 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCognitive Pivot Points and Visual Anchoring: Unveiling and Rectifying Hallucinations in Multimodal Reasoning Models
Apr 11, 2026Multimodal Large Reasoning Models (MLRMs) have achieved remarkable strides in visual reasoning through test time compute scaling, yet long chain reasoning remains prone to hallucinations. We identify a concerning phenomenon termed the Reasoning Vision Truth Disconnect (RVTD): hallucinations are strongly correlated with cognitive bifurcation points that often exhibit high entropy states. We attribute this vulnerability to a breakdown in visual semantic anchoring, localized within the network's intermediate layers; specifically, during these high uncertainty transitions, the model fails to query visual evidence, reverting instead to language priors. Consequently, we advocate a shift from solely outcome level supervision to augmenting it with fine grained internal attention guidance. To this end, we propose V-STAR (Visual Structural Training with Attention Reinforcement), a lightweight, holistic training paradigm designed to internalize visually aware reasoning capabilities. Central to our approach is the Hierarchical Visual Attention Reward (HVAR), integrated within the GRPO framework. Upon detecting high entropy states, this mechanism dynamically incentivizes visual attention across critical intermediate layers, thereby anchoring the reasoning process back to the visual input. Furthermore, we introduce the Forced Reflection Mechanism (FRM), a trajectory editing strategy that disrupts cognitive inertia by triggering reflection around high entropy cognitive bifurcation points and encouraging verification of subsequent steps against the visual input, thereby translating external debiasing interventions into an intrinsic capability for hallucination mitigation.
Re-Prompting SAM 3 via Object Retrieval: 3rd of the 5th PVUW MOSE Track
Mar 24, 2026This technical report explores the MOSEv2 track of the PVUW 2026 Challenge, which targets complex semi-supervised video object segmentation. Built on SAM~3, we develop an automatic re-prompting framework to improve robustness under target disappearance and reappearance, severe transformation, and strong same-category distractors. Our method first applies the SAM~3 detector to later frames to identify same-category object candidates, and then performs DINOv3-based object-level matching with a transformation-aware target feature pool to retrieve reliable target anchors. These anchors are injected back into the SAM~3 tracker together with the first-frame mask, enabling multi-anchor propagation rather than relying solely on the initial prompt. This simple directly benefits several core challenges of MOSEv2. Our solution achieves a J&F of 51.17% on the test set, ranking 3rd in the MOSEv2 track.
Mostly Text, Smart Visuals: Asymmetric Text-Visual Pruning for Large Vision-Language Models
Mar 16, 2026Network pruning is an effective technique for enabling lightweight Large Vision-Language Models (LVLMs), which primarily incorporates both weights and activations into the importance metric. However, existing efforts typically process calibration data from different modalities in a unified manner, overlooking modality-specific behaviors. This raises a critical challenge: how to address the divergent behaviors of textual and visual tokens for accurate pruning of LVLMs. To this end, we systematically investigate the sensitivity of visual and textual tokens to the pruning operation by decoupling their corresponding weights, revealing that: (i) the textual pathway should be calibrated via text tokens, since it exhibits higher sensitivity than the visual pathway; (ii) the visual pathway exhibits high redundancy, permitting even 50% sparsity. Motivated by these insights, we propose a simple yet effective Asymmetric Text-Visual Weight Pruning method for LVLMs, dubbed ATV-Pruning, which establishes the importance metric for accurate weight pruning by selecting the informative tokens from both textual and visual pathways. Specifically, ATV-Pruning integrates two primary innovations: first, a calibration pool is adaptively constructed by drawing on all textual tokens and a subset of visual tokens; second, we devise a layer-adaptive selection strategy to yield important visual tokens. Finally, extensive experiments across standard multimodal benchmarks verify the superiority of our ATV-Pruning over state-of-the-art methods.
Show Me When and Where: Towards Referring Video Object Segmentation in the Wild
Mar 15, 2026Referring video object segmentation (RVOS) has recently generated great popularity in computer vision due to its widespread applications. Existing RVOS setting contains elaborately trimmed videos, with text-referred objects always appearing in all frames, which however fail to fully reflect the realistic challenges of this task. This simplified setting requires RVOS methods to only predict where objects, with no need to show when the objects appear. In this work, we introduce a new setting towards in-the-wild RVOS. To this end, we collect a new benchmark dataset using Youtube Untrimmed videos for RVOS - YoURVOS, which contains 1,120 in-the-wild videos with 7 times more duration and scenes than existing datasets. Our new benchmark challenges RVOS methods to show not only where but also when objects appear in videos. To set a baseline, we propose Object-level Multimodal TransFormers (OMFormer) to tackle the challenges, which are characterized by encoding object-level multimodal interactions for efficient and global spatial-temporal localisation. We demonstrate that previous VOS methods struggle on our YoURVOS benchmark, especially with the increase of target-absent frames, while our OMFormer consistently performs well. Our YoURVOS dataset offers an imperative benchmark, which will push forward the advancement of RVOS methods for practical applications.
Improving Anomaly Detection with Foundation-Model Synthesis and Wavelet-Domain Attention
Mar 03, 2026Industrial anomaly detection faces significant challenges due to the scarcity of anomalous samples and the complexity of real-world anomalies. In this paper, we propose a foundation model-based anomaly synthesis pipeline (FMAS) that generates highly realistic anomalous samples without fine-tuning or class-specific training. Motivated by the distinct frequency-domain characteristics of anomalies, we introduce aWavelet Domain Attention Module (WDAM), which exploits adaptive sub-band processing to enhance anomaly feature extraction. The combination of FMAS and WDAM significantly improves anomaly detection sensitivity while maintaining computational efficiency. Comprehensive experiments on MVTec AD and VisA datasets demonstrate that WDAM, as a plug-and-play module, achieves substantial performance gains against existing baselines.
ProGIC: Progressive and Lightweight Generative Image Compression with Residual Vector Quantization
Mar 03, 2026Recent advances in generative image compression (GIC) have delivered remarkable improvements in perceptual quality. However, many GICs rely on large-scale and rigid models, which severely constrain their utility for flexible transmission and practical deployment in low-bitrate scenarios. To address these issues, we propose Progressive Generative Image Compression (ProGIC), a compact codec built on residual vector quantization (RVQ). In RVQ, a sequence of vector quantizers encodes the residuals stage by stage, each with its own codebook. The resulting codewords sum to a coarse-to-fine reconstruction and a progressive bitstream, enabling previews from partial data. We pair this with a lightweight backbone based on depthwise-separable convolutions and small attention blocks, enabling practical deployment on both GPUs and CPU-only devices. Experimental results show that ProGIC attains comparable compression performance compared with previous methods. It achieves bitrate savings of up to 57.57% on DISTS and 58.83% on LPIPS compared to MS-ILLM on the Kodak dataset. Beyond perceptual quality, ProGIC enables progressive transmission for flexibility, and also delivers over 10 times faster encoding and decoding compared with MS-ILLM on GPUs for efficiency.
Controllable Exploration in Hybrid-Policy RLVR for Multi-Modal Reasoning
Feb 22, 2026Reinforcement Learning with verifiable rewards (RLVR) has emerged as a primary learning paradigm for enhancing the reasoning capabilities of multi-modal large language models (MLLMs). However, during RL training, the enormous state space of MLLM and sparse rewards often leads to entropy collapse, policy degradation, or over-exploitation of suboptimal behaviors. This necessitates an exploration strategy that maintains productive stochasticity while avoiding the drawbacks of uncontrolled random sampling, yielding inefficient exploration. In this paper, we propose CalibRL, a hybrid-policy RLVR framework that supports controllable exploration with expert guidance, enabled by two key mechanisms. First, a distribution-aware advantage weighting scales updates by group rareness to calibrate the distribution, therefore preserving exploration. Meanwhile, the asymmetric activation function (LeakyReLU) leverages the expert knowledge as a calibration baseline to moderate overconfident updates while preserving their corrective direction. CalibRL increases policy entropy in a guided manner and clarifies the target distribution by estimating the on-policy distribution through online sampling. Updates are driven by these informative behaviors, avoiding convergence to erroneous patterns. Importantly, these designs help alleviate the distributional mismatch between the model's policy and expert trajectories, thereby achieving a more stable balance between exploration and exploitation. Extensive experiments across eight benchmarks, including both in-domain and out-of-domain settings, demonstrate consistent improvements, validating the effectiveness of our controllable hybrid-policy RLVR training. Code is available at https://github.com/zhh6425/CalibRL.
SAM-Body4D: Training-Free 4D Human Body Mesh Recovery from Videos
Dec 09, 2025Human Mesh Recovery (HMR) aims to reconstruct 3D human pose and shape from 2D observations and is fundamental to human-centric understanding in real-world scenarios. While recent image-based HMR methods such as SAM 3D Body achieve strong robustness on in-the-wild images, they rely on per-frame inference when applied to videos, leading to temporal inconsistency and degraded performance under occlusions. We address these issues without extra training by leveraging the inherent human continuity in videos. We propose SAM-Body4D, a training-free framework for temporally consistent and occlusion-robust HMR from videos. We first generate identity-consistent masklets using a promptable video segmentation model, then refine them with an Occlusion-Aware module to recover missing regions. The refined masklets guide SAM 3D Body to produce consistent full-body mesh trajectories, while a padding-based parallel strategy enables efficient multi-human inference. Experimental results demonstrate that SAM-Body4D achieves improved temporal stability and robustness in challenging in-the-wild videos, without any retraining. Our code and demo are available at: https://github.com/gaomingqi/sam-body4d.
PruneHal: Reducing Hallucinations in Multi-modal Large Language Models through Adaptive KV Cache Pruning
Oct 22, 2025While multi-modal large language models (MLLMs) have made significant progress in recent years, the issue of hallucinations remains a major challenge. To mitigate this phenomenon, existing solutions either introduce additional data for further training or incorporate external or internal information during inference. However, these approaches inevitably introduce extra computational costs. In this paper, we observe that hallucinations in MLLMs are strongly associated with insufficient attention allocated to visual tokens. In particular, the presence of redundant visual tokens disperses the model's attention, preventing it from focusing on the most informative ones. As a result, critical visual cues are often under-attended, which in turn exacerbates the occurrence of hallucinations. Building on this observation, we propose \textbf{PruneHal}, a training-free, simple yet effective method that leverages adaptive KV cache pruning to enhance the model's focus on critical visual information, thereby mitigating hallucinations. To the best of our knowledge, we are the first to apply token pruning for hallucination mitigation in MLLMs. Notably, our method don't require additional training and incurs nearly no extra inference cost. Moreover, PruneHal is model-agnostic and can be seamlessly integrated with different decoding strategies, including those specifically designed for hallucination mitigation. We evaluate PruneHal on several widely used hallucination evaluation benchmarks using four mainstream MLLMs, achieving robust and outstanding results that highlight the effectiveness and superiority of our method. Our code will be publicly available.
Point Linguist Model: Segment Any Object via Bridged Large 3D-Language Model
Sep 09, 2025
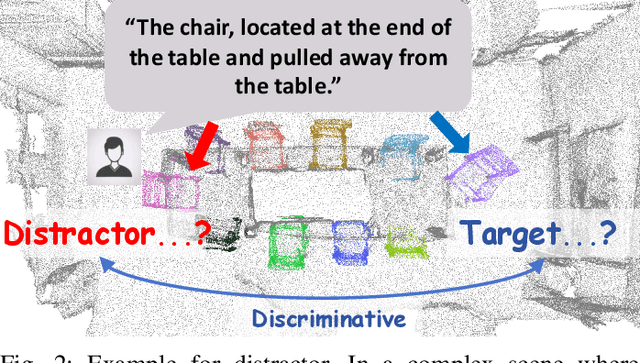


3D object segmentation with Large Language Models (LLMs) has become a prevailing paradigm due to its broad semantics, task flexibility, and strong generalization. However, this paradigm is hindered by representation misalignment: LLMs process high-level semantic tokens, whereas 3D point clouds convey only dense geometric structures. In prior methods, misalignment limits both input and output. At the input stage, dense point patches require heavy pre-alignment, weakening object-level semantics and confusing similar distractors. At the output stage, predictions depend only on dense features without explicit geometric cues, leading to a loss of fine-grained accuracy. To address these limitations, we present the Point Linguist Model (PLM), a general framework that bridges the representation gap between LLMs and dense 3D point clouds without requiring large-scale pre-alignment between 3D-text or 3D-images. Specifically, we introduce Object-centric Discriminative Representation (OcDR), which learns object-centric tokens that capture target semantics and scene relations under a hard negative-aware training objective. This mitigates the misalignment between LLM tokens and 3D points, enhances resilience to distractors, and facilitates semantic-level reasoning within LLMs. For accurate segmentation, we introduce the Geometric Reactivation Decoder (GRD), which predicts masks by combining OcDR tokens carrying LLM-inferred geometry with corresponding dense features, preserving comprehensive dense features throughout the pipeline. Extensive experiments show that PLM achieves significant improvements of +7.3 mIoU on ScanNetv2 and +6.0 mIoU on Multi3DRefer for 3D referring segmentation, with consistent gains across 7 benchmarks spanning 4 different tasks, demonstrating the effectiveness of comprehensive object-centric reasoning for robust 3D understanding.