 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyper-Skin: A Hyperspectral Dataset for Reconstructing Facial Skin-Spectra from RGB Images
Oct 27, 2023



We introduce Hyper-Skin, a hyperspectral dataset covering wide range of wavelengths from visible (VIS) spectrum (400nm - 700nm) to near-infrared (NIR) spectrum (700nm - 1000nm), uniquely designed to facilitate research on facial skin-spectra reconstruction. By reconstructing skin spectra from RGB images, our dataset enables the study of hyperspectral skin analysis, such as melanin and hemoglobin concentrations, directly on the consumer device. Overcoming limitations of existing datasets, Hyper-Skin consists of diverse facial skin data collected with a pushbroom hyperspectral camera. With 330 hyperspectral cubes from 51 subjects, the dataset covers the facial skin from different angles and facial poses. Each hyperspectral cube has dimensions of 1024$\times$1024$\times$448, resulting in millions of spectra vectors per image. The dataset, carefully curated in adherence to ethical guidelines, includes paired hyperspectral images and synthetic RGB images generated using real camera responses. We demonstrate the efficacy of our dataset by showcasing skin spectra reconstruction using state-of-the-art models on 31 bands of hyperspectral data resampled in the VIS and NIR spectrum. This Hyper-Skin dataset would be a valuable resource to NeurIPS community, encouraging the development of novel algorithms for skin spectral reconstruction while fostering interdisciplinary collaboration in hyperspectral skin analysis related to cosmetology and skin's well-being. Instructions to request the data and the related benchmarking codes are publicly available at: \url{https://github.com/hyperspectral-skin/Hyper-Skin-2023}.
On the Importance of Accurate Geometry Data for Dense 3D Vision Tasks
Mar 26, 2023



Learning-based methods to solve dense 3D vision problems typically train on 3D sensor data. The respectively used principle of measuring distances provides advantages and drawbacks. These are typically not compared nor discussed in the literature due to a lack of multi-modal datasets. Texture-less regions are problematic for structure from motion and stereo, reflective material poses issues for active sensing, and distances for translucent objects are intricate to measure with existing hardware. Training on inaccurate or corrupt data induces model bias and hampers generalisation capabilities. These effects remain unnoticed if the sensor measurement is considered as ground truth during the evaluation. This paper investigates the effect of sensor errors for the dense 3D vision tasks of depth estimation and reconstruction. We rigorously show the significant impact of sensor characteristics on the learned predictions and notice generalisation issues arising from various technologies in everyday household environments. For evaluation, we introduce a carefully designed dataset\footnote{dataset available at https://github.com/Junggy/HAMMER-dataset} comprising measurements from commodity sensors, namely D-ToF, I-ToF, passive/active stereo, and monocular RGB+P. Our study quantifies the considerable sensor noise impact and paves the way to improved dense vision estimates and targeted data fusion.
Is my Depth Ground-Truth Good Enough? HAMMER -- Highly Accurate Multi-Modal Dataset for DEnse 3D Scene Regression
May 09, 2022


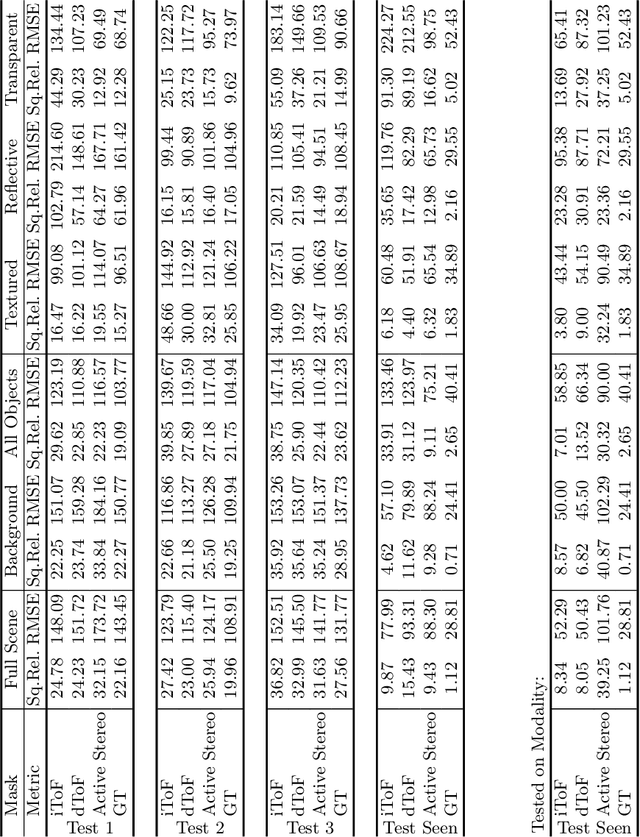
Depth estimation is a core task in 3D computer vision. Recent methods investigate the task of monocular depth trained with various depth sensor modalities. Every sensor has its advantages and drawbacks caused by the nature of estimates. In the literature, mostly mean average error of the depth is investigated and sensor capabilities are typically not discussed. Especially indoor environments, however, pose challenges for some devices. Textureless regions pose challenges for structure from motion, reflective materials are problematic for active sensing, and distances for translucent material are intricate to measure with existing sensors. This paper proposes HAMMER, a dataset comprising depth estimates from multiple commonly used sensors for indoor depth estimation, namely ToF, stereo, structured light together with monocular RGB+P data. We construct highly reliable ground truth depth maps with the help of 3D scanners and aligned renderings. A popular depth estimators is trained on this data and typical depth senosors. The estimates are extensively analyze on different scene structures. We notice generalization issues arising from various sensor technologies in household environments with challenging but everyday scene content. HAMMER, which we make publicly available, provides a reliable base to pave the way to targeted depth improvements and sensor fusion approaches.
HDD-Net: Hybrid Detector Descriptor with Mutual Interactive Learning
May 12, 2020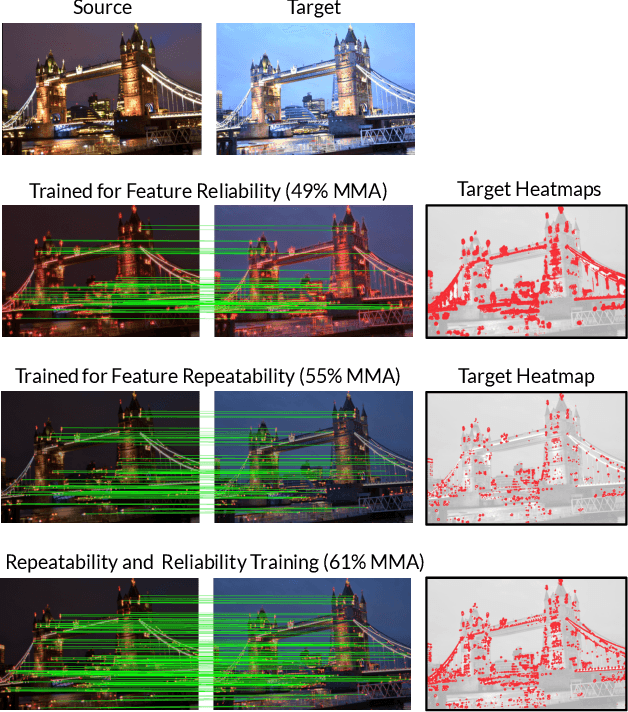


Local feature extraction remains an active research area due to the advances in fields such as SLAM, 3D reconstructions, or AR applications. The success in these applications relies on the performance of the feature detector and descriptor. While the detector-descriptor interaction of most methods is based on unifying in single network detections and descriptors, we propose a method that treats both extractions independently and focuses on their interaction in the learning process rather than by parameter sharing. We formulate the classical hard-mining triplet loss as a new detector optimisation term to refine candidate positions based on the descriptor map. We propose a dense descriptor that uses a multi-scale approach and a hybrid combination of hand-crafted and learned features to obtain rotation and scale robustness by design. We evaluate our method extensively on different benchmarks and show improvements over the state of the art in terms of image matching on HPatches and 3D reconstruction quality while keeping on par on camera localisation tasks.
Learning to Assign Orientations to Feature Points
Apr 11, 2016


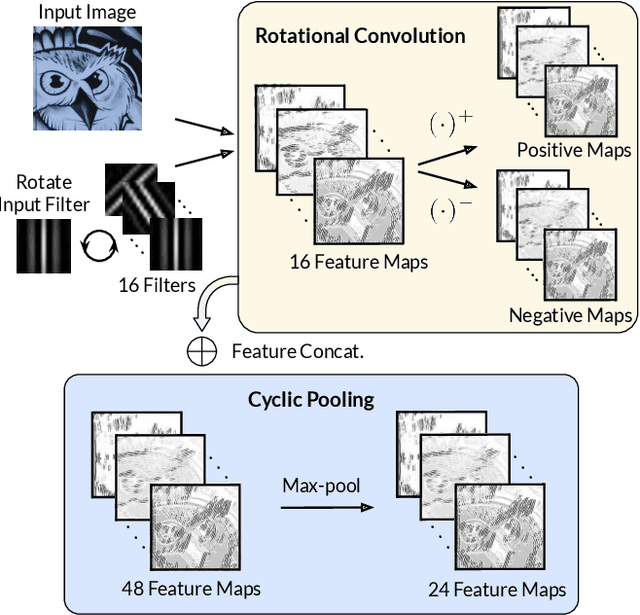
We show how to train a Convolutional Neural Network to assign a canonical orientation to feature points given an image patch centered on the feature point. Our method improves feature point matching upon the state-of-the art and can be used in conjunction with any existing rotation sensitive descriptors. To avoid the tedious and almost impossible task of finding a target orientation to learn, we propose to use Siamese networks which implicitly find the optimal orientations during training. We also propose a new type of activation function for Neural Networks that generalizes the popular ReLU, maxout, and PReLU activation functions. This novel activation performs better for our task. We validate the effectiveness of our method extensively with four existing datasets, including two non-planar datasets, as well as our own dataset. We show that we outperform the state-of-the-art without the need of retraining for each dataset.
TILDE: A Temporally Invariant Learned DEtector
Mar 12, 2015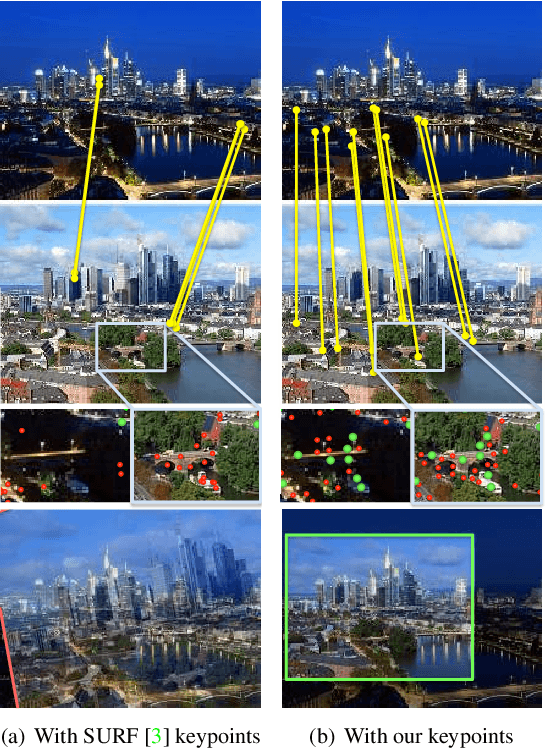
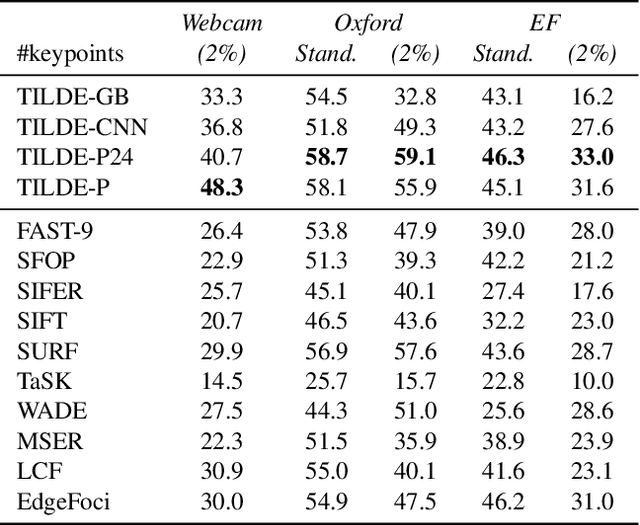
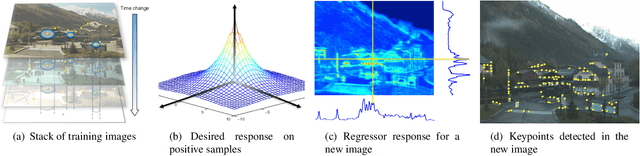

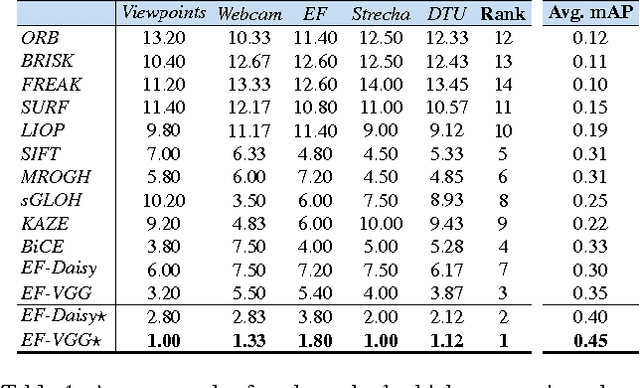
We introduce a learning-based approach to detect repeatable keypoints under drastic imaging changes of weather and lighting conditions to which state-of-the-art keypoint detectors are surprisingly sensitive. We first identify good keypoint candidates in multiple training images taken from the same viewpoint. We then train a regressor to predict a score map whose maxima are those points so that they can be found by simple non-maximum suppression. As there are no standard datasets to test the influence of these kinds of changes, we created our own, which we will make publicly available. We will show that our method significantly outperforms the state-of-the-art methods in such challenging conditions, while still achieving state-of-the-art performance on the untrained standard Oxford dataset.