 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Generative Recommenders Deepen the Information Cocoon? A Closed-Loop Simulation with LLM-powered User Simulators
Jun 16, 2026Recommender systems alleviate information overload, yet repeated feedback between recommendations and user interactions can reinforce existing preferences and narrow users' exposure, forming information cocoons. While this phenomenon has been widely studied in traditional sequential recommendation, its impact on generative recommendation remains unclear. By replacing atomic item IDs with Semantic ID (SID) sequences, generative recommenders introduce a different recommendation mechanism whose role in information cocoon formation is not yet understood. To investigate whether generative recommenders deepen information cocoons, we propose \textsc{RecLoop}, a closed-loop simulation framework with LLM-driven user agents. We compare two generative recommenders and two traditional sequential baselines on two Amazon datasets across multiple feedback cycles. In addition to standard exposure-level metrics, we introduce \emph{Code-Space Structural Cocoon}, a model-level metric that measures concentration in the generated SID space. Experimental results show that generative recommenders are generally less prone to exposure-level cocoon formation than traditional baselines, preserving broader exposure diversity and slowing cross-user homogenization. However, feedback loops can still induce concentration within the generated SID space. We further find that cocoon severity depends strongly on tokenization strategy and model scale: collaborative-signal tokenization produces stronger cocoon effects than semantic tokenization, whereas larger models maintain greater code-space diversity and better retain access to niche content. These findings suggest that information cocoons in generative recommendation are shaped not only by recommendation behavior, but also by item tokenization and model capacity. Our code is available at https://github.com/Dregen-Yor/RecLoop.
Massive MIMO-OFDM Channel Acquisition with Time-Frequency Phase-Shifted Pilots
May 08, 2025


In this paper, we propose a channel acquisition approach with time-frequency phase-shifted pilots (TFPSPs) for massive multi-input multi-output orthogonal frequency division multiplexing (MIMO-OFDM) systems. We first present a triple-beam (TB) based channel tensor model, allowing for the representation of the space-frequency-time (SFT) domain channel as the product of beam matrices and the TB domain channel tensor. By leveraging the specific characteristics of TB domain channels, we develop TFPSPs, where distinct pilot signals are simultaneously transmitted in the frequency and time domains. Then, we present the optimal TFPSP design and provide the corresponding pilot scheduling algorithm. Further, we propose a tensor-based information geometry approach (IGA) to estimate the TB domain channel tensors. Leveraging the specific structure of beam matrices and the properties of TFPSPs, we propose a low-complexity implementation of the tensor-based IGA. We validate the efficiency of our proposed channel acquisition approach through extensive simulations. Simulation results demonstrate the superior performance of our approach. The proposed approach can effectively suppress inter-UT interference with low complexity and limited pilot overhead, thereby enhancing channel estimation performance. Particularly in scenarios with a large number of UTs, the channel acquisition method outperforms existing approaches by reducing the normalized mean square error (NMSE) by more than 8 dB.
Improving Sequential Recommenders through Counterfactual Augmentation of System Exposure
Apr 18, 2025In sequential recommendation (SR), system exposure refers to items that are exposed to the user. Typically, only a few of the exposed items would be interacted with by the user. Although SR has achieved great success in predicting future user interests, existing SR methods still fail to fully exploit system exposure data. Most methods only model items that have been interacted with, while the large volume of exposed but non-interacted items is overlooked. Even methods that consider the whole system exposure typically train the recommender using only the logged historical system exposure, without exploring unseen user interests. In this paper, we propose counterfactual augmentation over system exposure for sequential recommendation (CaseRec). To better model historical system exposure, CaseRec introduces reinforcement learning to account for different exposure rewards. CaseRec uses a decision transformer-based sequential model to take an exposure sequence as input and assigns different rewards according to the user feedback. To further explore unseen user interests, CaseRec proposes to perform counterfactual augmentation, where exposed original items are replaced with counterfactual items. Then, a transformer-based user simulator is proposed to predict the user feedback reward for the augmented items. Augmentation, together with the user simulator, constructs counterfactual exposure sequences to uncover new user interests. Finally, CaseRec jointly uses the logged exposure sequences with the counterfactual exposure sequences to train a decision transformer-based sequential model for generating recommendation. Experiments on three real-world benchmarks show the effectiveness of CaseRec. Our code is available at https://github.com/ZiqiZhao1/CaseRec.
Constrained Auto-Regressive Decoding Constrains Generative Retrieval
Apr 14, 2025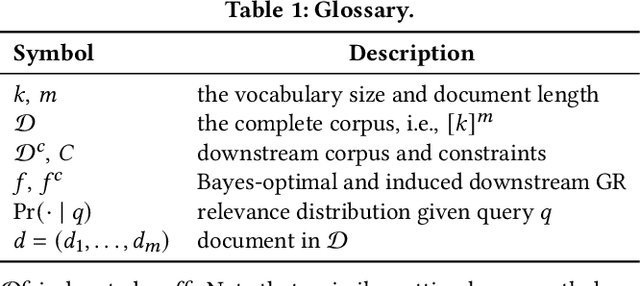
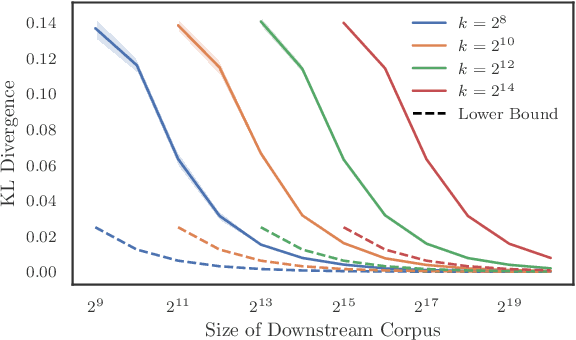
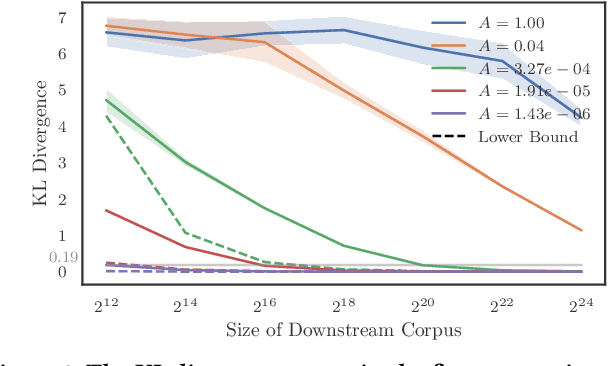
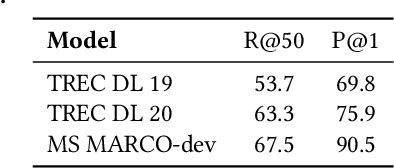
Generative retrieval seeks to replace traditional search index data structures with a single large-scale neural network, offering the potential for improved efficiency and seamless integration with generative large language models. As an end-to-end paradigm, generative retrieval adopts a learned differentiable search index to conduct retrieval by directly generating document identifiers through corpus-specific constrained decoding. The generalization capabilities of generative retrieval on out-of-distribution corpora have gathered significant attention. In this paper, we examine the inherent limitations of constrained auto-regressive generation from two essential perspectives: constraints and beam search. We begin with the Bayes-optimal setting where the generative retrieval model exactly captures the underlying relevance distribution of all possible documents. Then we apply the model to specific corpora by simply adding corpus-specific constraints. Our main findings are two-fold: (i) For the effect of constraints, we derive a lower bound of the error, in terms of the KL divergence between the ground-truth and the model-predicted step-wise marginal distributions. (ii) For the beam search algorithm used during generation, we reveal that the usage of marginal distributions may not be an ideal approach. This paper aims to improve our theoretical understanding of the generalization capabilities of the auto-regressive decoding retrieval paradigm, laying a foundation for its limitations and inspiring future advancements toward more robust and generalizable generative retrieval.
To Use or Not to Use a Universal Force Field
Mar 11, 2025


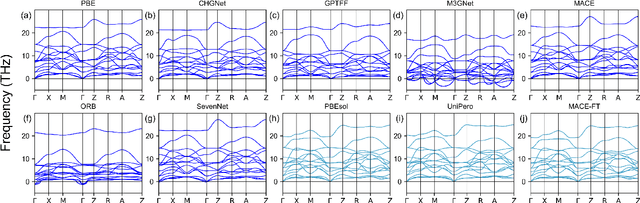
Artificial intelligence (AI) is revolutionizing scientific research, particularly in computational materials science, by enabling more accurate and efficient simulations. Machine learning force fields (MLFFs) have emerged as powerful tools for molecular dynamics (MD) simulations, potentially offering quantum-mechanical accuracy with the efficiency of classical MD. This Perspective evaluates the viability of universal MLFFs for simulating complex materials systems from the standpoint of a potential practitioner. Using the temperature-driven ferroelectric-paraelectric phase transition of PbTiO$_3$ as a benchmark, we assess leading universal force fields, including CHGNet, MACE, M3GNet, and GPTFF, alongside specialized models like UniPero. While universal MLFFs trained on PBE-derived datasets perform well in predicting equilibrium properties, they largely fail to capture realistic finite-temperature phase transitions under constant-pressure MD, often exhibiting unphysical instabilities. These shortcomings stem from inherited biases in exchange-correlation functionals and limited generalization to anharmonic interactions governing dynamic behavior. However, fine-tuning universal models or employing system-specific MLFFs like UniPero successfully restores predictive accuracy. We advocates for hybrid approaches combining universal pretraining with targeted optimization, improved error quantification frameworks, and community-driven benchmarks to advance MLFFs as robust tools for computational materials discovery.
TL-CLIP: A Power-specific Multimodal Pre-trained Visual Foundation Model for Transmission Line Defect Recognition
Nov 18, 2024



Transmission line defect recognition models have traditionally used general pre-trained weights as the initial basis for their training. These models often suffer weak generalization capability due to the lack of domain knowledge in the pre-training dataset. To address this issue, we propose a two-stage transmission-line-oriented contrastive language-image pre-training (TL-CLIP) framework, which lays a more effective foundation for transmission line defect recognition. The pre-training process employs a novel power-specific multimodal algorithm assisted with two power-specific pre-training tasks for better modeling the power-related semantic knowledge contained in the inspection data. To fine-tune the pre-trained model, we develop a transfer learning strategy, namely fine-tuning with pre-training objective (FTP), to alleviate the overfitting problem caused by limited inspection data. Experimental results demonstrate that the proposed method significantly improves the performance of transmission line defect recognition in both classification and detection tasks, indicating clear advantages over traditional pre-trained models in the scene of transmission line inspection.
Enhanced Generative Recommendation via Content and Collaboration Integration
Mar 27, 2024Generative recommendation has emerged as a promising paradigm aimed at augmenting recommender systems with recent advancements in generative artificial intelligence. This task has been formulated as a sequence-to-sequence generation process, wherein the input sequence encompasses data pertaining to the user's previously interacted items, and the output sequence denotes the generative identifier for the suggested item. However, existing generative recommendation approaches still encounter challenges in (i) effectively integrating user-item collaborative signals and item content information within a unified generative framework, and (ii) executing an efficient alignment between content information and collaborative signals. In this paper, we introduce content-based collaborative generation for recommender systems, denoted as ColaRec. To capture collaborative signals, the generative item identifiers are derived from a pretrained collaborative filtering model, while the user is represented through the aggregation of interacted items' content. Subsequently, the aggregated textual description of items is fed into a language model to encapsulate content information. This integration enables ColaRec to amalgamate collaborative signals and content information within an end-to-end framework. Regarding the alignment, we propose an item indexing task to facilitate the mapping between the content-based semantic space and the interaction-based collaborative space. Additionally, a contrastive loss is introduced to ensure that items with similar collaborative GIDs possess comparable content representations, thereby enhancing alignment. To validate the efficacy of ColaRec, we conduct experiments on three benchmark datasets. Empirical results substantiate the superior performance of ColaRec.
Uncovering Selective State Space Model's Capabilities in Lifelong Sequential Recommendation
Mar 25, 2024



Sequential Recommenders have been widely applied in various online services, aiming to model users' dynamic interests from their sequential interactions. With users increasingly engaging with online platforms, vast amounts of lifelong user behavioral sequences have been generated. However, existing sequential recommender models often struggle to handle such lifelong sequences. The primary challenges stem from computational complexity and the ability to capture long-range dependencies within the sequence. Recently, a state space model featuring a selective mechanism (i.e., Mamba) has emerged. In this work, we investigate the performance of Mamba for lifelong sequential recommendation (i.e., length>=2k). More specifically, we leverage the Mamba block to model lifelong user sequences selectively. We conduct extensive experiments to evaluate the performance of representative sequential recommendation models in the setting of lifelong sequences. Experiments on two real-world datasets demonstrate the superiority of Mamba. We found that RecMamba achieves performance comparable to the representative model while significantly reducing training duration by approximately 70% and memory costs by 80%. Codes and data are available at \url{https://github.com/nancheng58/RecMamba}.
Debiasing Sequential Recommenders through Distributionally Robust Optimization over System Exposure
Dec 12, 2023



Sequential recommendation (SR) models are typically trained on user-item interactions which are affected by the system exposure bias, leading to the user preference learned from the biased SR model not being fully consistent with the true user preference. Exposure bias refers to the fact that user interactions are dependent upon the partial items exposed to the user. Existing debiasing methods do not make full use of the system exposure data and suffer from sub-optimal recommendation performance and high variance. In this paper, we propose to debias sequential recommenders through Distributionally Robust Optimization (DRO) over system exposure data. The key idea is to utilize DRO to optimize the worst-case error over an uncertainty set to safeguard the model against distributional discrepancy caused by the exposure bias. The main challenge to apply DRO for exposure debiasing in SR lies in how to construct the uncertainty set and avoid the overestimation of user preference on biased samples. Moreover, how to evaluate the debiasing effect on biased test set is also an open question. To this end, we first introduce an exposure simulator trained upon the system exposure data to calculate the exposure distribution, which is then regarded as the nominal distribution to construct the uncertainty set of DRO. Then, we introduce a penalty to items with high exposure probability to avoid the overestimation of user preference for biased samples. Finally, we design a debiased self-normalized inverse propensity score (SNIPS) evaluator for evaluating the debiasing effect on the biased offline test set. We conduct extensive experiments on two real-world datasets to verify the effectiveness of the proposed methods. Experimental results demonstrate the superior exposure debiasing performance of proposed methods. Codes and data are available at \url{https://github.com/nancheng58/DebiasedSR_DRO}.
On the User Behavior Leakage from Recommender Exposure
Oct 16, 2022
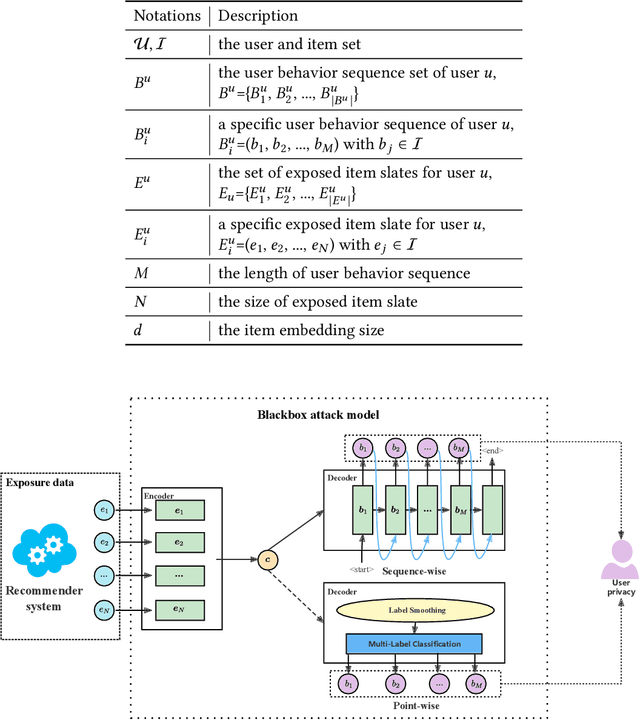
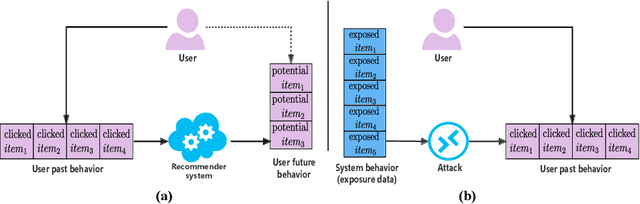
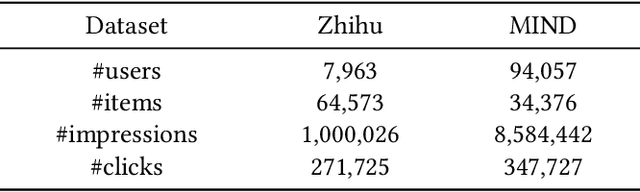
Modern recommender systems are trained to predict users potential future interactions from users historical behavior data. During the interaction process, despite the data coming from the user side recommender systems also generate exposure data to provide users with personalized recommendation slates. Compared with the sparse user behavior data, the system exposure data is much larger in volume since only very few exposed items would be clicked by the user. Besides, the users historical behavior data is privacy sensitive and is commonly protected with careful access authorization. However, the large volume of recommender exposure data usually receives less attention and could be accessed within a relatively larger scope of various information seekers. In this paper, we investigate the problem of user behavior leakage in recommender systems. We show that the privacy sensitive user past behavior data can be inferred through the modeling of system exposure. Besides, one can infer which items the user have clicked just from the observation of current system exposure for this user. Given the fact that system exposure data could be widely accessed from a relatively larger scope, we believe that the user past behavior privacy has a high risk of leakage in recommender systems. More precisely, we conduct an attack model whose input is the current recommended item slate (i.e., system exposure) for the user while the output is the user's historical behavior. Experimental results on two real-world datasets indicate a great danger of user behavior leakage. To address the risk, we propose a two-stage privacy-protection mechanism which firstly selects a subset of items from the exposure slate and then replaces the selected items with uniform or popularity-based exposure. Experimental evaluation reveals a trade-off effect between the recommendation accuracy and the privacy disclosure risk.