 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCREM: Compression-Driven Representation Enhancement for Multimodal Retrieval and Comprehension
Feb 22, 2026Multimodal Large Language Models (MLLMs) have shown remarkable success in comprehension tasks such as visual description and visual question answering. However, their direct application to embedding-based tasks like retrieval remains challenging due to the discrepancy between output formats and optimization objectives. Previous approaches often employ contrastive fine-tuning to adapt MLLMs for retrieval, but at the cost of losing their generative capabilities. We argue that both generative and embedding tasks fundamentally rely on shared cognitive mechanisms, specifically cross-modal representation alignment and contextual comprehension. To this end, we propose CREM (Compression-driven Representation Enhanced Model), with a unified framework that enhances multimodal representations for retrieval while preserving generative ability. Specifically, we introduce a compression-based prompt design with learnable chorus tokens to aggregate multimodal semantics and a compression-driven training strategy that integrates contrastive and generative objectives through compression-aware attention. Extensive experiments demonstrate that CREM achieves state-of-the-art retrieval performance on MMEB while maintaining strong generative performance on multiple comprehension benchmarks. Our findings highlight that generative supervision can further improve the representational quality of MLLMs under the proposed compression-driven paradigm.
PruneHal: Reducing Hallucinations in Multi-modal Large Language Models through Adaptive KV Cache Pruning
Oct 22, 2025While multi-modal large language models (MLLMs) have made significant progress in recent years, the issue of hallucinations remains a major challenge. To mitigate this phenomenon, existing solutions either introduce additional data for further training or incorporate external or internal information during inference. However, these approaches inevitably introduce extra computational costs. In this paper, we observe that hallucinations in MLLMs are strongly associated with insufficient attention allocated to visual tokens. In particular, the presence of redundant visual tokens disperses the model's attention, preventing it from focusing on the most informative ones. As a result, critical visual cues are often under-attended, which in turn exacerbates the occurrence of hallucinations. Building on this observation, we propose \textbf{PruneHal}, a training-free, simple yet effective method that leverages adaptive KV cache pruning to enhance the model's focus on critical visual information, thereby mitigating hallucinations. To the best of our knowledge, we are the first to apply token pruning for hallucination mitigation in MLLMs. Notably, our method don't require additional training and incurs nearly no extra inference cost. Moreover, PruneHal is model-agnostic and can be seamlessly integrated with different decoding strategies, including those specifically designed for hallucination mitigation. We evaluate PruneHal on several widely used hallucination evaluation benchmarks using four mainstream MLLMs, achieving robust and outstanding results that highlight the effectiveness and superiority of our method. Our code will be publicly available.
S$^4$C: Speculative Sampling with Syntactic and Semantic Coherence for Efficient Inference of Large Language Models
Jun 17, 2025Large language models (LLMs) exhibit remarkable reasoning capabilities across diverse downstream tasks. However, their autoregressive nature leads to substantial inference latency, posing challenges for real-time applications. Speculative sampling mitigates this issue by introducing a drafting phase followed by a parallel validation phase, enabling faster token generation and verification. Existing approaches, however, overlook the inherent coherence in text generation, limiting their efficiency. To address this gap, we propose a Speculative Sampling with Syntactic and Semantic Coherence (S$^4$C) framework, which extends speculative sampling by leveraging multi-head drafting for rapid token generation and a continuous verification tree for efficient candidate validation and feature reuse. Experimental results demonstrate that S$^4$C surpasses baseline methods across mainstream tasks, offering enhanced efficiency, parallelism, and the ability to generate more valid tokens with fewer computational resources. On Spec-bench benchmarks, S$^4$C achieves an acceleration ratio of 2.26x-2.60x, outperforming state-of-the-art methods.
DiscoVLA: Discrepancy Reduction in Vision, Language, and Alignment for Parameter-Efficient Video-Text Retrieval
Jun 10, 2025The parameter-efficient adaptation of the image-text pretraining model CLIP for video-text retrieval is a prominent area of research. While CLIP is focused on image-level vision-language matching, video-text retrieval demands comprehensive understanding at the video level. Three key discrepancies emerge in the transfer from image-level to video-level: vision, language, and alignment. However, existing methods mainly focus on vision while neglecting language and alignment. In this paper, we propose Discrepancy Reduction in Vision, Language, and Alignment (DiscoVLA), which simultaneously mitigates all three discrepancies. Specifically, we introduce Image-Video Features Fusion to integrate image-level and video-level features, effectively tackling both vision and language discrepancies. Additionally, we generate pseudo image captions to learn fine-grained image-level alignment. To mitigate alignment discrepancies, we propose Image-to-Video Alignment Distillation, which leverages image-level alignment knowledge to enhance video-level alignment. Extensive experiments demonstrate the superiority of our DiscoVLA. In particular, on MSRVTT with CLIP (ViT-B/16), DiscoVLA outperforms previous methods by 1.5% in R@1, reaching a final score of 50.5% R@1. The code is available at https://github.com/LunarShen/DsicoVLA.
AdaTP: Attention-Debiased Token Pruning for Video Large Language Models
May 26, 2025Video Large Language Models (Video LLMs) have achieved remarkable results in video understanding tasks. However, they often suffer from heavy computational overhead due to the large number of visual tokens generated from multiple video frames. Existing visual token compression methods often rely on attention scores from language models as guidance. However, these scores exhibit inherent biases: global bias reflects a tendency to focus on the two ends of the visual token sequence, while local bias leads to an over-concentration on the same spatial positions across different frames. To address the issue of attention bias, we propose $\textbf{A}$ttention-$\textbf{D}$ebi$\textbf{a}$sed $\textbf{T}$oken $\textbf{P}$runing for Video Large Language Models ($\textbf{AdaTP}$), a novel token pruning pipeline for Video LLMs. AdaTP integrates two dedicated debiasing modules into the pipeline, targeting global attention bias and local attention bias, respectively. Without the need for additional training, our method significantly reduces the computational overhead of Video LLMs while retaining the performance of vanilla models. Extensive evaluation shows that AdaTP achieves state-of-the-art performance in various commonly used video understanding benchmarks. In particular, on LLaVA-OneVision-7B, AdaTP maintains performance without degradation while using only up to $27.3\%$ FLOPs compared to the vanilla model. Our code will be released soon.
Fast Quiet-STaR: Thinking Without Thought Tokens
May 23, 2025Large Language Models (LLMs) have achieved impressive performance across a range of natural language processing tasks. However, recent advances demonstrate that further gains particularly in complex reasoning tasks require more than merely scaling up model sizes or training data. One promising direction is to enable models to think during the reasoning process. Recently, Quiet STaR significantly improves reasoning by generating token-level thought traces, but incurs substantial inference overhead. In this work, we propose Fast Quiet STaR, a more efficient reasoning framework that preserves the benefits of token-level reasoning while reducing computational cost. Our method introduces a curriculum learning based training strategy that gradually reduces the number of thought tokens, enabling the model to internalize more abstract and concise reasoning processes. We further extend this approach to the standard Next Token Prediction (NTP) setting through reinforcement learning-based fine-tuning, resulting in Fast Quiet-STaR NTP, which eliminates the need for explicit thought token generation during inference. Experiments on four benchmark datasets with Mistral 7B and Qwen2.5 7B demonstrate that Fast Quiet-STaR consistently outperforms Quiet-STaR in terms of average accuracy under the same inference time budget. Notably, Fast Quiet-STaR NTP achieves an average accuracy improvement of 9\% on Mistral 7B and 5.7\% on Qwen2.5 7B, while maintaining the same inference latency. Our code will be available at https://github.com/huangwei200012/Fast-Quiet-STaR.
Modality Reliability Guided Multimodal Recommendation
Apr 23, 2025
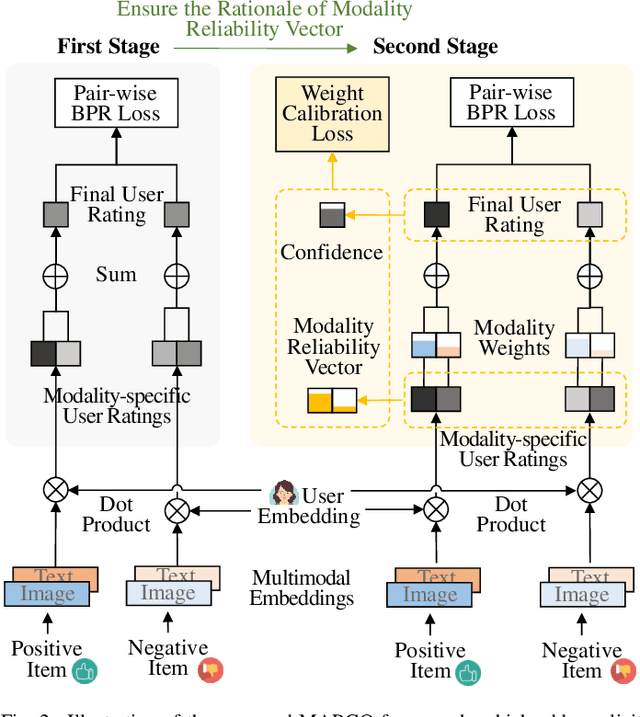
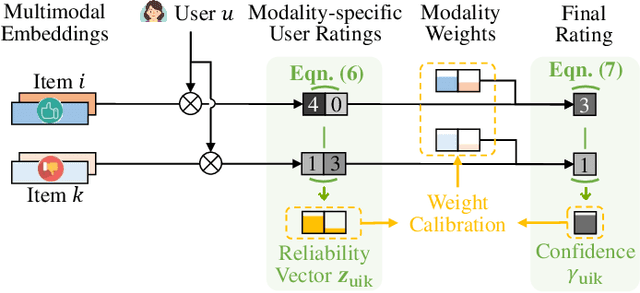
Multimodal recommendation faces an issue of the performance degradation that the uni-modal recommendation sometimes achieves the better performance. A possible reason is that the unreliable item modality data hurts the fusion result. Several existing studies have introduced weights for different modalities to reduce the contribution of the unreliable modality data in predicting the final user rating. However, they fail to provide appropriate supervisions for learning the modality weights, making the learned weights imprecise. Therefore, we propose a modality reliability guided multimodal recommendation framework that uniquely learns the modality weights supervised by the modality reliability. Considering that there is no explicit label provided for modality reliability, we resort to automatically identify it through the BPR recommendation objective. In particular, we define a modality reliability vector as the supervision label by the difference between modality-specific user ratings to positive and negative items, where a larger difference indicates a higher reliability of the modality as the BPR objective is better satisfied. Furthermore, to enhance the effectiveness of the supervision, we calculate the confidence level for the modality reliability vector, which dynamically adjusts the supervision strength and eliminates the harmful supervision. Extensive experiments on three real-world datasets show the effectiveness of the proposed method.
LSNet: See Large, Focus Small
Mar 29, 2025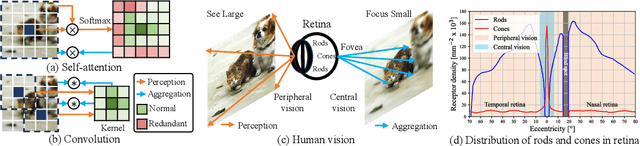
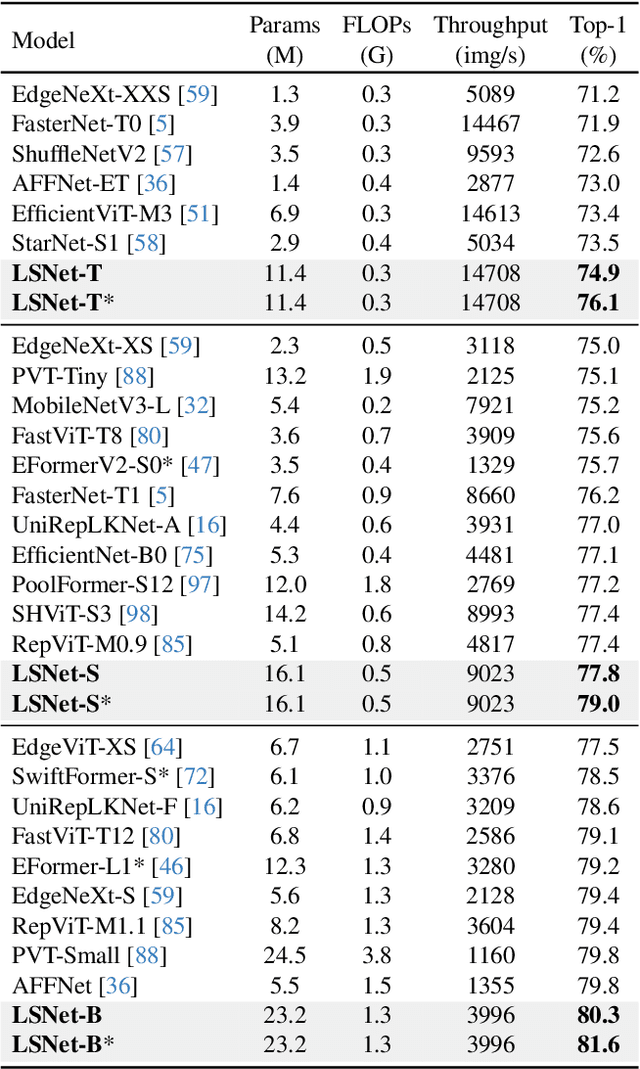
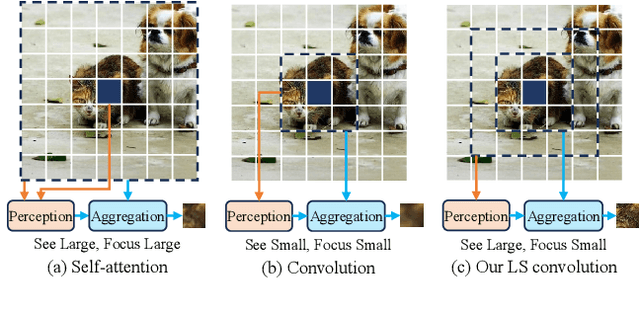
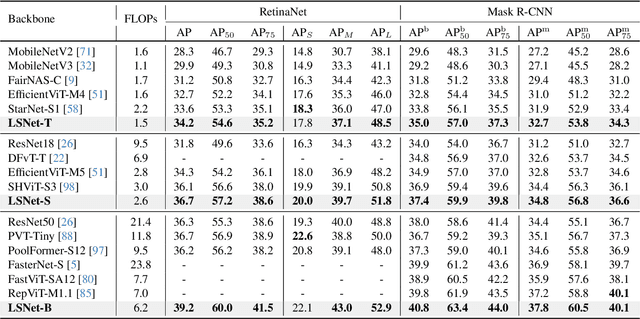
Vision network designs, including Convolutional Neural Networks and Vision Transformers, have significantly advanced the field of computer vision. Yet, their complex computations pose challenges for practical deployments, particularly in real-time applications. To tackle this issue, researchers have explored various lightweight and efficient network designs. However, existing lightweight models predominantly leverage self-attention mechanisms and convolutions for token mixing. This dependence brings limitations in effectiveness and efficiency in the perception and aggregation processes of lightweight networks, hindering the balance between performance and efficiency under limited computational budgets. In this paper, we draw inspiration from the dynamic heteroscale vision ability inherent in the efficient human vision system and propose a ``See Large, Focus Small'' strategy for lightweight vision network design. We introduce LS (\textbf{L}arge-\textbf{S}mall) convolution, which combines large-kernel perception and small-kernel aggregation. It can efficiently capture a wide range of perceptual information and achieve precise feature aggregation for dynamic and complex visual representations, thus enabling proficient processing of visual information. Based on LS convolution, we present LSNet, a new family of lightweight models. Extensive experiments demonstrate that LSNet achieves superior performance and efficiency over existing lightweight networks in various vision tasks. Codes and models are available at https://github.com/jameslahm/lsnet.
Cream of the Crop: Harvesting Rich, Scalable and Transferable Multi-Modal Data for Instruction Fine-Tuning
Mar 17, 2025The hypothesis that pretrained large language models (LLMs) necessitate only minimal supervision during the fine-tuning (SFT) stage (Zhou et al., 2024) has been substantiated by recent advancements in data curation and selection research. However, their stability and generalizability are compromised due to the vulnerability to experimental setups and validation protocols, falling short of surpassing random sampling (Diddee & Ippolito, 2024; Xia et al., 2024b). Built upon LLMs, multi-modal LLMs (MLLMs), combined with the sheer token volume and heightened heterogeneity of data sources, amplify both the significance and complexity of data selection. To harvest multi-modal instructional data in a robust and efficient manner, we re-define the granularity of the quality metric by decomposing it into 14 vision-language-related capabilities, and introduce multi-modal rich scorers to evaluate the capabilities of each data candidate. To promote diversity, in light of the inherent objective of the alignment stage, we take interaction style as diversity indicator and use a multi-modal rich styler to identify data instruction patterns. In doing so, our multi-modal rich scorers and styler (mmSSR) guarantee that high-scoring information is conveyed to users in diversified forms. Free from embedding-based clustering or greedy sampling, mmSSR efficiently scales to millions of data with varying budget constraints, supports customization for general or specific capability acquisition, and facilitates training-free generalization to new domains for curation. Across 10+ experimental settings, validated by 14 multi-modal benchmarks, we demonstrate consistent improvements over random sampling, baseline strategies and state-of-the-art selection methods, achieving 99.1% of full performance with only 30% of the 2.6M data.
FastVID: Dynamic Density Pruning for Fast Video Large Language Models
Mar 14, 2025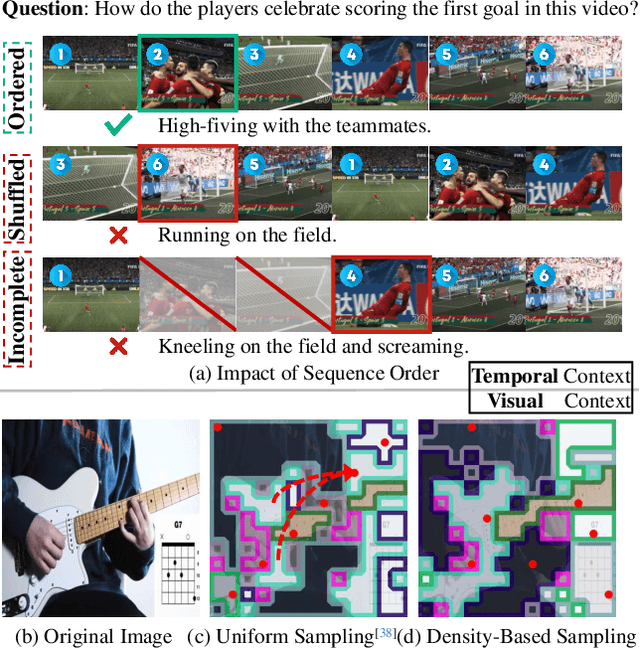
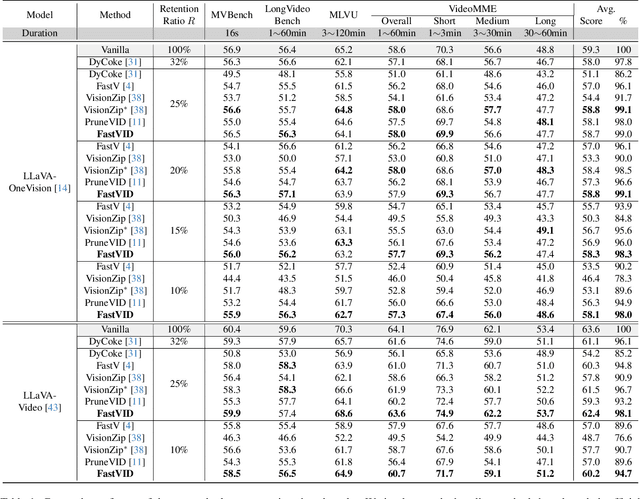
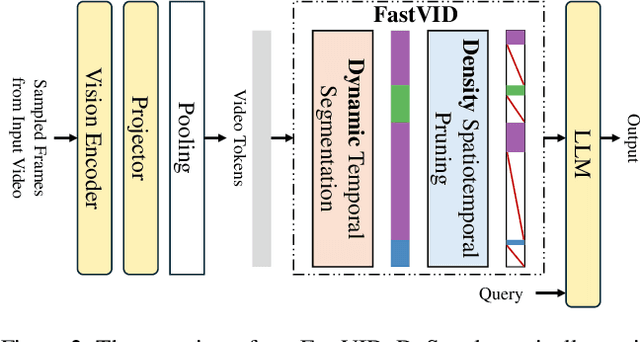
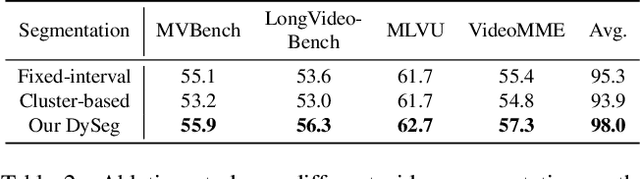
Video Large Language Models have shown impressive capabilities in video comprehension, yet their practical deployment is hindered by substantial inference costs caused by redundant video tokens. Existing pruning techniques fail to fully exploit the spatiotemporal redundancy inherent in video data. To bridge this gap, we perform a systematic analysis of video redundancy from two perspectives: temporal context and visual context. Leveraging this insight, we propose Dynamic Density Pruning for Fast Video LLMs termed FastVID. Specifically, FastVID dynamically partitions videos into temporally ordered segments to preserve temporal structure and applies a density-based token pruning strategy to maintain essential visual information. Our method significantly reduces computational overhead while maintaining temporal and visual integrity. Extensive evaluations show that FastVID achieves state-of-the-art performance across various short- and long-video benchmarks on leading Video LLMs, including LLaVA-OneVision and LLaVA-Video. Notably, FastVID effectively prunes 90% of video tokens while retaining 98.0% of LLaVA-OneVision's original performance. The code is available at https://github.com/LunarShen/FastVID.