 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFG-Portrait: 3D Flow Guided Editable Portrait Animation
Mar 24, 2026Motion transfer from the driving to the source portrait remains a key challenge in the portrait animation. Current diffusion-based approaches condition only on the driving motion, which fails to capture source-to-driving correspondences and consequently yields suboptimal motion transfer. Although flow estimation provides an alternative, predicting dense correspondences from 2D input is ill-posed and often yields inaccurate animation. We address this problem by introducing 3D flows, a learning-free and geometry-driven motion correspondence directly computed from parametric 3D head models. To integrate this 3D prior into diffusion model, we introduce 3D flow encoding to query potential 3D flows for each target pixel to indicate its displacement back to the source location. To obtain 3D flows aligned with 2D motion changes, we further propose depth-guided sampling to accurately locate the corresponding 3D points for each pixel. Beyond high-fidelity portrait animation, our model further supports user-specified editing of facial expression and head pose. Extensive experiments demonstrate the superiority of our method on consistent driving motion transfer as well as faithful source identity preservation.
Color When It Counts: Grayscale-Guided Online Triggering for Always-On Streaming Video Sensing
Mar 23, 2026Always-on sensing is essential for next-generation edge/wearable AI systems, yet continuous high-fidelity RGB video capture remains prohibitively expensive for resource-constrained mobile and edge platforms. We present a new paradigm for efficient streaming video understanding: grayscale-always, color-on-demand. Through preliminary studies, we discover that color is not always necessary. Sparse RGB frames suffice for comparable performance when temporal structure is preserved via continuous grayscale streams. Building on this insight, we propose ColorTrigger, an online training-free trigger that selectively activates color capture based on windowed grayscale affinity analysis. Designed for real-time edge deployment, ColorTrigger uses lightweight quadratic programming to detect chromatic redundancy causally, coupled with credit-budgeted control and dynamic token routing to jointly reduce sensing and inference costs. On streaming video understanding benchmarks, ColorTrigger achieves 91.6% of full-color baseline performance while using only 8.1% RGB frames, demonstrating substantial color redundancy in natural videos and enabling practical always-on video sensing on resource-constrained devices.
Relax Forcing: Relaxed KV-Memory for Consistent Long Video Generation
Mar 22, 2026Autoregressive (AR) video diffusion has recently emerged as a promising paradigm for long video generation, enabling causal synthesis beyond the limits of bidirectional models. To address training-inference mismatch, a series of self-forcing strategies have been proposed to improve rollout stability by conditioning the model on its own predictions during training. While these approaches substantially mitigate exposure bias, extending generation to minute-scale horizons remains challenging due to progressive temporal degradation. In this work, we show that this limitation is not primarily caused by insufficient memory, but by how temporal memory is utilised during inference. Through empirical analysis, we find that increasing memory does not consistently improve long-horizon generation, and that the temporal placement of historical context significantly influences motion dynamics while leaving visual quality largely unchanged. These findings suggest that temporal memory should not be treated as a homogeneous buffer. Motivated by this insight, we introduce Relax Forcing, a structured temporal memory mechanism for AR diffusion. Instead of attending to the dense generated history, Relax Forcing decomposes temporal context into three functional roles: Sink for global stability, Tail for short-term continuity, and dynamically selected History for structural motion guidance, and selectively incorporates only the most relevant past information. This design mitigates error accumulation during extrapolation while preserving motion evolution. Experiments on VBench-Long demonstrate that Relax Forcing improves motion dynamics and overall temporal consistency while reducing attention overhead. Our results suggest that structured temporal memory is essential for scalable long video generation, complementing existing forcing-based training strategies.
Diffusion-Based Makeup Transfer with Facial Region-Aware Makeup Features
Mar 20, 2026Current diffusion-based makeup transfer methods commonly use the makeup information encoded by off-the-shelf foundation models (e.g., CLIP) as condition to preserve the makeup style of reference image in the generation. Although effective, these works mainly have two limitations: (1) foundation models pre-trained for generic tasks struggle to capture makeup styles; (2) the makeup features of reference image are injected to the diffusion denoising model as a whole for global makeup transfer, overlooking the facial region-aware makeup features (i.e., eyes, mouth, etc) and limiting the regional controllability for region-specific makeup transfer. To address these, in this work, we propose Facial Region-Aware Makeup features (FRAM), which has two stages: (1) makeup CLIP fine-tuning; (2) identity and facial region-aware makeup injection. For makeup CLIP fine-tuning, unlike prior works using off-the-shelf CLIP, we synthesize annotated makeup style data using GPT-o3 and text-driven image editing model, and then use the data to train a makeup CLIP encoder through self-supervised and image-text contrastive learning. For identity and facial region-aware makeup injection, we construct before-and-after makeup image pairs from the edited images in stage 1 and then use them to learn to inject identity of source image and makeup of reference image to the diffusion denoising model for makeup transfer. Specifically, we use learnable tokens to query the makeup CLIP encoder to extract facial region-aware makeup features for makeup injection, which is learned via an attention loss to enable regional control. As for identity injection, we use a ControlNet Union to encode source image and its 3D mesh simultaneously. The experimental results verify the superiority of our regional controllability and our makeup transfer performance.
LatSearch: Latent Reward-Guided Search for Faster Inference-Time Scaling in Video Diffusion
Mar 15, 2026The recent success of inference-time scaling in large language models has inspired similar explorations in video diffusion. In particular, motivated by the existence of "golden noise" that enhances video quality, prior work has attempted to improve inference by optimising or searching for better initial noise. However, these approaches have notable limitations: they either rely on priors imposed at the beginning of noise sampling or on rewards evaluated only on the denoised and decoded videos. This leads to error accumulation, delayed and sparse reward signals, and prohibitive computational cost, which prevents the use of stronger search algorithms. Crucially, stronger search algorithms are precisely what could unlock substantial gains in controllability, sample efficiency and generation quality for video diffusion, provided their computational cost can be reduced. To fill in this gap, we enable efficient inference-time scaling for video diffusion through latent reward guidance, which provides intermediate, informative and efficient feedback along the denoising trajectory. We introduce a latent reward model that scores partially denoised latents at arbitrary timesteps with respect to visual quality, motion quality, and text alignment. Building on this model, we propose LatSearch, a novel inference-time search mechanism that performs Reward-Guided Resampling and Pruning (RGRP). In the resampling stage, candidates are sampled according to reward-normalised probabilities to reduce over-reliance on the reward model. In the pruning stage, applied at the final scheduled step, only the candidate with the highest cumulative reward is retained, improving both quality and efficiency. We evaluate LatSearch on the VBench-2.0 benchmark and demonstrate that it consistently improves video generation across multiple evaluation dimensions compared to the baseline Wan2.1 model.
Egocentric Co-Pilot: Web-Native Smart-Glasses Agents for Assistive Egocentric AI
Mar 01, 2026What if accessing the web did not require a screen, a stable desk, or even free hands? For people navigating crowded cities, living with low vision, or experiencing cognitive overload, smart glasses coupled with AI agents could turn the web into an always-on assistive layer over daily life. We present Egocentric Co-Pilot, a web-native neuro-symbolic framework that runs on smart glasses and uses a Large Language Model (LLM) to orchestrate a toolbox of perception, reasoning, and web tools. An egocentric reasoning core combines Temporal Chain-of-Thought with Hierarchical Context Compression to support long-horizon question answering and decision support over continuous first-person video, far beyond a single model's context window. Additionally, a lightweight multimodal intent layer maps noisy speech and gaze into structured commands. We further implement and evaluate a cloud-native WebRTC pipeline integrating streaming speech, video, and control messages into a unified channel for smart glasses and browsers. In parallel, we deploy an on-premise WebSocket baseline, exposing concrete trade-offs between local inference and cloud offloading in terms of latency, mobility, and resource use. Experiments on Egolife and HD-EPIC demonstrate competitive or state-of-the-art egocentric QA performance, and a human-in-the-loop study on smart glasses shows higher task completion and user satisfaction than leading commercial baselines. Taken together, these results indicate that web-connected egocentric co-pilots can be a practical path toward more accessible, context-aware assistance in everyday life. By grounding operation in web-native communication primitives and modular, auditable tool use, Egocentric Co-Pilot offers a concrete blueprint for assistive, always-on web agents that support education, accessibility, and social inclusion for people who may benefit most from contextual, egocentric AI.
EgoGraph: Temporal Knowledge Graph for Egocentric Video Understanding
Feb 27, 2026Ultra-long egocentric videos spanning multiple days present significant challenges for video understanding. Existing approaches still rely on fragmented local processing and limited temporal modeling, restricting their ability to reason over such extended sequences. To address these limitations, we introduce EgoGraph, a training-free and dynamic knowledge-graph construction framework that explicitly encodes long-term, cross-entity dependencies in egocentric video streams. EgoGraph employs a novel egocentric schema that unifies the extraction and abstraction of core entities, such as people, objects, locations, and events, and structurally reasons about their attributes and interactions, yielding a significantly richer and more coherent semantic representation than traditional clip-based video models. Crucially, we develop a temporal relational modeling strategy that captures temporal dependencies across entities and accumulates stable long-term memory over multiple days, enabling complex temporal reasoning. Extensive experiments on the EgoLifeQA and EgoR1-bench benchmarks demonstrate that EgoGraph achieves state-of-the-art performance on long-term video question answering, validating its effectiveness as a new paradigm for ultra-long egocentric video understanding.
Optimizing Multimodal LLMs for Egocentric Video Understanding: A Solution for the HD-EPIC VQA Challenge
Jan 15, 2026Multimodal Large Language Models (MLLMs) struggle with complex video QA benchmarks like HD-EPIC VQA due to ambiguous queries/options, poor long-range temporal reasoning, and non-standardized outputs. We propose a framework integrating query/choice pre-processing, domain-specific Qwen2.5-VL fine-tuning, a novel Temporal Chain-of-Thought (T-CoT) prompting for multi-step reasoning, and robust post-processing. This system achieves 41.6% accuracy on HD-EPIC VQA, highlighting the need for holistic pipeline optimization in demanding video understanding. Our code, fine-tuned models are available at https://github.com/YoungSeng/Egocentric-Co-Pilot.
Plug-and-Play Clarifier: A Zero-Shot Multimodal Framework for Egocentric Intent Disambiguation
Nov 12, 2025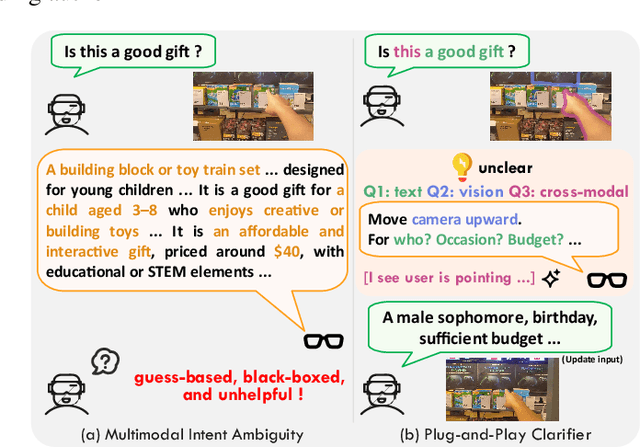
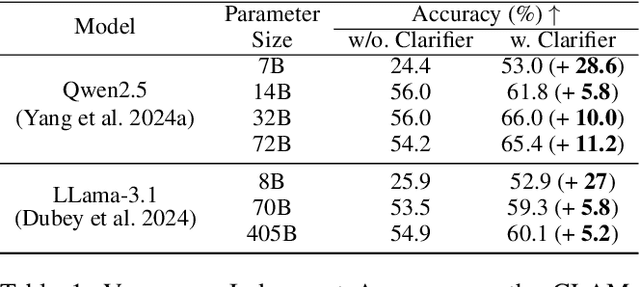
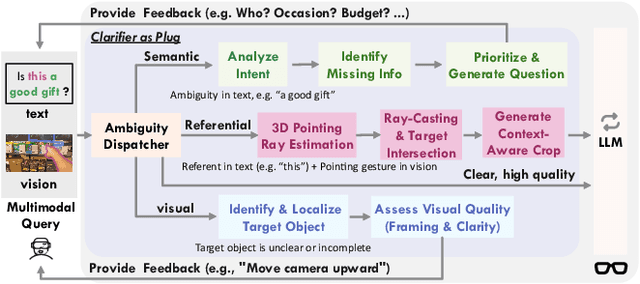
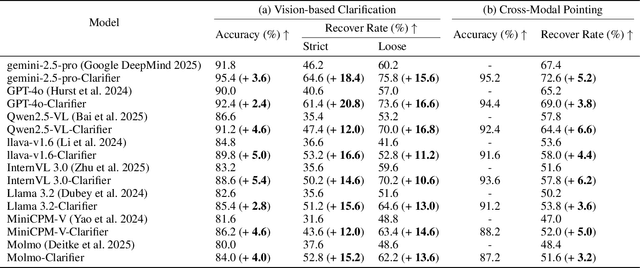
The performance of egocentric AI agents is fundamentally limited by multimodal intent ambiguity. This challenge arises from a combination of underspecified language, imperfect visual data, and deictic gestures, which frequently leads to task failure. Existing monolithic Vision-Language Models (VLMs) struggle to resolve these multimodal ambiguous inputs, often failing silently or hallucinating responses. To address these ambiguities, we introduce the Plug-and-Play Clarifier, a zero-shot and modular framework that decomposes the problem into discrete, solvable sub-tasks. Specifically, our framework consists of three synergistic modules: (1) a text clarifier that uses dialogue-driven reasoning to interactively disambiguate linguistic intent, (2) a vision clarifier that delivers real-time guidance feedback, instructing users to adjust their positioning for improved capture quality, and (3) a cross-modal clarifier with grounding mechanism that robustly interprets 3D pointing gestures and identifies the specific objects users are pointing to. Extensive experiments demonstrate that our framework improves the intent clarification performance of small language models (4--8B) by approximately 30%, making them competitive with significantly larger counterparts. We also observe consistent gains when applying our framework to these larger models. Furthermore, our vision clarifier increases corrective guidance accuracy by over 20%, and our cross-modal clarifier improves semantic answer accuracy for referential grounding by 5%. Overall, our method provides a plug-and-play framework that effectively resolves multimodal ambiguity and significantly enhances user experience in egocentric interaction.
Unlocking the Potential of Diffusion Priors in Blind Face Restoration
Aug 12, 2025
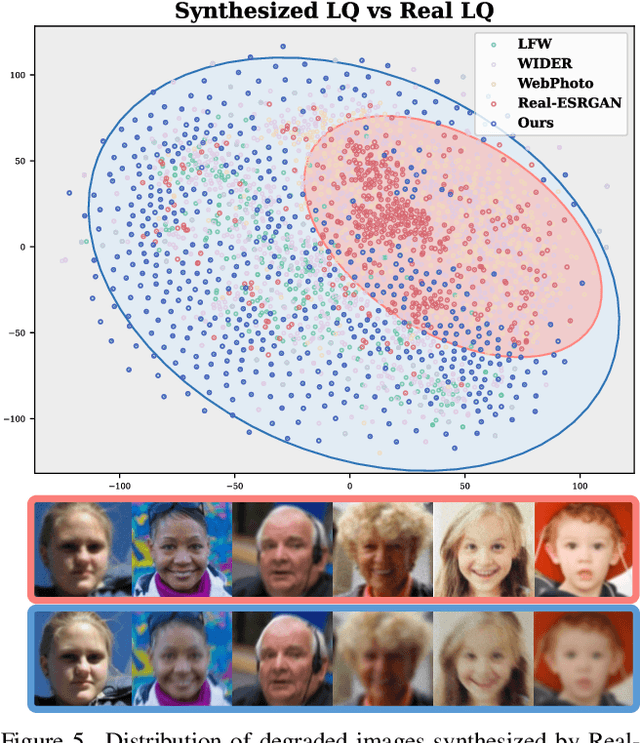
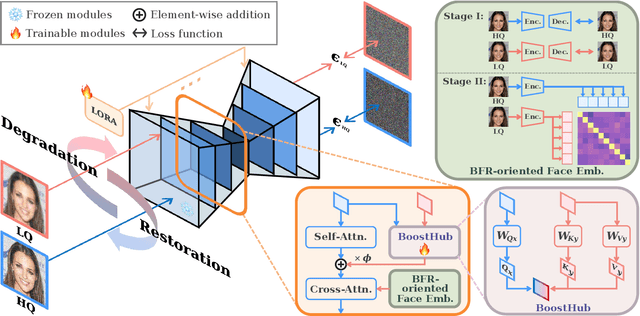
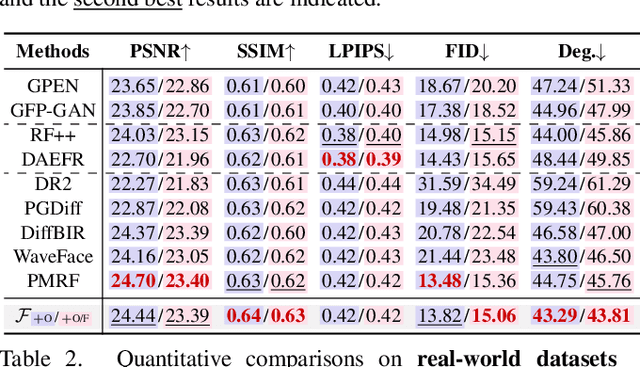
Although diffusion prior is rising as a powerful solution for blind face restoration (BFR), the inherent gap between the vanilla diffusion model and BFR settings hinders its seamless adaptation. The gap mainly stems from the discrepancy between 1) high-quality (HQ) and low-quality (LQ) images and 2) synthesized and real-world images. The vanilla diffusion model is trained on images with no or less degradations, whereas BFR handles moderately to severely degraded images. Additionally, LQ images used for training are synthesized by a naive degradation model with limited degradation patterns, which fails to simulate complex and unknown degradations in real-world scenarios. In this work, we use a unified network FLIPNET that switches between two modes to resolve specific gaps. In Restoration mode, the model gradually integrates BFR-oriented features and face embeddings from LQ images to achieve authentic and faithful face restoration. In Degradation mode, the model synthesizes real-world like degraded images based on the knowledge learned from real-world degradation datasets. Extensive evaluations on benchmark datasets show that our model 1) outperforms previous diffusion prior based BFR methods in terms of authenticity and fidelity, and 2) outperforms the naive degradation model in modeling the real-world degradations.