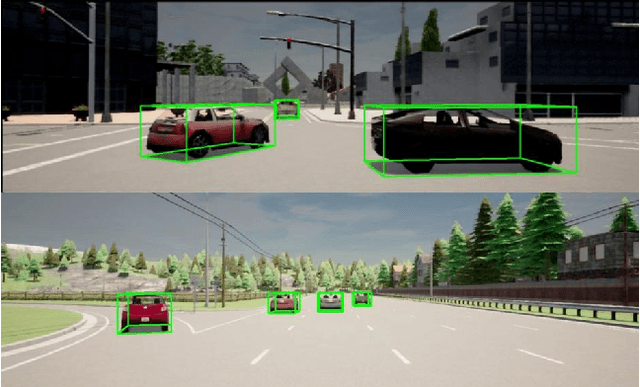
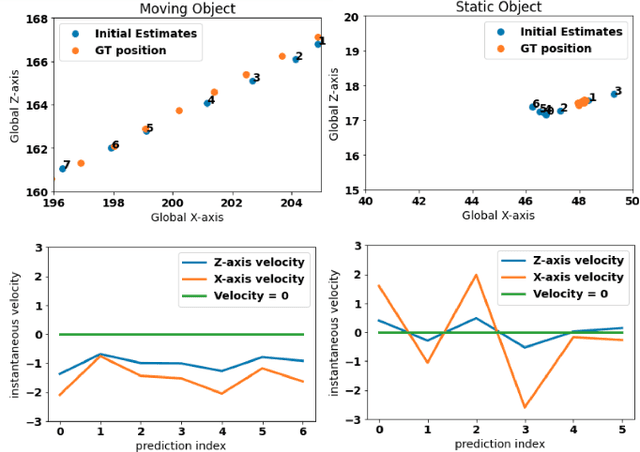

Monocular 3D object detection continues to attract attention due to the cost benefits and wider availability of RGB cameras. Despite the recent advances and the ability to acquire data at scale, annotation cost and complexity still limit the size of 3D object detection datasets in the supervised settings. Self-supervised methods, on the other hand, aim at training deep networks relying on pretext tasks or various consistency constraints. Moreover, other 3D perception tasks (such as depth estimation) have shown the benefits of temporal priors as a self-supervision signal. In this work, we argue that the temporal consistency on the level of object poses, provides an important supervision signal given the strong prior on physical motion. Specifically, we propose a self-supervised loss which uses this consistency, in addition to render-and-compare losses, to refine noisy pose predictions and derive high-quality pseudo labels. To assess the effectiveness of the proposed method, we finetune a synthetically trained monocular 3D object detection model using the pseudo-labels that we generated on real data. Evaluation on the standard KITTI3D benchmark demonstrates that our method reaches competitive performance compared to other monocular self-supervised and supervised methods.
Wild ToFu: Improving Range and Quality of Indirect Time-of-Flight Depth with RGB Fusion in Challenging Environments
Dec 07, 2021



Indirect Time-of-Flight (I-ToF) imaging is a widespread way of depth estimation for mobile devices due to its small size and affordable price. Previous works have mainly focused on quality improvement for I-ToF imaging especially curing the effect of Multi Path Interference (MPI). These investigations are typically done in specifically constrained scenarios at close distance, indoors and under little ambient light. Surprisingly little work has investigated I-ToF quality improvement in real-life scenarios where strong ambient light and far distances pose difficulties due to an extreme amount of induced shot noise and signal sparsity, caused by the attenuation with limited sensor power and light scattering. In this work, we propose a new learning based end-to-end depth prediction network which takes noisy raw I-ToF signals as well as an RGB image and fuses their latent representation based on a multi step approach involving both implicit and explicit alignment to predict a high quality long range depth map aligned to the RGB viewpoint. We test our approach on challenging real-world scenes and show more than 40% RMSE improvement on the final depth map compared to the baseline approach.
Adversarial Domain Feature Adaptation for Bronchoscopic Depth Estimation
Sep 24, 2021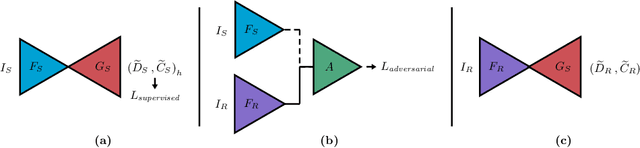
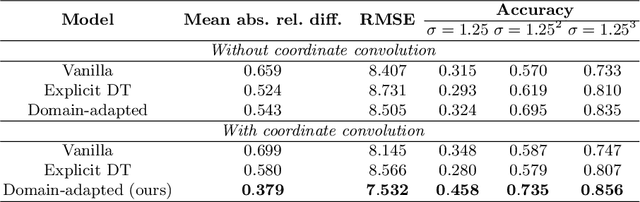
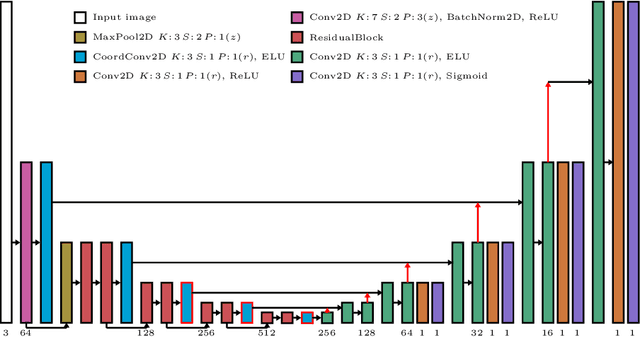
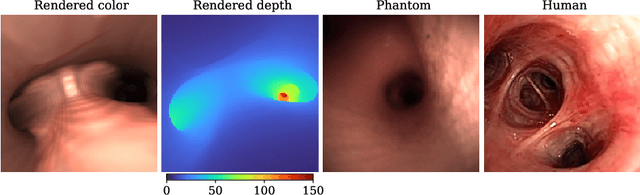
Depth estimation from monocular images is an important task in localization and 3D reconstruction pipelines for bronchoscopic navigation. Various supervised and self-supervised deep learning-based approaches have proven themselves on this task for natural images. However, the lack of labeled data and the bronchial tissue's feature-scarce texture make the utilization of these methods ineffective on bronchoscopic scenes. In this work, we propose an alternative domain-adaptive approach. Our novel two-step structure first trains a depth estimation network with labeled synthetic images in a supervised manner; then adopts an unsupervised adversarial domain feature adaptation scheme to improve the performance on real images. The results of our experiments show that the proposed method improves the network's performance on real images by a considerable margin and can be employed in 3D reconstruction pipelines.
RGB-D SLAM with Structural Regularities
Oct 15, 2020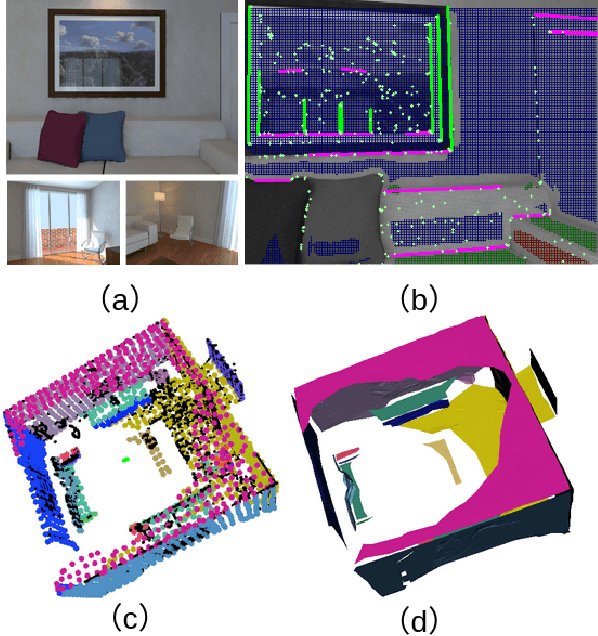
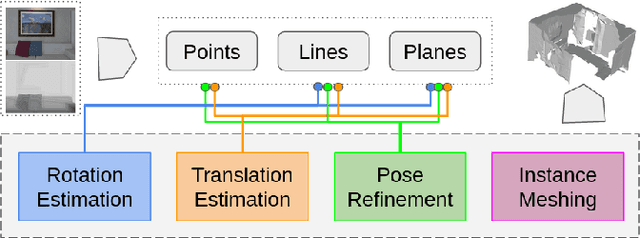
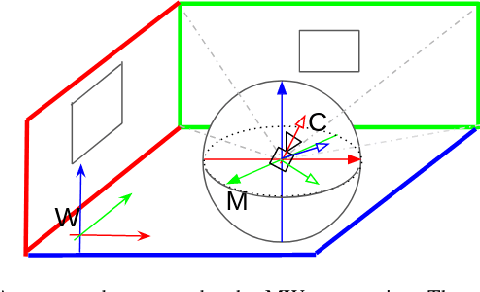
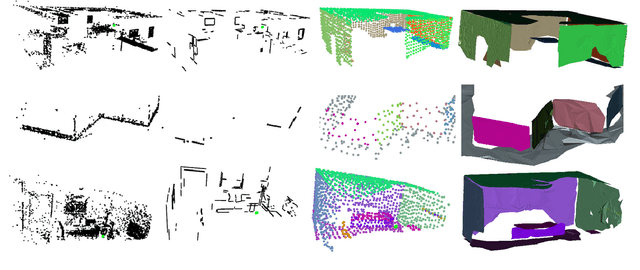
This work proposes a RGB-D SLAM system specifically designed for structured environments and aimed at improved tracking and mapping accuracy by relying on geometric features that are extracted from the surrounding. Structured environments offer, in addition to points, also an abundance of geometrical features such as lines and planes, which we exploit to design both the tracking and mapping components of our SLAM system. For the tracking part, we explore geometric relationships between these features based on the assumption of a Manhattan World (MW). We propose a decoupling-refinement method based on points, lines, and planes, as well as the use of Manhattan relationships in an additional pose refinement module. For the mapping part, different levels of maps from sparse to dense are reconstructed at a low computational cost. We propose an instance-wise meshing strategy to build a dense map by meshing plane instances independently. The overall performance in terms of pose estimation and reconstruction is evaluated on public benchmarks and shows improved performance compared to state-of-the-art methods. We plan to publicly release the code of our SLAM framework.
Structure-SLAM: Low-Drift Monocular SLAM in Indoor Environments
Aug 05, 2020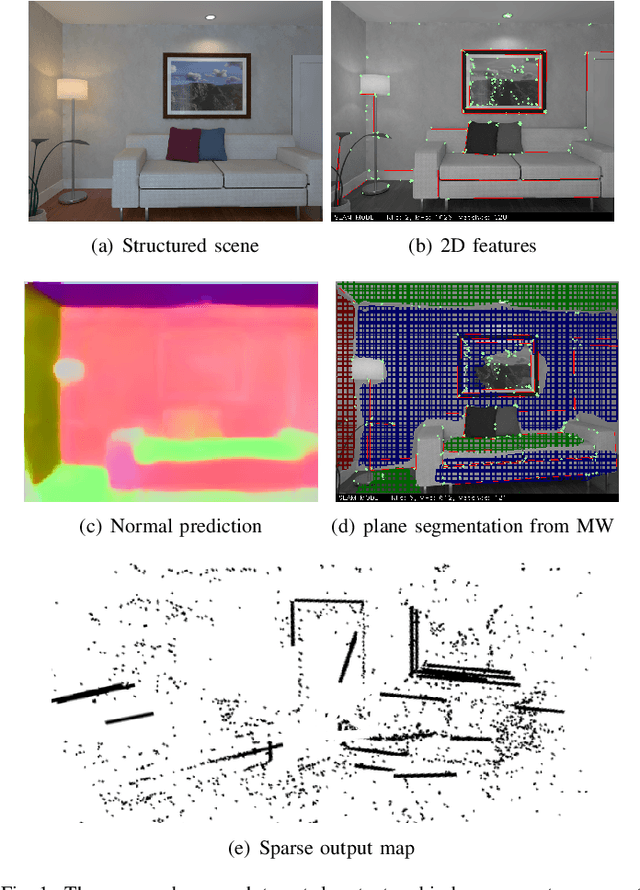

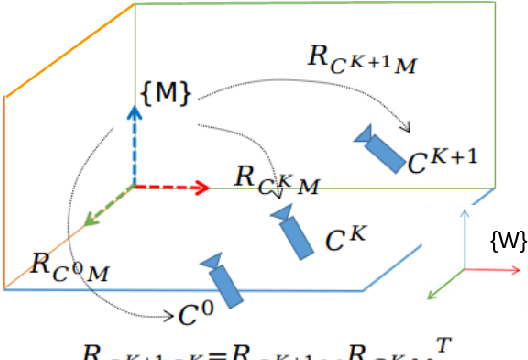

In this paper a low-drift monocular SLAM method is proposed targeting indoor scenarios, where monocular SLAM often fails due to the lack of textured surfaces. Our approach decouples rotation and translation estimation of the tracking process to reduce the long-term drift in indoor environments. In order to take full advantage of the available geometric information in the scene, surface normals are predicted by a convolutional neural network from each input RGB image in real-time. First, a drift-free rotation is estimated based on lines and surface normals using spherical mean-shift clustering, leveraging the weak Manhattan World assumption. Then translation is computed from point and line features. Finally, the estimated poses are refined with a map-to-frame optimization strategy. The proposed method outperforms the state of the art on common SLAM benchmarks such as ICL-NUIM and TUM RGB-D.