 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTL-CLIP: A Power-specific Multimodal Pre-trained Visual Foundation Model for Transmission Line Defect Recognition
Nov 18, 2024



Transmission line defect recognition models have traditionally used general pre-trained weights as the initial basis for their training. These models often suffer weak generalization capability due to the lack of domain knowledge in the pre-training dataset. To address this issue, we propose a two-stage transmission-line-oriented contrastive language-image pre-training (TL-CLIP) framework, which lays a more effective foundation for transmission line defect recognition. The pre-training process employs a novel power-specific multimodal algorithm assisted with two power-specific pre-training tasks for better modeling the power-related semantic knowledge contained in the inspection data. To fine-tune the pre-trained model, we develop a transfer learning strategy, namely fine-tuning with pre-training objective (FTP), to alleviate the overfitting problem caused by limited inspection data. Experimental results demonstrate that the proposed method significantly improves the performance of transmission line defect recognition in both classification and detection tasks, indicating clear advantages over traditional pre-trained models in the scene of transmission line inspection.
ATRM: Attention-based Task-level Relation Module for GNN-based Few-shot Learning
Jan 25, 2021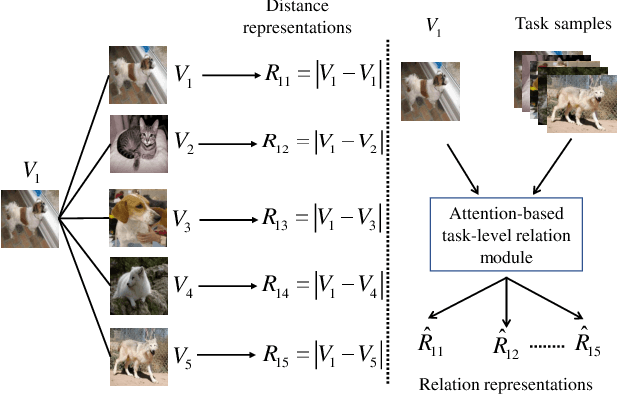
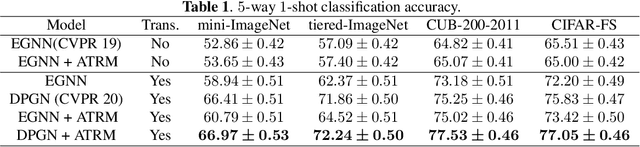
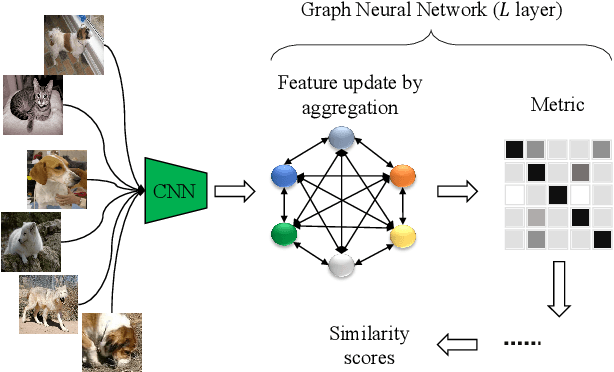
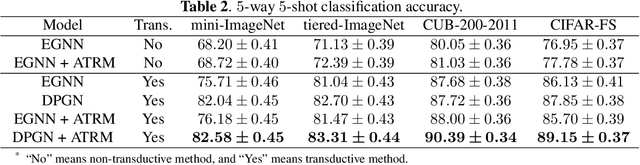
Recently, graph neural networks (GNNs) have shown powerful ability to handle few-shot classification problem, which aims at classifying unseen samples when trained with limited labeled samples per class. GNN-based few-shot learning architectures mostly replace traditional metric with a learnable GNN. In the GNN, the nodes are set as the samples embedding, and the relationship between two connected nodes can be obtained by a network, the input of which is the difference of their embedding features. We consider this method of measuring relation of samples only models the sample-to-sample relation, while neglects the specificity of different tasks. That is, this method of measuring relation does not take the task-level information into account. To this end, we propose a new relation measure method, namely the attention-based task-level relation module (ATRM), to explicitly model the task-level relation of one sample to all the others. The proposed module captures the relation representations between nodes by considering the sample-to-task instead of sample-to-sample embedding features. We conducted extensive experiments on four benchmark datasets: mini-ImageNet, tiered-ImageNet, CUB-200-2011, and CIFAR-FS. Experimental results demonstrate that the proposed module is effective for GNN-based few-shot learning.
Competing Ratio Loss for Discriminative Multi-class Image Classification
Dec 25, 2019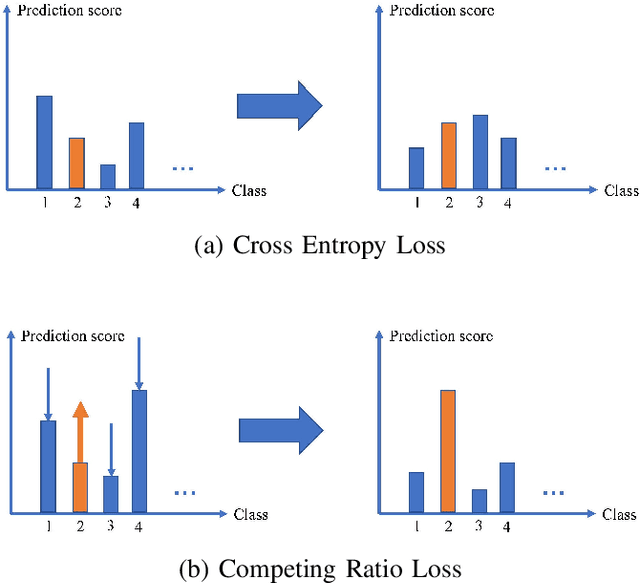
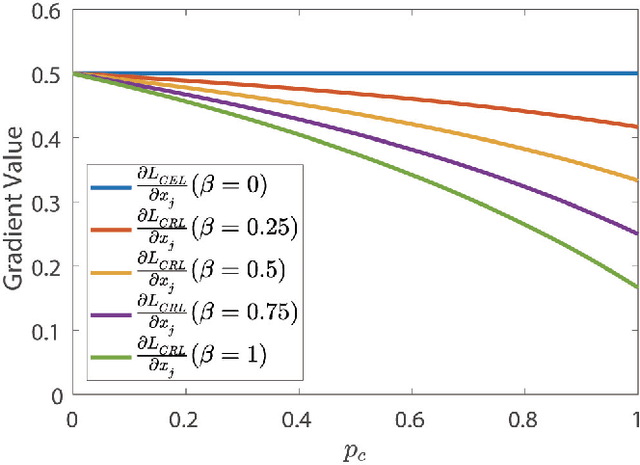
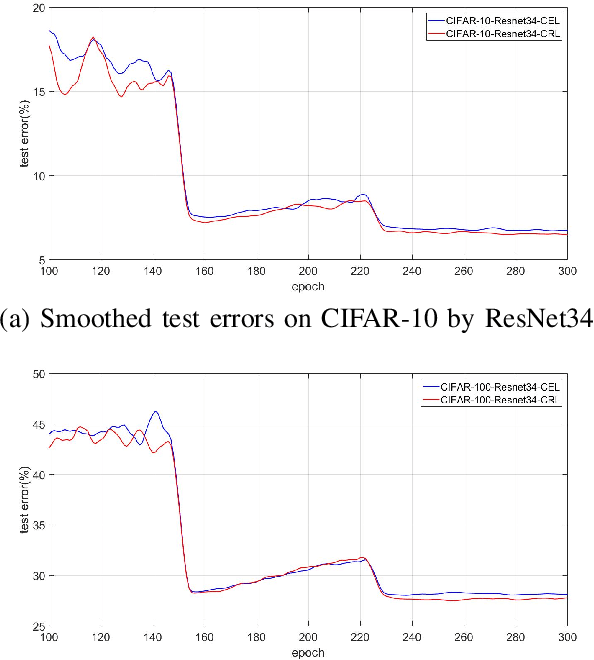

The development of deep convolutional neural network architecture is critical to the improvement of image classification task performance. Many image classification studies use deep convolutional neural network and focus on modifying the network structure to improve image classification performance. Conversely, our study focuses on loss function design. Cross-entropy Loss (CEL) has been widely used for training deep convolutional neural network for the task of multi-class classification. Although CEL has been successfully implemented in several image classification tasks, it only focuses on the posterior probability of the correct class. For this reason, a negative log likelihood ratio loss (NLLR) was proposed to better differentiate between the correct class and the competing incorrect ones. However, during the training of the deep convolutional neural network, the value of NLLR is not always positive or negative, which severely affects the convergence of NLLR. Our proposed competing ratio loss (CRL) calculates the posterior probability ratio between the correct class and the competing incorrect classes to further enlarge the probability difference between the correct and incorrect classes. We added hyperparameters to CRL, thereby ensuring its value to be positive and that the update size of backpropagation is suitable for the CRL's fast convergence. To demonstrate the performance of CRL, we conducted experiments on general image classification tasks (CIFAR10/100, SVHN, ImageNet), the fine-grained image classification tasks (CUB200-2011 and Stanford Car), and the challenging face age estimation task (using Adience). Experimental results show the effectiveness and robustness of the proposed loss function on different deep convolutional neural network architectures and different image classification tasks.