 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferAD-R1: A Difference-Guided IndustrialAnomaly Localization with Multimodal LargeLanguage Models
Jun 15, 2026Industrial anomaly localization aims to accurately identify and localize abnormal regions in industrial products, addressing the critical challenge of detecting unseen defect categories in real-world scenarios. Traditional closed-set methods often suffer from poor cross-scenario generalization, while existingMultimodal Large Language Model (MLLM)-based approachesface two core limitations: they either adopt QA-style paradigmsmisaligned with the practical demands of localization, or relyon standard optimization techniques such as Group RelativePolicy Optimization (GRPO), which fails to deliver effectivelearning signals for subtle defects. To tackle these issues, thispaper proposes DifferAD-R1, an MLLM-augmented reinforcement learning framework tailored for industrial anomaly localization. We design a Difference-Guided dual-image paradigm,which reformulates the localization task as a one-shot difference grounding problem to effectively explore cross-scenarioanomalies. A Dual-Consistency Localization Reward is developedfor hard-to-detect anomalies, enhancing optimization stabilityand robustness. Additionally, we integrate a difficulty-awarestrategy with adaptive reweighting and group-wise resamplingto prioritize learning on challenging instances. To facilitateevaluations in real-world industrial settings, we construct theAD-DualDiff dataset, comprising 13K paired images across 20categories. Experimental results demonstrate that DifferADR1 significantly outperforms existing baselines and achievescompetitive performance compared to large-scale models likeQwen3-VL (235B parameters). Our code is publicly availableat: https://github.com/Rong2026/work-1.
Clinically Interpretable Sepsis Early Warning via LLM-Guided Simulation of Temporal Physiological Dynamics
Apr 22, 2026Timely and interpretable early warning of sepsis remains a major clinical challenge due to the complex temporal dynamics of physiological deterioration. Traditional data-driven models often provide accurate yet opaque predictions, limiting physicians' confidence and clinical applicability. To address this limitation, we propose a Large Language Model (LLM)-guided temporal simulation framework that explicitly models physiological trajectories prior to disease onset for clinically interpretable prediction. The framework consists of a spatiotemporal feature extraction module that captures dynamic dependencies among multivariate vital signs, a Medical Prompt-as-Prefix module that embeds clinical reasoning cues into LLMs, and an agent-based post-processing component that constrains predictions within physiologically plausible ranges. By first simulating the evolution of key physiological indicators and then classifying sepsis onset, our model offers transparent prediction mechanisms that align with clinical judgment. Evaluated on the MIMIC-IV and eICU databases, the proposed method achieves superior AUC scores (0.861-0.903) across 24-4-hour pre-onset prediction tasks, outperforming conventional deep learning and rule-based approaches. More importantly, it provides interpretable trajectories and risk trends that can assist clinicians in early intervention and personalized decision-making in intensive care environments.
Visual Enhanced Depth Scaling for Multimodal Latent Reasoning
Apr 12, 2026Multimodal latent reasoning has emerged as a promising paradigm that replaces explicit Chain-of-Thought (CoT) decoding with implicit feature propagation, simultaneously enhancing representation informativeness and reducing inference latency. By analyzing token-level gradient dynamics during latent training, we reveal two critical observations: (1) visual tokens exhibit significantly higher and more volatile gradient norms than their textual counterparts due to inherent language bias, resulting in systematic visual under-optimization; and (2) semantically simple tokens converge rapidly, whereas complex tokens exhibit persistent gradient instability constrained by fixed architectural depths. To address these limitations, we propose a visual replay module and routing depth scaling to collaboratively enhance visual perception and refine complicated latents for deeper contextual reasoning. The former module leverages causal self-attention to estimate token saliency, reinforcing fine-grained grounding through spatially-coherent constraints. Complementarily, the latter mechanism adaptively allocates additional reasoning steps to complex tokens, enabling deeper contextual refinement. Guided by a curriculum strategy that progressively internalizes explicit CoT into compact latent representations, our framework achieves state-of-the-art performance across diverse benchmarks while delivering substantial inference speedups over explicit CoT baselines.
AG-VAS: Anchor-Guided Zero-Shot Visual Anomaly Segmentation with Large Multimodal Models
Mar 01, 2026Large multimodal models (LMMs) exhibit strong task generalization capabilities, offering new opportunities for zero-shot visual anomaly segmentation (ZSAS). However, existing LMM-based segmentation approaches still face fundamental limitations: anomaly concepts are inherently abstract and context-dependent, lacking stable visual prototypes, and the weak alignment between high-level semantic embeddings and pixel-level spatial features hinders precise anomaly localization. To address these challenges, we present AG-VAS (Anchor-Guided Visual Anomaly Segmentation), a new framework that expands the LMM vocabulary with three learnable semantic anchor tokens-[SEG], [NOR], and [ANO], establishing a unified anchor-guided segmentation paradigm. Specifically, [SEG] serves as an absolute semantic anchor that translates abstract anomaly semantics into explicit, spatially grounded visual entities (e.g., holes or scratches), while [NOR] and [ANO] act as relative anchors that model the contextual contrast between normal and abnormal patterns across categories. To further enhance cross-modal alignment, we introduce a Semantic-Pixel Alignment Module (SPAM) that aligns language-level semantic embeddings with high-resolution visual features, along with an Anchor-Guided Mask Decoder (AGMD) that performs anchor-conditioned mask prediction for precise anomaly localization. In addition, we curate Anomaly-Instruct20K, a large-scale instruction dataset that organizes anomaly knowledge into structured descriptions of appearance, shape, and spatial attributes, facilitating effective learning and integration of the proposed semantic anchors. Extensive experiments on six industrial and medical benchmarks demonstrate that AG-VAS achieves consistent state-of-the-art performance in the zero-shot setting.
Center-aware Residual Anomaly Synthesis for Multi-class Industrial Anomaly Detection
May 23, 2025Anomaly detection plays a vital role in the inspection of industrial images. Most existing methods require separate models for each category, resulting in multiplied deployment costs. This highlights the challenge of developing a unified model for multi-class anomaly detection. However, the significant increase in inter-class interference leads to severe missed detections. Furthermore, the intra-class overlap between normal and abnormal samples, particularly in synthesis-based methods, cannot be ignored and may lead to over-detection. To tackle these issues, we propose a novel Center-aware Residual Anomaly Synthesis (CRAS) method for multi-class anomaly detection. CRAS leverages center-aware residual learning to couple samples from different categories into a unified center, mitigating the effects of inter-class interference. To further reduce intra-class overlap, CRAS introduces distance-guided anomaly synthesis that adaptively adjusts noise variance based on normal data distribution. Experimental results on diverse datasets and real-world industrial applications demonstrate the superior detection accuracy and competitive inference speed of CRAS. The source code and the newly constructed dataset are publicly available at https://github.com/cqylunlun/CRAS.
Bayesian Prompt Flow Learning for Zero-Shot Anomaly Detection
Mar 13, 2025Recently, vision-language models (e.g. CLIP) have demonstrated remarkable performance in zero-shot anomaly detection (ZSAD). By leveraging auxiliary data during training, these models can directly perform cross-category anomaly detection on target datasets, such as detecting defects on industrial product surfaces or identifying tumors in organ tissues. Existing approaches typically construct text prompts through either manual design or the optimization of learnable prompt vectors. However, these methods face several challenges: 1) handcrafted prompts require extensive expert knowledge and trial-and-error; 2) single-form learnable prompts struggle to capture complex anomaly semantics; and 3) an unconstrained prompt space limit generalization to unseen categories. To address these issues, we propose Bayesian Prompt Flow Learning (Bayes-PFL), which models the prompt space as a learnable probability distribution from a Bayesian perspective. Specifically, a prompt flow module is designed to learn both image-specific and image-agnostic distributions, which are jointly utilized to regularize the text prompt space and enhance the model's generalization on unseen categories. These learned distributions are then sampled to generate diverse text prompts, effectively covering the prompt space. Additionally, a residual cross-attention (RCA) module is introduced to better align dynamic text embeddings with fine-grained image features. Extensive experiments on 15 industrial and medical datasets demonstrate our method's superior performance.
ALMRR: Anomaly Localization Mamba on Industrial Textured Surface with Feature Reconstruction and Refinement
Jul 25, 2024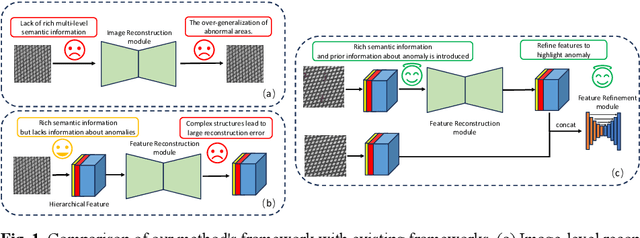

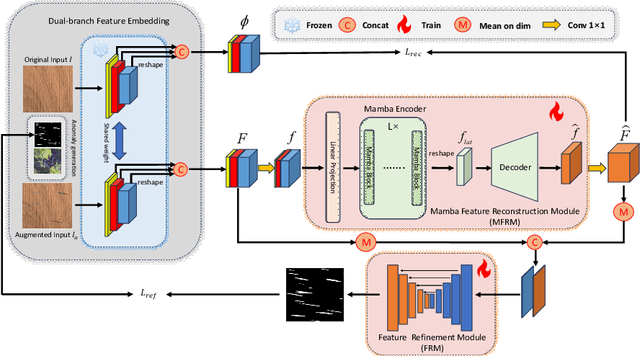

Unsupervised anomaly localization on industrial textured images has achieved remarkable results through reconstruction-based methods, yet existing approaches based on image reconstruction and feature reconstruc-tion each have their own shortcomings. Firstly, image-based methods tend to reconstruct both normal and anomalous regions well, which lead to over-generalization. Feature-based methods contain a large amount of distin-guishable semantic information, however, its feature structure is redundant and lacks anomalous information, which leads to significant reconstruction errors. In this paper, we propose an Anomaly Localization method based on Mamba with Feature Reconstruction and Refinement(ALMRR) which re-constructs semantic features based on Mamba and then refines them through a feature refinement module. To equip the model with prior knowledge of anomalies, we enhance it by adding artificially simulated anomalies to the original images. Unlike image reconstruction or repair, the features of synthesized defects are repaired along with those of normal areas. Finally, the aligned features containing rich semantic information are fed in-to the refinement module to obtain the anomaly map. Extensive experiments have been conducted on the MVTec-AD-Textured dataset and other real-world industrial dataset, which has demonstrated superior performance com-pared to state-of-the-art (SOTA) methods.
VCP-CLIP: A visual context prompting model for zero-shot anomaly segmentation
Jul 17, 2024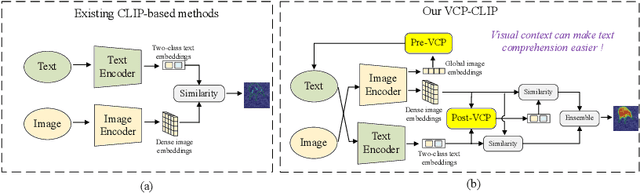
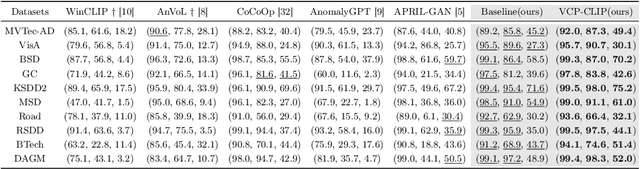
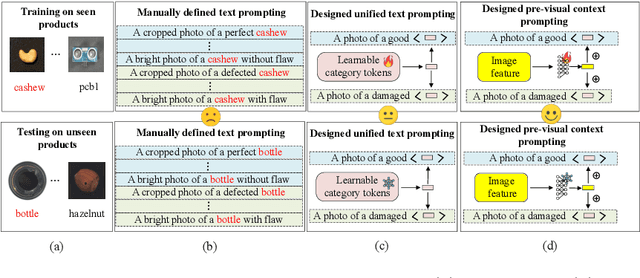

Recently, large-scale vision-language models such as CLIP have demonstrated immense potential in zero-shot anomaly segmentation (ZSAS) task, utilizing a unified model to directly detect anomalies on any unseen product with painstakingly crafted text prompts. However, existing methods often assume that the product category to be inspected is known, thus setting product-specific text prompts, which is difficult to achieve in the data privacy scenarios. Moreover, even the same type of product exhibits significant differences due to specific components and variations in the production process, posing significant challenges to the design of text prompts. In this end, we propose a visual context prompting model (VCP-CLIP) for ZSAS task based on CLIP. The insight behind VCP-CLIP is to employ visual context prompting to activate CLIP's anomalous semantic perception ability. In specific, we first design a Pre-VCP module to embed global visual information into the text prompt, thus eliminating the necessity for product-specific prompts. Then, we propose a novel Post-VCP module, that adjusts the text embeddings utilizing the fine-grained features of the images. In extensive experiments conducted on 10 real-world industrial anomaly segmentation datasets, VCP-CLIP achieved state-of-the-art performance in ZSAS task. The code is available at https://github.com/xiaozhen228/VCP-CLIP.
Investigating Shift Equivalence of Convolutional Neural Networks in Industrial Defect Segmentation
Sep 29, 2023



In industrial defect segmentation tasks, while pixel accuracy and Intersection over Union (IoU) are commonly employed metrics to assess segmentation performance, the output consistency (also referred to equivalence) of the model is often overlooked. Even a small shift in the input image can yield significant fluctuations in the segmentation results. Existing methodologies primarily focus on data augmentation or anti-aliasing to enhance the network's robustness against translational transformations, but their shift equivalence performs poorly on the test set or is susceptible to nonlinear activation functions. Additionally, the variations in boundaries resulting from the translation of input images are consistently disregarded, thus imposing further limitations on the shift equivalence. In response to this particular challenge, a novel pair of down/upsampling layers called component attention polyphase sampling (CAPS) is proposed as a replacement for the conventional sampling layers in CNNs. To mitigate the effect of image boundary variations on the equivalence, an adaptive windowing module is designed in CAPS to adaptively filter out the border pixels of the image. Furthermore, a component attention module is proposed to fuse all downsampled features to improve the segmentation performance. The experimental results on the micro surface defect (MSD) dataset and four real-world industrial defect datasets demonstrate that the proposed method exhibits higher equivalence and segmentation performance compared to other state-of-the-art methods.Our code will be available at https://github.com/xiaozhen228/CAPS.
The Second-place Solution for CVPR VISION 23 Challenge Track 1 -- Data Effificient Defect Detection
Jun 25, 2023



The Vision Challenge Track 1 for Data-Effificient Defect Detection requires competitors to instance segment 14 industrial inspection datasets in a data-defificient setting. This report introduces the technical details of the team Aoi-overfifitting-Team for this challenge. Our method focuses on the key problem of segmentation quality of defect masks in scenarios with limited training samples. Based on the Hybrid Task Cascade (HTC) instance segmentation algorithm, we connect the transformer backbone (Swin-B) through composite connections inspired by CBNetv2 to enhance the baseline results. Additionally, we propose two model ensemble methods to further enhance the segmentation effect: one incorporates semantic segmentation into instance segmentation, while the other employs multi-instance segmentation fusion algorithms. Finally, using multi-scale training and test-time augmentation (TTA), we achieve an average mAP@0.50:0.95 of more than 48.49% and an average mAR@0.50:0.95 of 66.71% on the test set of the Data Effificient Defect Detection Challenge. The code is available at https://github.com/love6tao/Aoi-overfitting-team