 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLaVA-MLB: Mitigating and Leveraging Attention Bias for Training-Free Video LLMs
Paper and Code
Mar 14, 2025

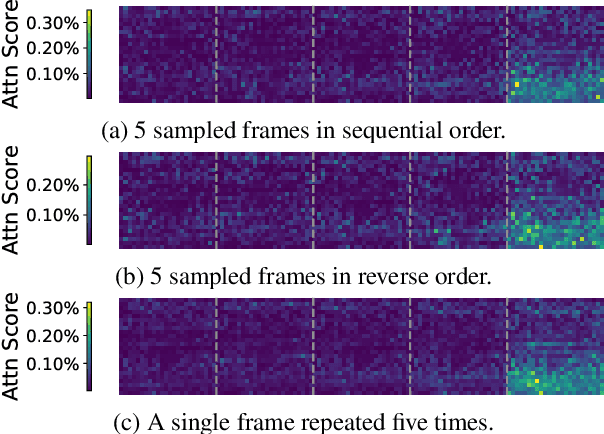
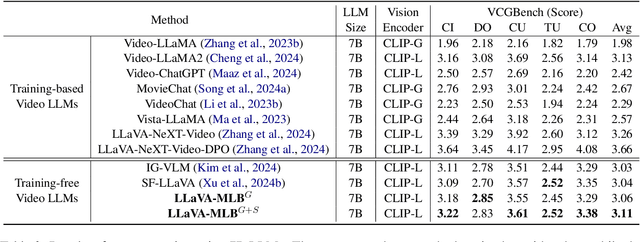
Training-free video large language models (LLMs) leverage pretrained Image LLMs to process video content without the need for further training. A key challenge in such approaches is the difficulty of retaining essential visual and temporal information, constrained by the token limits in Image LLMs. To address this, we propose a two-stage method for selecting query-relevant tokens based on the LLM attention scores: compressing the video sequence and then expanding the sequence. However, during the compression stage, Image LLMs often exhibit a positional attention bias in video sequences, where attention is overly concentrated on later frames, causing early-frame information to be underutilized. To alleviate this attention bias during sequence compression, we propose Gridded Attention Pooling for preserving spatiotemporal structure. Additionally, we introduce Visual Summarization Tail to effectively utilize this bias, facilitating overall video understanding during sequence expansion. In this way, our method effectively Mitigates and Leverages attention Bias (LLaVA-MLB), enabling the frozen Image LLM for detailed video understanding. Experiments on several benchmarks demonstrate that our approach outperforms state-of-the-art methods, achieving superior performance in both efficiency and accuracy. Our code will be released.