 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Primacy of Magnitude in Low-Rank Adaptation
Jul 09, 2025Low-Rank Adaptation (LoRA) offers a parameter-efficient paradigm for tuning large models. While recent spectral initialization methods improve convergence and performance over the naive "Noise & Zeros" scheme, their extra computational and storage overhead undermines efficiency. In this paper, we establish update magnitude as the fundamental driver of LoRA performance and propose LoRAM, a magnitude-driven "Basis & Basis" initialization scheme that matches spectral methods without their inefficiencies. Our key contributions are threefold: (i) Magnitude of weight updates determines convergence. We prove low-rank structures intrinsically bound update magnitudes, unifying hyperparameter tuning in learning rate, scaling factor, and initialization as mechanisms to optimize magnitude regulation. (ii) Spectral initialization succeeds via magnitude amplification. We demystify that the presumed knowledge-driven benefit of the spectral component essentially arises from the boost in the weight update magnitude. (iii) A novel and compact initialization strategy, LoRAM, scales deterministic orthogonal bases using pretrained weight magnitudes to simulate spectral gains. Extensive experiments show that LoRAM serves as a strong baseline, retaining the full efficiency of LoRA while matching or outperforming spectral initialization across benchmarks.
DiscoVLA: Discrepancy Reduction in Vision, Language, and Alignment for Parameter-Efficient Video-Text Retrieval
Jun 10, 2025The parameter-efficient adaptation of the image-text pretraining model CLIP for video-text retrieval is a prominent area of research. While CLIP is focused on image-level vision-language matching, video-text retrieval demands comprehensive understanding at the video level. Three key discrepancies emerge in the transfer from image-level to video-level: vision, language, and alignment. However, existing methods mainly focus on vision while neglecting language and alignment. In this paper, we propose Discrepancy Reduction in Vision, Language, and Alignment (DiscoVLA), which simultaneously mitigates all three discrepancies. Specifically, we introduce Image-Video Features Fusion to integrate image-level and video-level features, effectively tackling both vision and language discrepancies. Additionally, we generate pseudo image captions to learn fine-grained image-level alignment. To mitigate alignment discrepancies, we propose Image-to-Video Alignment Distillation, which leverages image-level alignment knowledge to enhance video-level alignment. Extensive experiments demonstrate the superiority of our DiscoVLA. In particular, on MSRVTT with CLIP (ViT-B/16), DiscoVLA outperforms previous methods by 1.5% in R@1, reaching a final score of 50.5% R@1. The code is available at https://github.com/LunarShen/DsicoVLA.
RAMCT: Novel Region-adaptive Multi-channel Tracker with Iterative Tikhonov Regularization for Thermal Infrared Tracking
Apr 19, 2025Correlation filter (CF)-based trackers have gained significant attention for their computational efficiency in thermal infrared (TIR) target tracking. However, ex-isting methods struggle with challenges such as low-resolution imagery, occlu-sion, background clutter, and target deformation, which severely impact tracking performance. To overcome these limitations, we propose RAMCT, a region-adaptive sparse correlation filter tracker that integrates multi-channel feature opti-mization with an adaptive regularization strategy. Firstly, we refine the CF learn-ing process by introducing a spatially adaptive binary mask, which enforces spar-sity in the target region while dynamically suppressing background interference. Secondly, we introduce generalized singular value decomposition (GSVD) and propose a novel GSVD-based region-adaptive iterative Tikhonov regularization method. This enables flexible and robust optimization across multiple feature channels, improving resilience to occlusion and background variations. Thirdly, we propose an online optimization strategy with dynamic discrepancy-based pa-rameter adjustment. This mechanism facilitates real time adaptation to target and background variations, thereby improving tracking accuracy and robustness. Ex-tensive experiments on LSOTB-TIR, PTB-TIR, VOT-TIR2015, and VOT-TIR2017 benchmarks demonstrate that RAMCT outperforms other state-of-the-art trackers in terms of accuracy and robustness.
SU-YOLO: Spiking Neural Network for Efficient Underwater Object Detection
Mar 31, 2025Underwater object detection is critical for oceanic research and industrial safety inspections. However, the complex optical environment and the limited resources of underwater equipment pose significant challenges to achieving high accuracy and low power consumption. To address these issues, we propose Spiking Underwater YOLO (SU-YOLO), a Spiking Neural Network (SNN) model. Leveraging the lightweight and energy-efficient properties of SNNs, SU-YOLO incorporates a novel spike-based underwater image denoising method based solely on integer addition, which enhances the quality of feature maps with minimal computational overhead. In addition, we introduce Separated Batch Normalization (SeBN), a technique that normalizes feature maps independently across multiple time steps and is optimized for integration with residual structures to capture the temporal dynamics of SNNs more effectively. The redesigned spiking residual blocks integrate the Cross Stage Partial Network (CSPNet) with the YOLO architecture to mitigate spike degradation and enhance the model's feature extraction capabilities. Experimental results on URPC2019 underwater dataset demonstrate that SU-YOLO achieves mAP of 78.8% with 6.97M parameters and an energy consumption of 2.98 mJ, surpassing mainstream SNN models in both detection accuracy and computational efficiency. These results underscore the potential of SNNs for engineering applications. The code is available in https://github.com/lwxfight/snn-underwater.
FastVID: Dynamic Density Pruning for Fast Video Large Language Models
Mar 14, 2025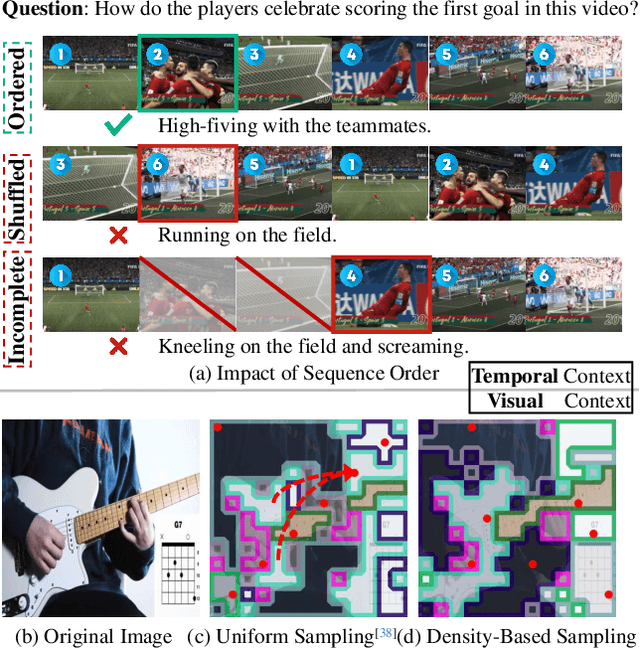
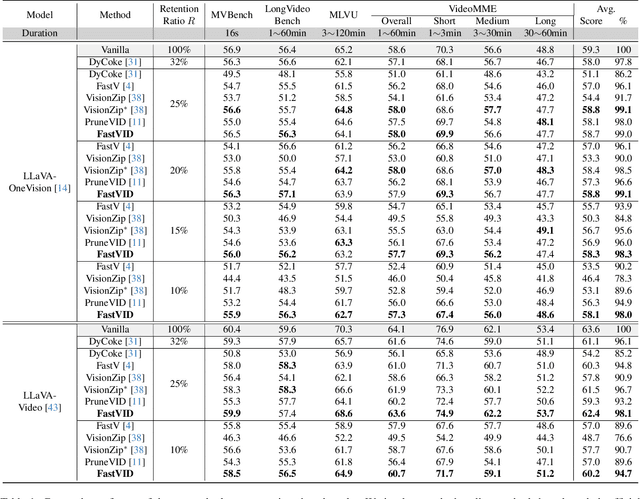
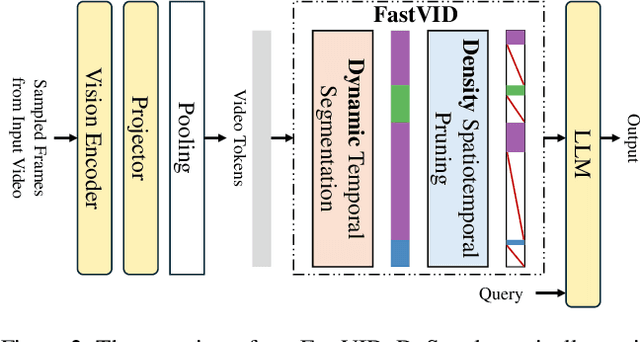
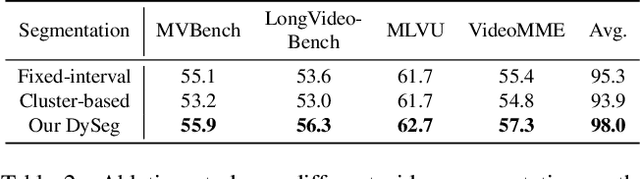
Video Large Language Models have shown impressive capabilities in video comprehension, yet their practical deployment is hindered by substantial inference costs caused by redundant video tokens. Existing pruning techniques fail to fully exploit the spatiotemporal redundancy inherent in video data. To bridge this gap, we perform a systematic analysis of video redundancy from two perspectives: temporal context and visual context. Leveraging this insight, we propose Dynamic Density Pruning for Fast Video LLMs termed FastVID. Specifically, FastVID dynamically partitions videos into temporally ordered segments to preserve temporal structure and applies a density-based token pruning strategy to maintain essential visual information. Our method significantly reduces computational overhead while maintaining temporal and visual integrity. Extensive evaluations show that FastVID achieves state-of-the-art performance across various short- and long-video benchmarks on leading Video LLMs, including LLaVA-OneVision and LLaVA-Video. Notably, FastVID effectively prunes 90% of video tokens while retaining 98.0% of LLaVA-OneVision's original performance. The code is available at https://github.com/LunarShen/FastVID.
LLaVA-MLB: Mitigating and Leveraging Attention Bias for Training-Free Video LLMs
Mar 14, 2025

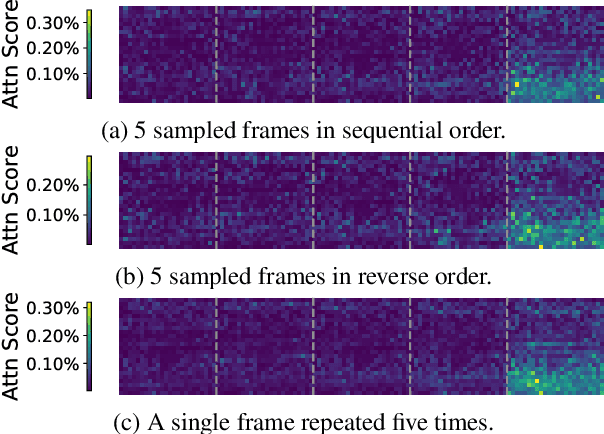
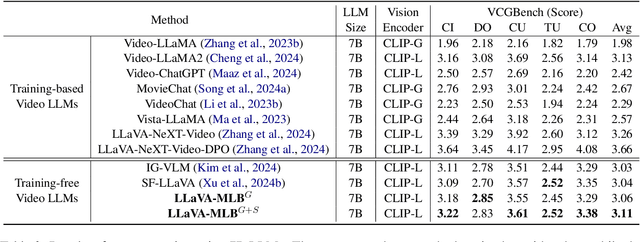
Training-free video large language models (LLMs) leverage pretrained Image LLMs to process video content without the need for further training. A key challenge in such approaches is the difficulty of retaining essential visual and temporal information, constrained by the token limits in Image LLMs. To address this, we propose a two-stage method for selecting query-relevant tokens based on the LLM attention scores: compressing the video sequence and then expanding the sequence. However, during the compression stage, Image LLMs often exhibit a positional attention bias in video sequences, where attention is overly concentrated on later frames, causing early-frame information to be underutilized. To alleviate this attention bias during sequence compression, we propose Gridded Attention Pooling for preserving spatiotemporal structure. Additionally, we introduce Visual Summarization Tail to effectively utilize this bias, facilitating overall video understanding during sequence expansion. In this way, our method effectively Mitigates and Leverages attention Bias (LLaVA-MLB), enabling the frozen Image LLM for detailed video understanding. Experiments on several benchmarks demonstrate that our approach outperforms state-of-the-art methods, achieving superior performance in both efficiency and accuracy. Our code will be released.
Scale Matters: Temporal Scale Aggregation Network for Precise Action Localization in Untrimmed Videos
Aug 02, 2019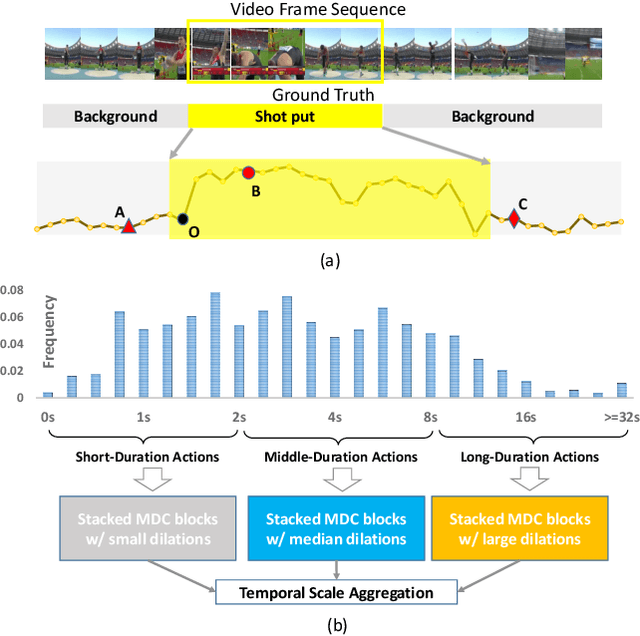
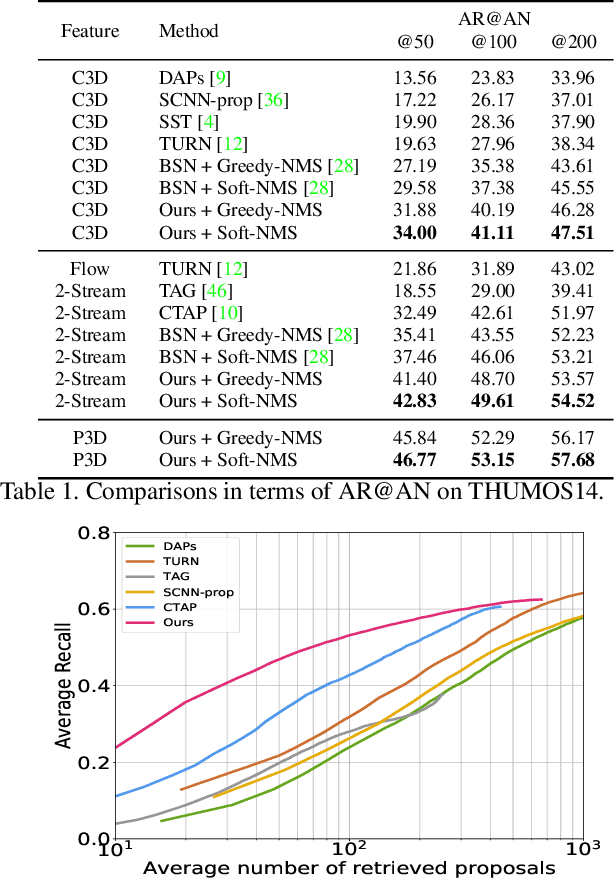

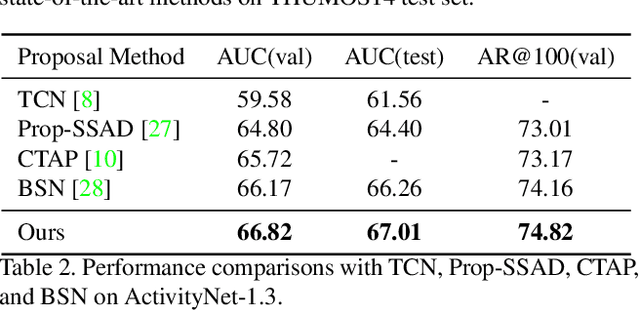
Temporal action localization is a recently-emerging task, aiming to localize video segments from untrimmed videos that contain specific actions. Despite the remarkable recent progress, most two-stage action localization methods still suffer from imprecise temporal boundaries of action proposals. This work proposes a novel integrated temporal scale aggregation network (TSA-Net). Our main insight is that ensembling convolution filters with different dilation rates can effectively enlarge the receptive field with low computational cost, which inspires us to devise multi-dilation temporal convolution (MDC) block. Furthermore, to tackle video action instances with different durations, TSA-Net consists of multiple branches of sub-networks. Each of them adopts stacked MDC blocks with different dilation parameters, accomplishing a temporal receptive field specially optimized for specific-duration actions. We follow the formulation of boundary point detection, novelly detecting three kinds of critical points (ie, starting / mid-point / ending) and pairing them for proposal generation. Comprehensive evaluations are conducted on two challenging video benchmarks, THUMOS14 and ActivityNet-1.3. Our proposed TSA-Net demonstrates clear and consistent better performances and re-calibrates new state-of-the-art on both benchmarks. For example, our new record on THUMOS14 is 46.9% while the previous best is 42.8% under mAP@0.5.