 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoQual: An LLM Agent for Automated Discovery of Interpretable Features for Review Quality Assessment
Oct 09, 2025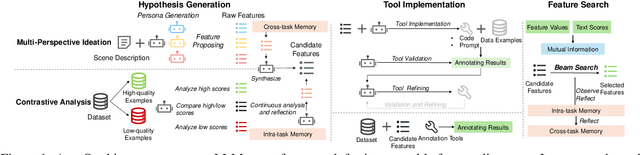
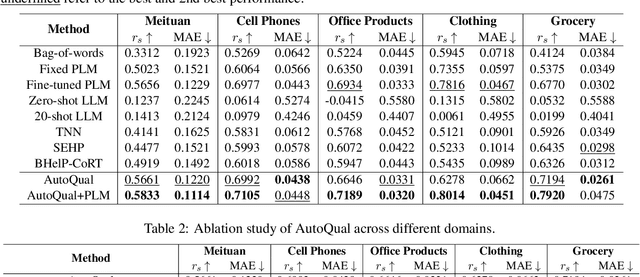
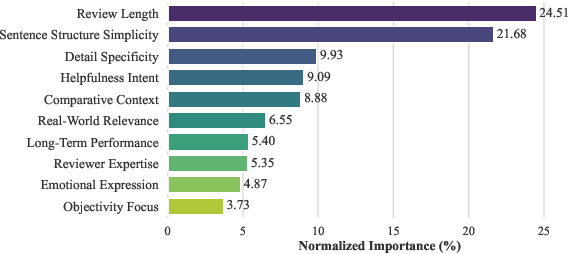
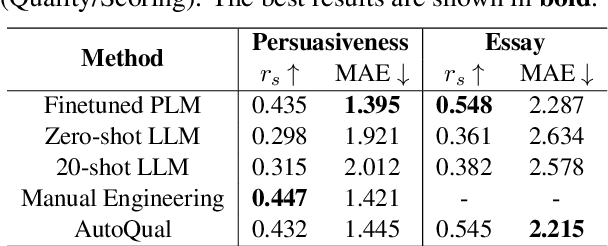
Ranking online reviews by their intrinsic quality is a critical task for e-commerce platforms and information services, impacting user experience and business outcomes. However, quality is a domain-dependent and dynamic concept, making its assessment a formidable challenge. Traditional methods relying on hand-crafted features are unscalable across domains and fail to adapt to evolving content patterns, while modern deep learning approaches often produce black-box models that lack interpretability and may prioritize semantics over quality. To address these challenges, we propose AutoQual, an LLM-based agent framework that automates the discovery of interpretable features. While demonstrated on review quality assessment, AutoQual is designed as a general framework for transforming tacit knowledge embedded in data into explicit, computable features. It mimics a human research process, iteratively generating feature hypotheses through reflection, operationalizing them via autonomous tool implementation, and accumulating experience in a persistent memory. We deploy our method on a large-scale online platform with a billion-level user base. Large-scale A/B testing confirms its effectiveness, increasing average reviews viewed per user by 0.79% and the conversion rate of review readers by 0.27%.
Contrastive State Augmentations for Reinforcement Learning-Based Recommender Systems
May 18, 2023



Learning reinforcement learning (RL)-based recommenders from historical user-item interaction sequences is vital to generate high-reward recommendations and improve long-term cumulative benefits. However, existing RL recommendation methods encounter difficulties (i) to estimate the value functions for states which are not contained in the offline training data, and (ii) to learn effective state representations from user implicit feedback due to the lack of contrastive signals. In this work, we propose contrastive state augmentations (CSA) for the training of RL-based recommender systems. To tackle the first issue, we propose four state augmentation strategies to enlarge the state space of the offline data. The proposed method improves the generalization capability of the recommender by making the RL agent visit the local state regions and ensuring the learned value functions are similar between the original and augmented states. For the second issue, we propose introducing contrastive signals between augmented states and the state randomly sampled from other sessions to improve the state representation learning further. To verify the effectiveness of the proposed CSA, we conduct extensive experiments on two publicly accessible datasets and one dataset collected from a real-life e-commerce platform. We also conduct experiments on a simulated environment as the online evaluation setting. Experimental results demonstrate that CSA can effectively improve recommendation performance.
Improving Implicit Feedback-Based Recommendation through Multi-Behavior Alignment
May 09, 2023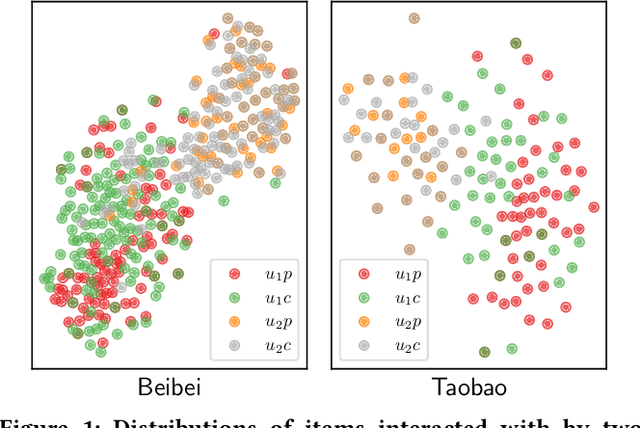
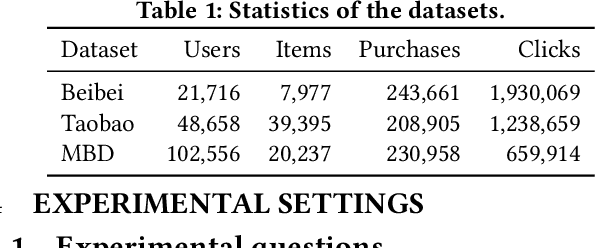
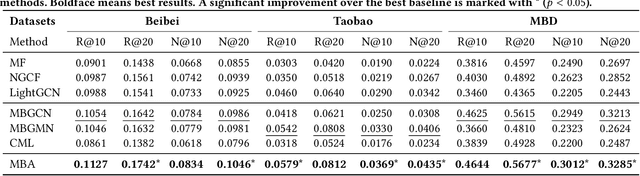
Recommender systems that learn from implicit feedback often use large volumes of a single type of implicit user feedback, such as clicks, to enhance the prediction of sparse target behavior such as purchases. Using multiple types of implicit user feedback for such target behavior prediction purposes is still an open question. Existing studies that attempted to learn from multiple types of user behavior often fail to: (i) learn universal and accurate user preferences from different behavioral data distributions, and (ii) overcome the noise and bias in observed implicit user feedback. To address the above problems, we propose multi-behavior alignment (MBA), a novel recommendation framework that learns from implicit feedback by using multiple types of behavioral data. We conjecture that multiple types of behavior from the same user (e.g., clicks and purchases) should reflect similar preferences of that user. To this end, we regard the underlying universal user preferences as a latent variable. The variable is inferred by maximizing the likelihood of multiple observed behavioral data distributions and, at the same time, minimizing the Kullback-Leibler divergence (KL-divergence) between user models learned from auxiliary behavior (such as clicks or views) and the target behavior separately. MBA infers universal user preferences from multi-behavior data and performs data denoising to enable effective knowledge transfer. We conduct experiments on three datasets, including a dataset collected from an operational e-commerce platform. Empirical results demonstrate the effectiveness of our proposed method in utilizing multiple types of behavioral data to enhance the prediction of the target behavior.
On the User Behavior Leakage from Recommender Exposure
Oct 16, 2022
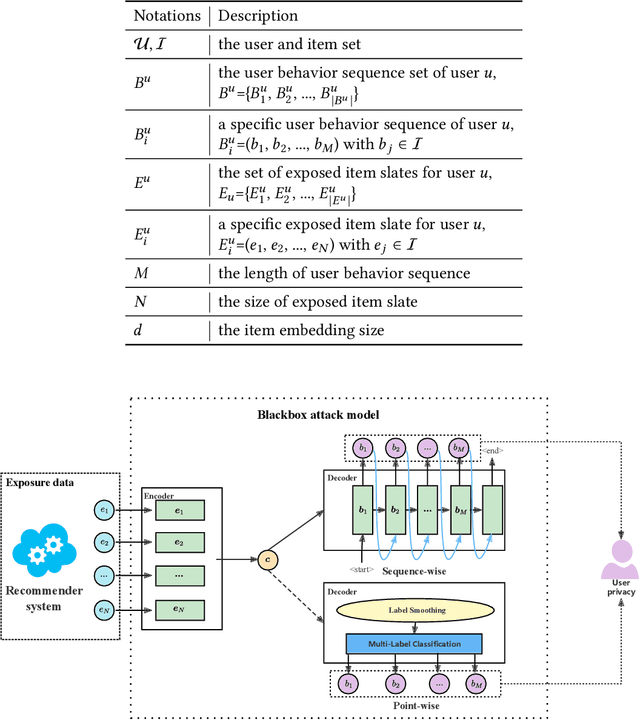
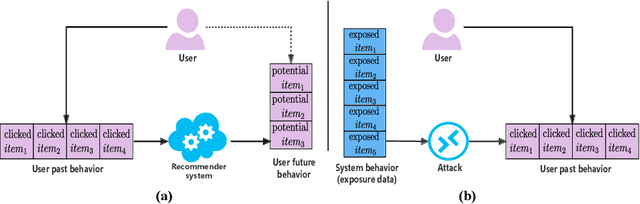
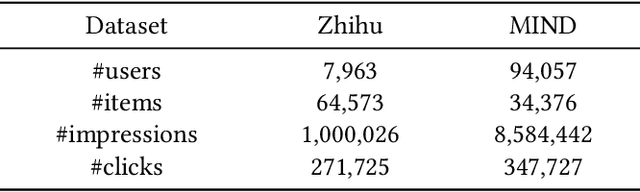
Modern recommender systems are trained to predict users potential future interactions from users historical behavior data. During the interaction process, despite the data coming from the user side recommender systems also generate exposure data to provide users with personalized recommendation slates. Compared with the sparse user behavior data, the system exposure data is much larger in volume since only very few exposed items would be clicked by the user. Besides, the users historical behavior data is privacy sensitive and is commonly protected with careful access authorization. However, the large volume of recommender exposure data usually receives less attention and could be accessed within a relatively larger scope of various information seekers. In this paper, we investigate the problem of user behavior leakage in recommender systems. We show that the privacy sensitive user past behavior data can be inferred through the modeling of system exposure. Besides, one can infer which items the user have clicked just from the observation of current system exposure for this user. Given the fact that system exposure data could be widely accessed from a relatively larger scope, we believe that the user past behavior privacy has a high risk of leakage in recommender systems. More precisely, we conduct an attack model whose input is the current recommended item slate (i.e., system exposure) for the user while the output is the user's historical behavior. Experimental results on two real-world datasets indicate a great danger of user behavior leakage. To address the risk, we propose a two-stage privacy-protection mechanism which firstly selects a subset of items from the exposure slate and then replaces the selected items with uniform or popularity-based exposure. Experimental evaluation reveals a trade-off effect between the recommendation accuracy and the privacy disclosure risk.