 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlocking the Potential of Diffusion Priors in Blind Face Restoration
Aug 12, 2025
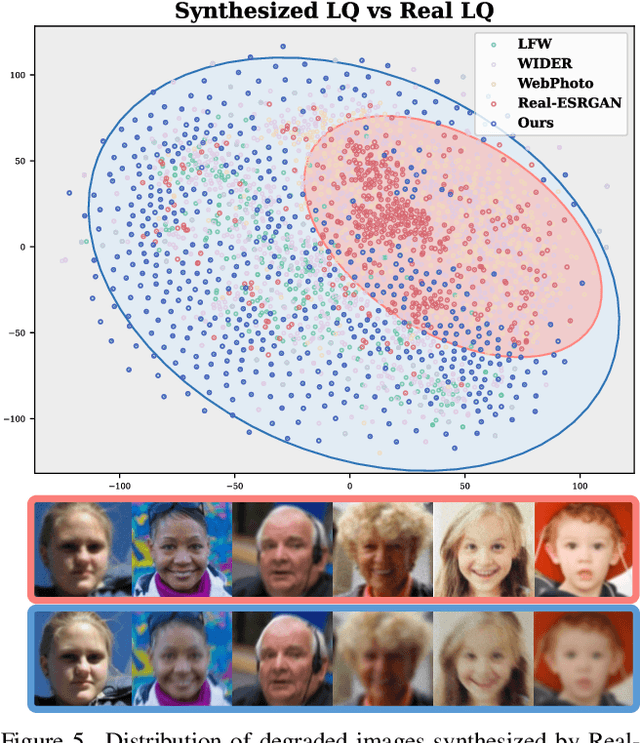
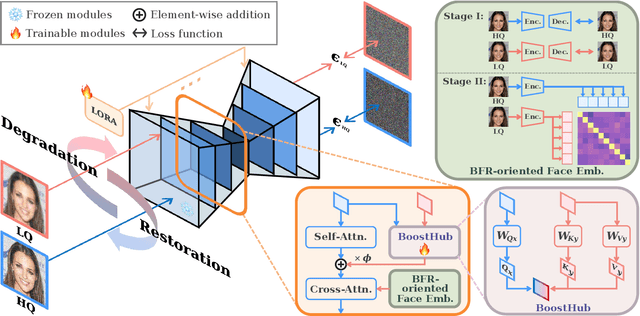
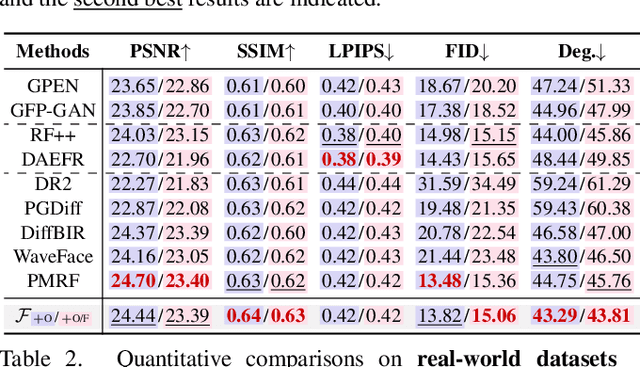
Although diffusion prior is rising as a powerful solution for blind face restoration (BFR), the inherent gap between the vanilla diffusion model and BFR settings hinders its seamless adaptation. The gap mainly stems from the discrepancy between 1) high-quality (HQ) and low-quality (LQ) images and 2) synthesized and real-world images. The vanilla diffusion model is trained on images with no or less degradations, whereas BFR handles moderately to severely degraded images. Additionally, LQ images used for training are synthesized by a naive degradation model with limited degradation patterns, which fails to simulate complex and unknown degradations in real-world scenarios. In this work, we use a unified network FLIPNET that switches between two modes to resolve specific gaps. In Restoration mode, the model gradually integrates BFR-oriented features and face embeddings from LQ images to achieve authentic and faithful face restoration. In Degradation mode, the model synthesizes real-world like degraded images based on the knowledge learned from real-world degradation datasets. Extensive evaluations on benchmark datasets show that our model 1) outperforms previous diffusion prior based BFR methods in terms of authenticity and fidelity, and 2) outperforms the naive degradation model in modeling the real-world degradations.
Semi-supervised Semantic Segmentation for Remote Sensing Images via Multi-scale Uncertainty Consistency and Cross-Teacher-Student Attention
Jan 18, 2025Semi-supervised learning offers an appealing solution for remote sensing (RS) image segmentation to relieve the burden of labor-intensive pixel-level labeling. However, RS images pose unique challenges, including rich multi-scale features and high inter-class similarity. To address these problems, this paper proposes a novel semi-supervised Multi-Scale Uncertainty and Cross-Teacher-Student Attention (MUCA) model for RS image semantic segmentation tasks. Specifically, MUCA constrains the consistency among feature maps at different layers of the network by introducing a multi-scale uncertainty consistency regularization. It improves the multi-scale learning capability of semi-supervised algorithms on unlabeled data. Additionally, MUCA utilizes a Cross-Teacher-Student attention mechanism to guide the student network, guiding the student network to construct more discriminative feature representations through complementary features from the teacher network. This design effectively integrates weak and strong augmentations (WA and SA) to further boost segmentation performance. To verify the effectiveness of our model, we conduct extensive experiments on ISPRS-Potsdam and LoveDA datasets. The experimental results show the superiority of our method over state-of-the-art semi-supervised methods. Notably, our model excels in distinguishing highly similar objects, showcasing its potential for advancing semi-supervised RS image segmentation tasks.
Virtual Category Learning: A Semi-Supervised Learning Method for Dense Prediction with Extremely Limited Labels
Dec 02, 2023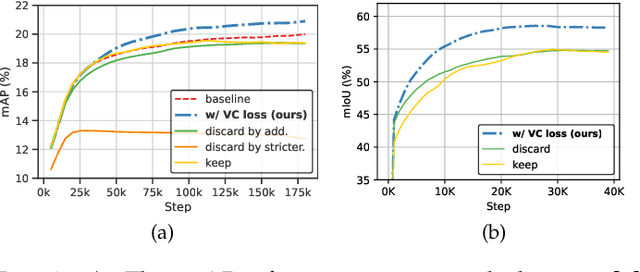

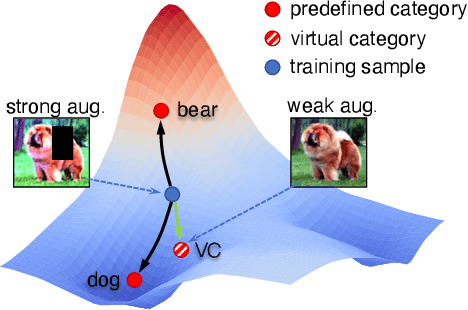

Due to the costliness of labelled data in real-world applications, semi-supervised learning, underpinned by pseudo labelling, is an appealing solution. However, handling confusing samples is nontrivial: discarding valuable confusing samples would compromise the model generalisation while using them for training would exacerbate the issue of confirmation bias caused by the resulting inevitable mislabelling. To solve this problem, this paper proposes to use confusing samples proactively without label correction. Specifically, a Virtual Category (VC) is assigned to each confusing sample in such a way that it can safely contribute to the model optimisation even without a concrete label. This provides an upper bound for inter-class information sharing capacity, which eventually leads to a better embedding space. Extensive experiments on two mainstream dense prediction tasks -- semantic segmentation and object detection, demonstrate that the proposed VC learning significantly surpasses the state-of-the-art, especially when only very few labels are available. Our intriguing findings highlight the usage of VC learning in dense vision tasks.
Semi-supervised Object Detection via Virtual Category Learning
Jul 07, 2022
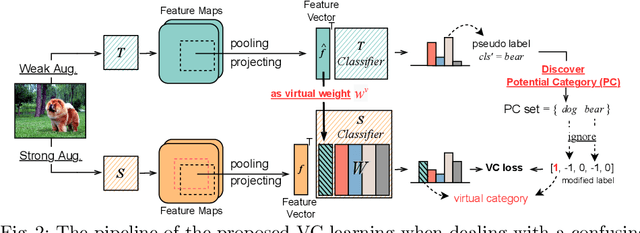

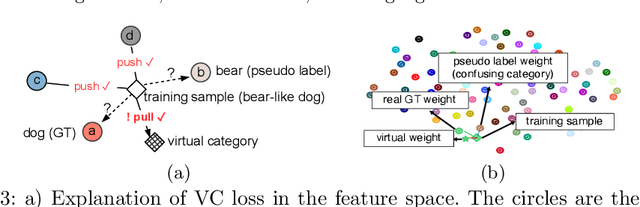
Due to the costliness of labelled data in real-world applications, semi-supervised object detectors, underpinned by pseudo labelling, are appealing. However, handling confusing samples is nontrivial: discarding valuable confusing samples would compromise the model generalisation while using them for training would exacerbate the confirmation bias issue caused by inevitable mislabelling. To solve this problem, this paper proposes to use confusing samples proactively without label correction. Specifically, a virtual category (VC) is assigned to each confusing sample such that they can safely contribute to the model optimisation even without a concrete label. It is attributed to specifying the embedding distance between the training sample and the virtual category as the lower bound of the inter-class distance. Moreover, we also modify the localisation loss to allow high-quality boundaries for location regression. Extensive experiments demonstrate that the proposed VC learning significantly surpasses the state-of-the-art, especially with small amounts of available labels.
Gaussian Dynamic Convolution for Efficient Single-Image Segmentation
May 23, 2021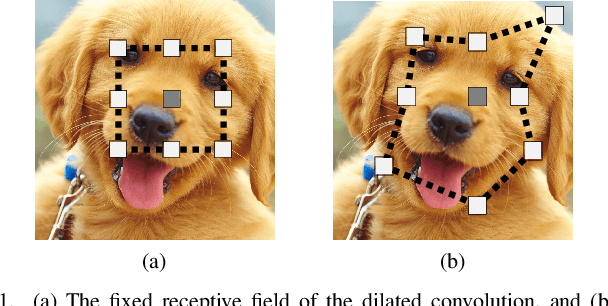
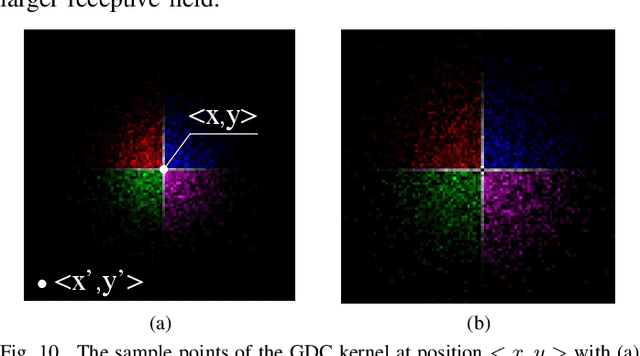

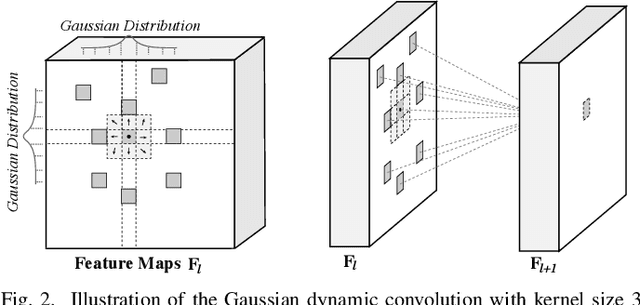
Interactive single-image segmentation is ubiquitous in the scientific and commercial imaging software. In this work, we focus on the single-image segmentation problem only with some seeds such as scribbles. Inspired by the dynamic receptive field in the human being's visual system, we propose the Gaussian dynamic convolution (GDC) to fast and efficiently aggregate the contextual information for neural networks. The core idea is randomly selecting the spatial sampling area according to the Gaussian distribution offsets. Our GDC can be easily used as a module to build lightweight or complex segmentation networks. We adopt the proposed GDC to address the typical single-image segmentation tasks. Furthermore, we also build a Gaussian dynamic pyramid Pooling to show its potential and generality in common semantic segmentation. Experiments demonstrate that the GDC outperforms other existing convolutions on three benchmark segmentation datasets including Pascal-Context, Pascal-VOC 2012, and Cityscapes. Additional experiments are also conducted to illustrate that the GDC can produce richer and more vivid features compared with other convolutions. In general, our GDC is conducive to the convolutional neural networks to form an overall impression of the image.
High-Order Paired-ASPP Networks for Semantic Segmenation
Feb 18, 2020



Current semantic segmentation models only exploit first-order statistics, while rarely exploring high-order statistics. However, common first-order statistics are insufficient to support a solid unanimous representation. In this paper, we propose High-Order Paired-ASPP Network to exploit high-order statistics from various feature levels. The network first introduces a High-Order Representation module to extract the contextual high-order information from all stages of the backbone. They can provide more semantic clues and discriminative information than the first-order ones. Besides, a Paired-ASPP module is proposed to embed high-order statistics of the early stages into the last stage. It can further preserve the boundary-related and spatial context in the low-level features for final prediction. Our experiments show that the high-order statistics significantly boost the performance on confusing objects. Our method achieves competitive performance without bells and whistles on three benchmarks, i.e, Cityscapes, ADE20K and Pascal-Context with the mIoU of 81.6%, 45.3% and 52.9%.
Few-shot Learning for Domain-specfic Fine-grained Image Classfication
Jul 23, 2019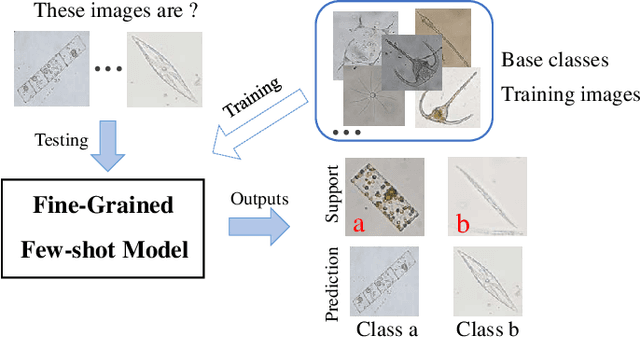
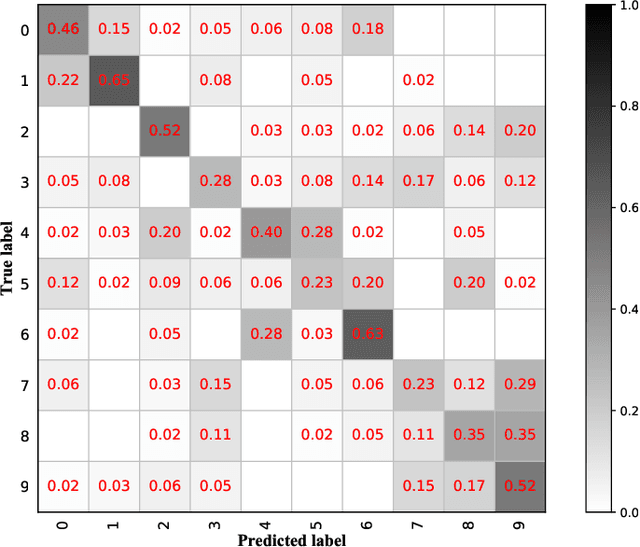
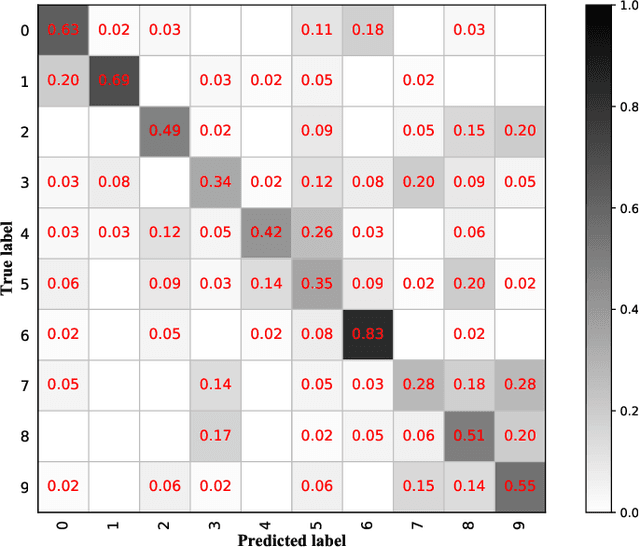
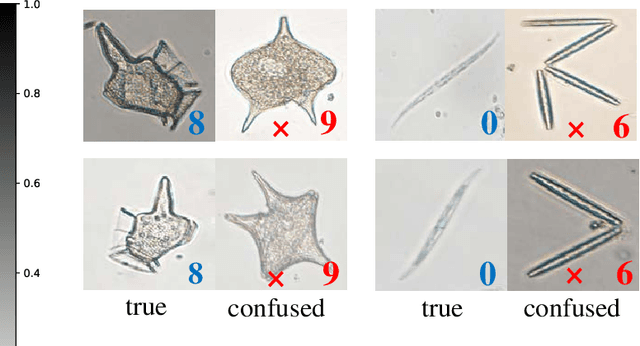
Learning to recognize novel visual categories from a few examples is a challenging task for machines in real-world applications. In contrast, humans have the ability to discriminate even similar objects with little supervision. This paper attempts to address the few-shot fine-grained recognition problem. We propose a feature fusion model to explore the largest discriminative features by focusing on key regions. The model utilizes focus-area location to discover the perceptually similar regions among objects. High-order integration is employed to capture the interaction information among intra-parts. We also design a Center Neighbor Loss to form robust embedding space distribution for generating discriminative features. Furthermore, we build a typical fine-grained and few-shot learning dataset miniPPlankton from the real-world application in the area of marine ecological environment. Extensive experiments are carried out to validate the performance of our model. First, the model is evaluated with two challenging experiments based on the miniDogsNet and Caltech-UCSD public datasets. The results demonstrate that our model achieves competitive performance compared with state-of-the-art models. Then, we implement our model for the real-world phytoplankton recognition task. The experimental results show the superiority of the proposed model compared with others on the miniPPlankton dataset.
Highlight Every Step: Knowledge Distillation via Collaborative Teaching
Jul 23, 2019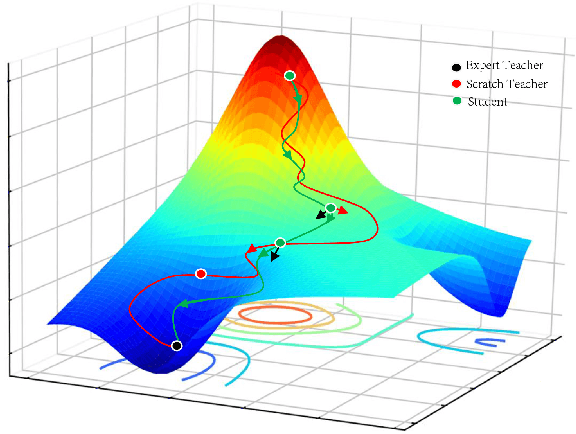
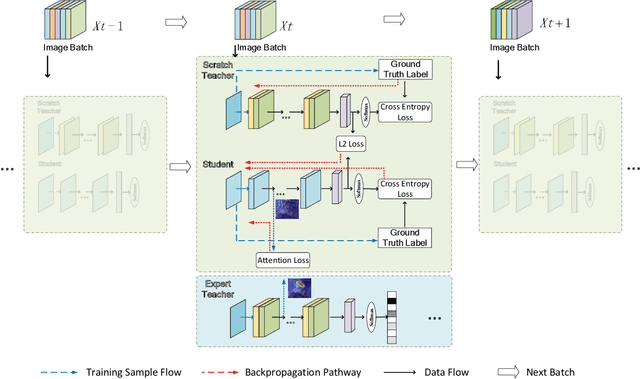

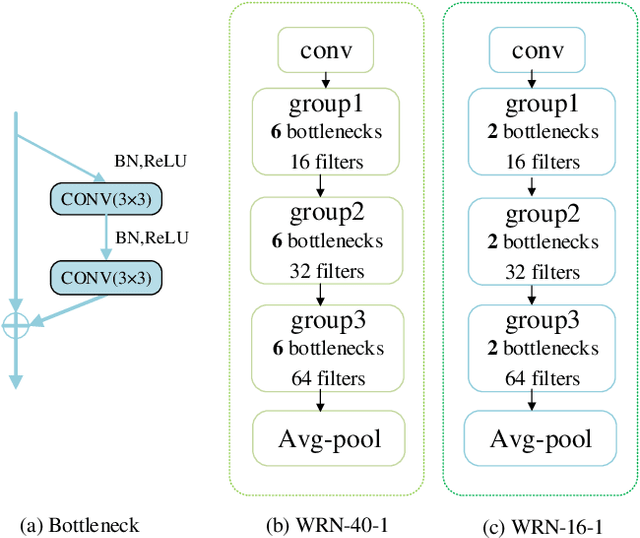
High storage and computational costs obstruct deep neural networks to be deployed on resource-constrained devices. Knowledge distillation aims to train a compact student network by transferring knowledge from a larger pre-trained teacher model. However, most existing methods on knowledge distillation ignore the valuable information among training process associated with training results. In this paper, we provide a new Collaborative Teaching Knowledge Distillation (CTKD) strategy which employs two special teachers. Specifically, one teacher trained from scratch (i.e., scratch teacher) assists the student step by step using its temporary outputs. It forces the student to approach the optimal path towards the final logits with high accuracy. The other pre-trained teacher (i.e., expert teacher) guides the student to focus on a critical region which is more useful for the task. The combination of the knowledge from two special teachers can significantly improve the performance of the student network in knowledge distillation. The results of experiments on CIFAR-10, CIFAR-100, SVHN and Tiny ImageNet datasets verify that the proposed knowledge distillation method is efficient and achieves state-of-the-art performance.