 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCC-OR-Net: A Unified Framework for LTV Prediction through Structural Decoupling
Jan 15, 2026Customer Lifetime Value (LTV) prediction, a central problem in modern marketing, is characterized by a unique zero-inflated and long-tail data distribution. This distribution presents two fundamental challenges: (1) the vast majority of low-to-medium value users numerically overwhelm the small but critically important segment of high-value "whale" users, and (2) significant value heterogeneity exists even within the low-to-medium value user base. Common approaches either rely on rigid statistical assumptions or attempt to decouple ranking and regression using ordered buckets; however, they often enforce ordinality through loss-based constraints rather than inherent architectural design, failing to balance global accuracy with high-value precision. To address this gap, we propose \textbf{C}onditional \textbf{C}ascaded \textbf{O}rdinal-\textbf{R}esidual Networks \textbf{(CC-OR-Net)}, a novel unified framework that achieves a more robust decoupling through \textbf{structural decomposition}, where ranking is architecturally guaranteed. CC-OR-Net integrates three specialized components: a \textit{structural ordinal decomposition module} for robust ranking, an \textit{intra-bucket residual module} for fine-grained regression, and a \textit{targeted high-value augmentation module} for precision on top-tier users. Evaluated on real-world datasets with over 300M users, CC-OR-Net achieves a superior trade-off across all key business metrics, outperforming state-of-the-art methods in creating a holistic and commercially valuable LTV prediction solution.
Enhancing ID-based Recommendation with Large Language Models
Nov 04, 2024Large Language Models (LLMs) have recently garnered significant attention in various domains, including recommendation systems. Recent research leverages the capabilities of LLMs to improve the performance and user modeling aspects of recommender systems. These studies primarily focus on utilizing LLMs to interpret textual data in recommendation tasks. However, it's worth noting that in ID-based recommendations, textual data is absent, and only ID data is available. The untapped potential of LLMs for ID data within the ID-based recommendation paradigm remains relatively unexplored. To this end, we introduce a pioneering approach called "LLM for ID-based Recommendation" (LLM4IDRec). This innovative approach integrates the capabilities of LLMs while exclusively relying on ID data, thus diverging from the previous reliance on textual data. The basic idea of LLM4IDRec is that by employing LLM to augment ID data, if augmented ID data can improve recommendation performance, it demonstrates the ability of LLM to interpret ID data effectively, exploring an innovative way for the integration of LLM in ID-based recommendation. We evaluate the effectiveness of our LLM4IDRec approach using three widely-used datasets. Our results demonstrate a notable improvement in recommendation performance, with our approach consistently outperforming existing methods in ID-based recommendation by solely augmenting input data.
NEON: Living Needs Prediction System in Meituan
Jul 31, 2023



Living needs refer to the various needs in human's daily lives for survival and well-being, including food, housing, entertainment, etc. On life service platforms that connect users to service providers, such as Meituan, the problem of living needs prediction is fundamental as it helps understand users and boost various downstream applications such as personalized recommendation. However, the problem has not been well explored and is faced with two critical challenges. First, the needs are naturally connected to specific locations and times, suffering from complex impacts from the spatiotemporal context. Second, there is a significant gap between users' actual living needs and their historical records on the platform. To address these two challenges, we design a system of living NEeds predictiON named NEON, consisting of three phases: feature mining, feature fusion, and multi-task prediction. In the feature mining phase, we carefully extract individual-level user features for spatiotemporal modeling, and aggregated-level behavioral features for enriching data, which serve as the basis for addressing two challenges, respectively. Further, in the feature fusion phase, we propose a neural network that effectively fuses two parts of features into the user representation. Moreover, we design a multi-task prediction phase, where the auxiliary task of needs-meeting way prediction can enhance the modeling of spatiotemporal context. Extensive offline evaluations verify that our NEON system can effectively predict users' living needs. Furthermore, we deploy NEON into Meituan's algorithm engine and evaluate how it enhances the three downstream prediction applications, via large-scale online A/B testing.
The Second-place Solution for CVPR VISION 23 Challenge Track 1 -- Data Effificient Defect Detection
Jun 25, 2023



The Vision Challenge Track 1 for Data-Effificient Defect Detection requires competitors to instance segment 14 industrial inspection datasets in a data-defificient setting. This report introduces the technical details of the team Aoi-overfifitting-Team for this challenge. Our method focuses on the key problem of segmentation quality of defect masks in scenarios with limited training samples. Based on the Hybrid Task Cascade (HTC) instance segmentation algorithm, we connect the transformer backbone (Swin-B) through composite connections inspired by CBNetv2 to enhance the baseline results. Additionally, we propose two model ensemble methods to further enhance the segmentation effect: one incorporates semantic segmentation into instance segmentation, while the other employs multi-instance segmentation fusion algorithms. Finally, using multi-scale training and test-time augmentation (TTA), we achieve an average mAP@0.50:0.95 of more than 48.49% and an average mAR@0.50:0.95 of 66.71% on the test set of the Data Effificient Defect Detection Challenge. The code is available at https://github.com/love6tao/Aoi-overfitting-team
Contrastive State Augmentations for Reinforcement Learning-Based Recommender Systems
May 18, 2023



Learning reinforcement learning (RL)-based recommenders from historical user-item interaction sequences is vital to generate high-reward recommendations and improve long-term cumulative benefits. However, existing RL recommendation methods encounter difficulties (i) to estimate the value functions for states which are not contained in the offline training data, and (ii) to learn effective state representations from user implicit feedback due to the lack of contrastive signals. In this work, we propose contrastive state augmentations (CSA) for the training of RL-based recommender systems. To tackle the first issue, we propose four state augmentation strategies to enlarge the state space of the offline data. The proposed method improves the generalization capability of the recommender by making the RL agent visit the local state regions and ensuring the learned value functions are similar between the original and augmented states. For the second issue, we propose introducing contrastive signals between augmented states and the state randomly sampled from other sessions to improve the state representation learning further. To verify the effectiveness of the proposed CSA, we conduct extensive experiments on two publicly accessible datasets and one dataset collected from a real-life e-commerce platform. We also conduct experiments on a simulated environment as the online evaluation setting. Experimental results demonstrate that CSA can effectively improve recommendation performance.
Improving Implicit Feedback-Based Recommendation through Multi-Behavior Alignment
May 09, 2023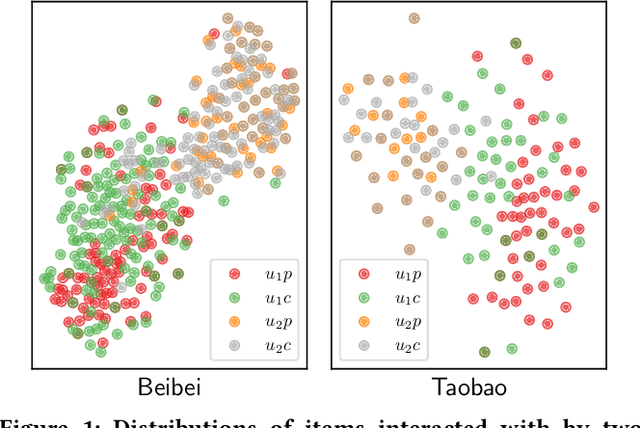
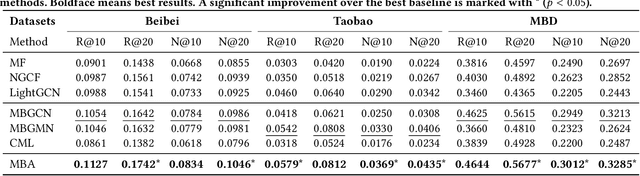
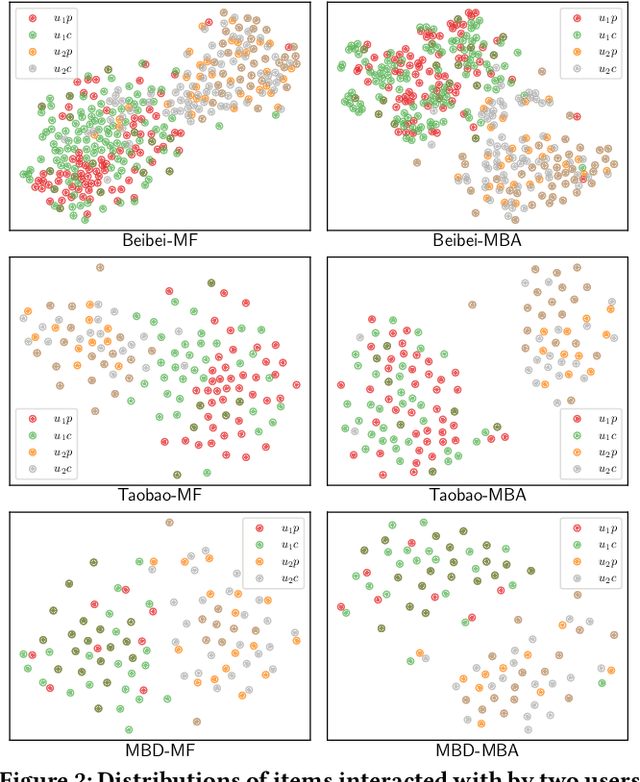
Recommender systems that learn from implicit feedback often use large volumes of a single type of implicit user feedback, such as clicks, to enhance the prediction of sparse target behavior such as purchases. Using multiple types of implicit user feedback for such target behavior prediction purposes is still an open question. Existing studies that attempted to learn from multiple types of user behavior often fail to: (i) learn universal and accurate user preferences from different behavioral data distributions, and (ii) overcome the noise and bias in observed implicit user feedback. To address the above problems, we propose multi-behavior alignment (MBA), a novel recommendation framework that learns from implicit feedback by using multiple types of behavioral data. We conjecture that multiple types of behavior from the same user (e.g., clicks and purchases) should reflect similar preferences of that user. To this end, we regard the underlying universal user preferences as a latent variable. The variable is inferred by maximizing the likelihood of multiple observed behavioral data distributions and, at the same time, minimizing the Kullback-Leibler divergence (KL-divergence) between user models learned from auxiliary behavior (such as clicks or views) and the target behavior separately. MBA infers universal user preferences from multi-behavior data and performs data denoising to enable effective knowledge transfer. We conduct experiments on three datasets, including a dataset collected from an operational e-commerce platform. Empirical results demonstrate the effectiveness of our proposed method in utilizing multiple types of behavioral data to enhance the prediction of the target behavior.
On the User Behavior Leakage from Recommender Exposure
Oct 16, 2022
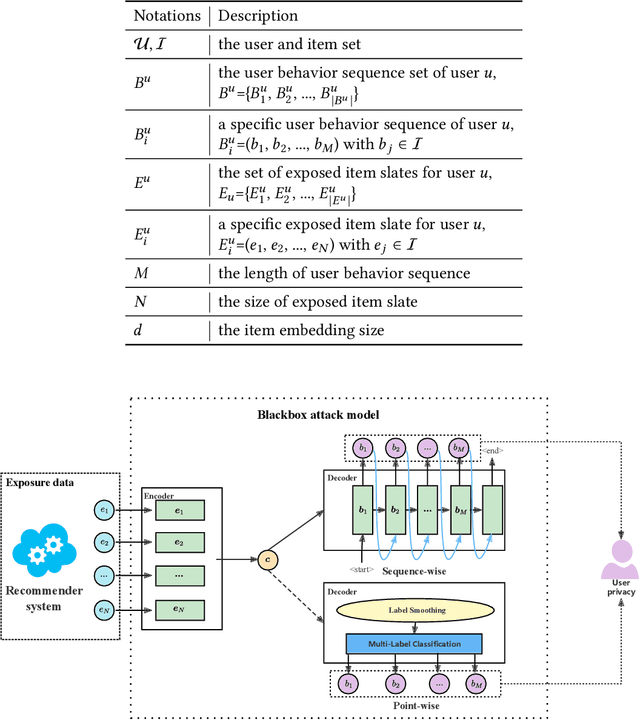
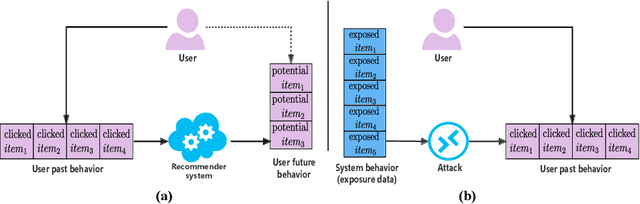
Modern recommender systems are trained to predict users potential future interactions from users historical behavior data. During the interaction process, despite the data coming from the user side recommender systems also generate exposure data to provide users with personalized recommendation slates. Compared with the sparse user behavior data, the system exposure data is much larger in volume since only very few exposed items would be clicked by the user. Besides, the users historical behavior data is privacy sensitive and is commonly protected with careful access authorization. However, the large volume of recommender exposure data usually receives less attention and could be accessed within a relatively larger scope of various information seekers. In this paper, we investigate the problem of user behavior leakage in recommender systems. We show that the privacy sensitive user past behavior data can be inferred through the modeling of system exposure. Besides, one can infer which items the user have clicked just from the observation of current system exposure for this user. Given the fact that system exposure data could be widely accessed from a relatively larger scope, we believe that the user past behavior privacy has a high risk of leakage in recommender systems. More precisely, we conduct an attack model whose input is the current recommended item slate (i.e., system exposure) for the user while the output is the user's historical behavior. Experimental results on two real-world datasets indicate a great danger of user behavior leakage. To address the risk, we propose a two-stage privacy-protection mechanism which firstly selects a subset of items from the exposure slate and then replaces the selected items with uniform or popularity-based exposure. Experimental evaluation reveals a trade-off effect between the recommendation accuracy and the privacy disclosure risk.
Debiasing Learning for Membership Inference Attacks Against Recommender Systems
Jun 28, 2022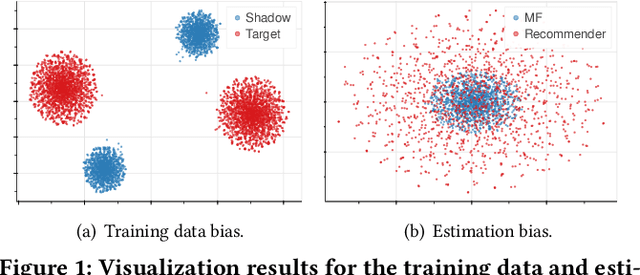
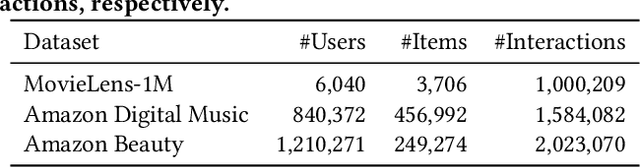
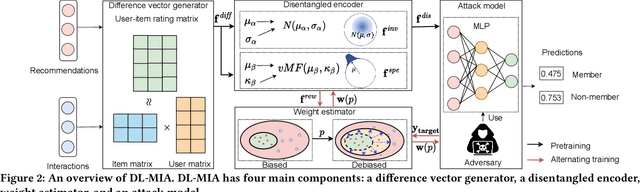

Learned recommender systems may inadvertently leak information about their training data, leading to privacy violations. We investigate privacy threats faced by recommender systems through the lens of membership inference. In such attacks, an adversary aims to infer whether a user's data is used to train the target recommender. To achieve this, previous work has used a shadow recommender to derive training data for the attack model, and then predicts the membership by calculating difference vectors between users' historical interactions and recommended items. State-of-the-art methods face two challenging problems: (1) training data for the attack model is biased due to the gap between shadow and target recommenders, and (2) hidden states in recommenders are not observational, resulting in inaccurate estimations of difference vectors. To address the above limitations, we propose a Debiasing Learning for Membership Inference Attacks against recommender systems (DL-MIA) framework that has four main components: (1) a difference vector generator, (2) a disentangled encoder, (3) a weight estimator, and (4) an attack model. To mitigate the gap between recommenders, a variational auto-encoder (VAE) based disentangled encoder is devised to identify recommender invariant and specific features. To reduce the estimation bias, we design a weight estimator, assigning a truth-level score for each difference vector to indicate estimation accuracy. We evaluate DL-MIA against both general recommenders and sequential recommenders on three real-world datasets. Experimental results show that DL-MIA effectively alleviates training and estimation biases simultaneously, and achieves state-of-the-art attack performance.
NTIRE 2021 Challenge on Perceptual Image Quality Assessment
May 11, 2021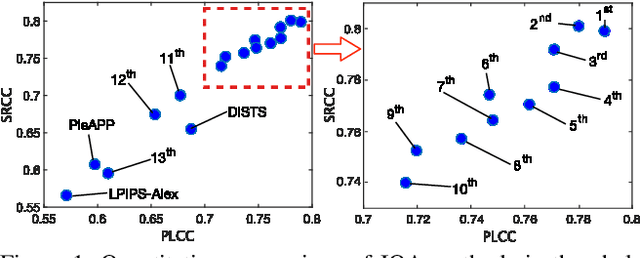
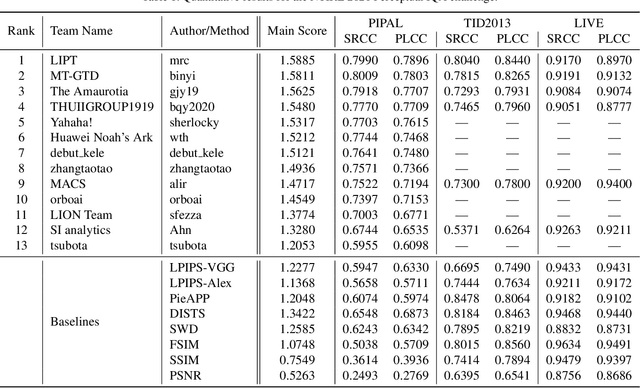

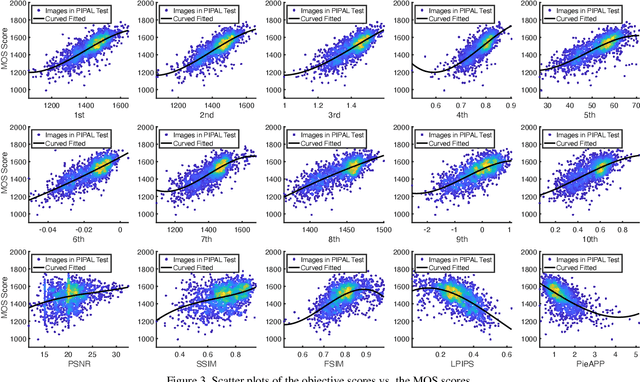
This paper reports on the NTIRE 2021 challenge on perceptual image quality assessment (IQA), held in conjunction with the New Trends in Image Restoration and Enhancement workshop (NTIRE) workshop at CVPR 2021. As a new type of image processing technology, perceptual image processing algorithms based on Generative Adversarial Networks (GAN) have produced images with more realistic textures. These output images have completely different characteristics from traditional distortions, thus pose a new challenge for IQA methods to evaluate their visual quality. In comparison with previous IQA challenges, the training and testing datasets in this challenge include the outputs of perceptual image processing algorithms and the corresponding subjective scores. Thus they can be used to develop and evaluate IQA methods on GAN-based distortions. The challenge has 270 registered participants in total. In the final testing stage, 13 participating teams submitted their models and fact sheets. Almost all of them have achieved much better results than existing IQA methods, while the winning method can demonstrate state-of-the-art performance.