 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMU-GAN: Facial Attribute Editing based on Multi-attention Mechanism
Sep 09, 2020

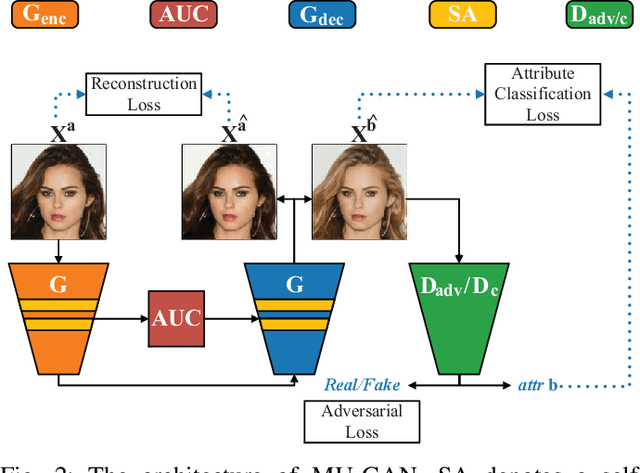

Facial attribute editing has mainly two objectives: 1) translating image from a source domain to a target one, and 2) only changing the facial regions related to a target attribute and preserving the attribute-excluding details. In this work, we propose a Multi-attention U-Net-based Generative Adversarial Network (MU-GAN). First, we replace a classic convolutional encoder-decoder with a symmetric U-Net-like structure in a generator, and then apply an additive attention mechanism to build attention-based U-Net connections for adaptively transferring encoder representations to complement a decoder with attribute-excluding detail and enhance attribute editing ability. Second, a self-attention mechanism is incorporated into convolutional layers for modeling long-range and multi-level dependencies across image regions. experimental results indicate that our method is capable of balancing attribute editing ability and details preservation ability, and can decouple the correlation among attributes. It outperforms the state-of-the-art methods in terms of attribute manipulation accuracy and image quality.
Detection Method Based on Automatic Visual Shape Clustering for Pin-Missing Defect in Transmission Lines
Jan 17, 2020
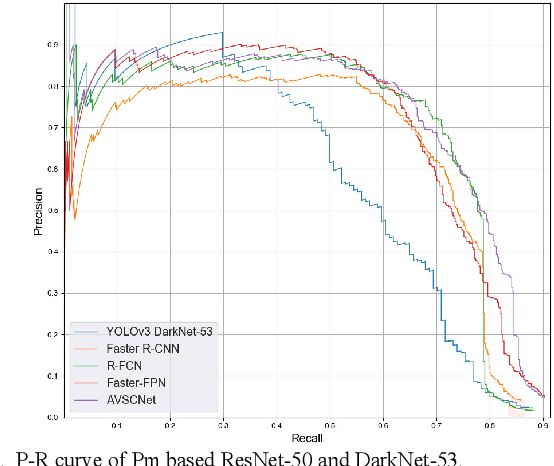


Bolts are the most numerous fasteners in transmission lines and are prone to losing their split pins. How to realize the automatic pin-missing defect detection for bolts in transmission lines so as to achieve timely and efficient trouble shooting is a difficult problem and the long-term research target of power systems. In this paper, an automatic detection model called Automatic Visual Shape Clustering Network (AVSCNet) for pin-missing defect is constructed. Firstly, an unsupervised clustering method for the visual shapes of bolts is proposed and applied to construct a defect detection model which can learn the difference of visual shape. Next, three deep convolutional neural network optimization methods are used in the model: the feature enhancement, feature fusion and region feature extraction. The defect detection results are obtained by applying the regression calculation and classification to the regional features. In this paper, the object detection model of different networks is used to test the dataset of pin-missing defect constructed by the aerial images of transmission lines from multiple locations, and it is evaluated by various indicators and is fully verified. The results show that our method can achieve considerably satisfactory detection effect.
Competing Ratio Loss for Discriminative Multi-class Image Classification
Dec 25, 2019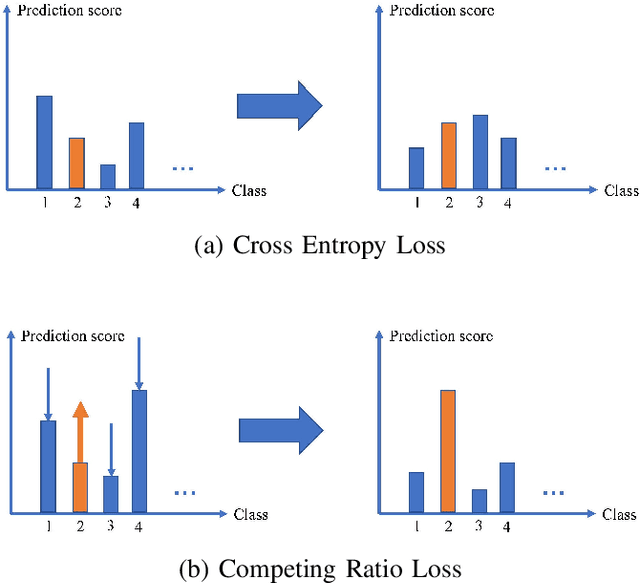
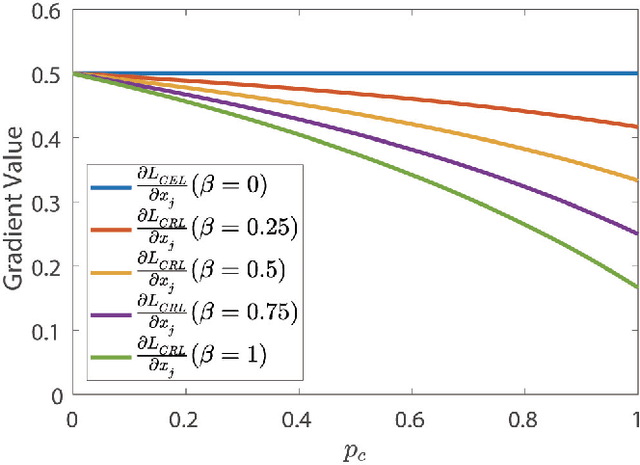
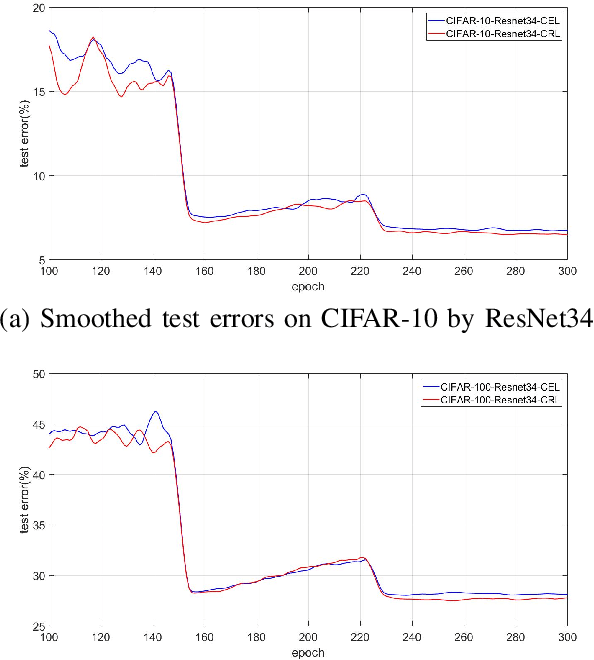

The development of deep convolutional neural network architecture is critical to the improvement of image classification task performance. Many image classification studies use deep convolutional neural network and focus on modifying the network structure to improve image classification performance. Conversely, our study focuses on loss function design. Cross-entropy Loss (CEL) has been widely used for training deep convolutional neural network for the task of multi-class classification. Although CEL has been successfully implemented in several image classification tasks, it only focuses on the posterior probability of the correct class. For this reason, a negative log likelihood ratio loss (NLLR) was proposed to better differentiate between the correct class and the competing incorrect ones. However, during the training of the deep convolutional neural network, the value of NLLR is not always positive or negative, which severely affects the convergence of NLLR. Our proposed competing ratio loss (CRL) calculates the posterior probability ratio between the correct class and the competing incorrect classes to further enlarge the probability difference between the correct and incorrect classes. We added hyperparameters to CRL, thereby ensuring its value to be positive and that the update size of backpropagation is suitable for the CRL's fast convergence. To demonstrate the performance of CRL, we conducted experiments on general image classification tasks (CIFAR10/100, SVHN, ImageNet), the fine-grained image classification tasks (CUB200-2011 and Stanford Car), and the challenging face age estimation task (using Adience). Experimental results show the effectiveness and robustness of the proposed loss function on different deep convolutional neural network architectures and different image classification tasks.
Fine-Grained Age Estimation in the wild with Attention LSTM Networks
May 26, 2018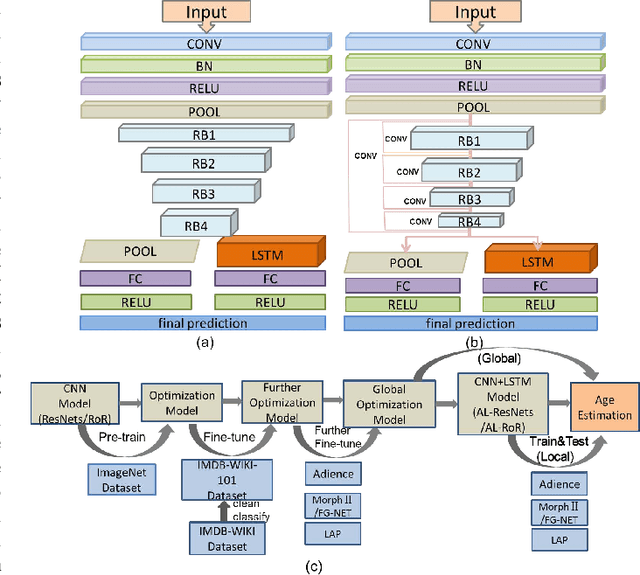
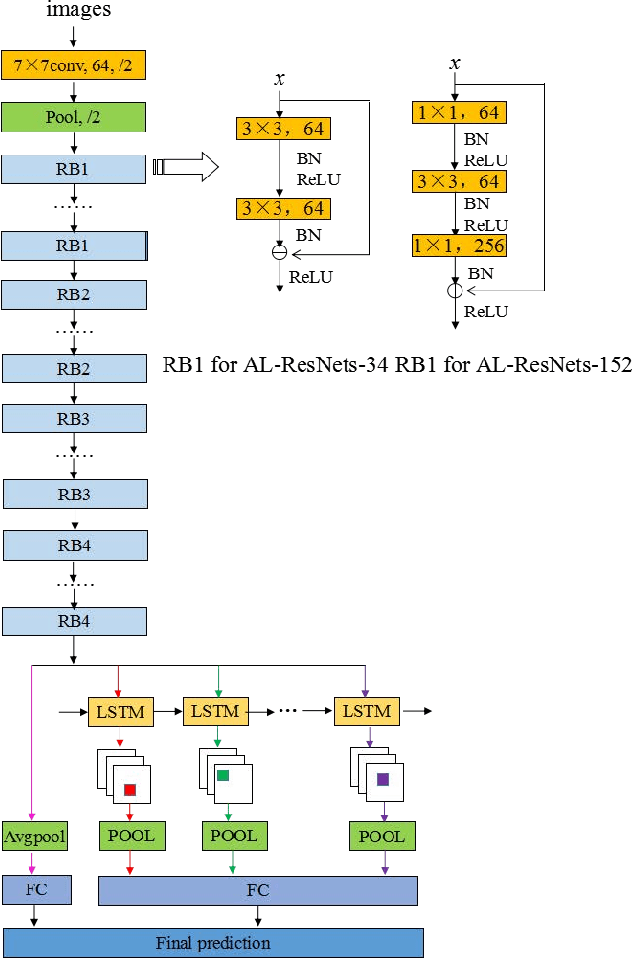
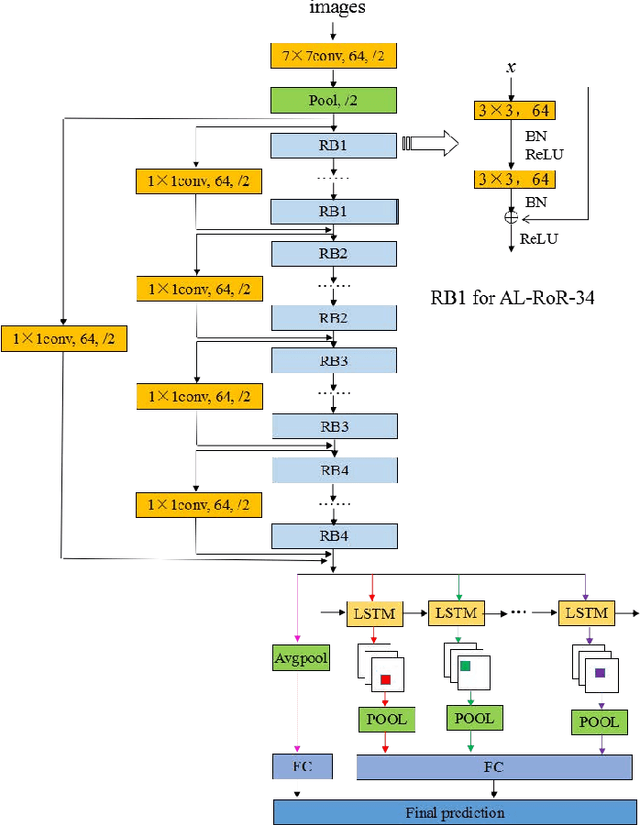
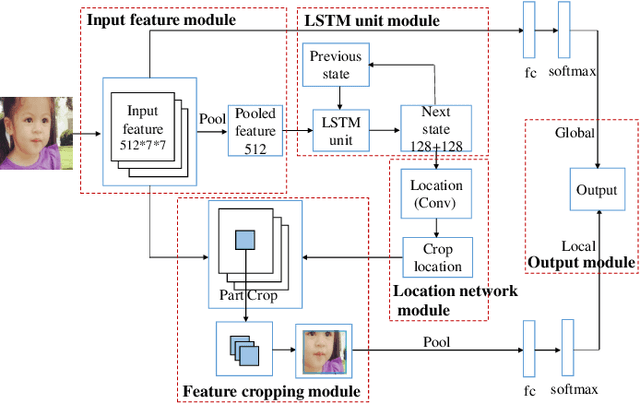
Age estimation from a single face image has been an essential task in the field of human-computer interaction and computer vision which has a wide range of practical application value. Concerning the problem that accuracy of age estimation of face images in the wild are relatively low for existing methods, where they take into account only the whole features of face image while neglecting the fine-grained features of age-sensitive area, we propose a method based on Attention LSTM network for Fine-Grained age estimation in the wild based on the idea of Fine-Grained categories and visual attention mechanism. This method combines ResNets or RoR models with LSTM unit to construct AL-ResNets or AL-RoR networks to extract age-sensitive local regions, which effectively improves age estimation accuracy. Firstly, ResNets or RoR model pre-trained on ImageNet dataset is selected as the basic model, which is then fine-tuned on the IMDB-WIKI-101 dataset for age estimation. Then, we fine-tune ResNets or RoR on the target age datasets to extract the global features of face images. To extract the local characteristics of age-sensitive areas, the LSTM unit is then presented to obtain the coordinates of the age-sensitive region automatically. Finally, the age group classification experiment is conducted directly on the Adience dataset, and age-regression experiments are performed by the Deep EXpectation algorithm (DEX) on MORPH Album 2, FG-NET and LAP datasets. By combining the global and local features, we got our final prediction results. Our experiments illustrate the effectiveness of AL-ResNets or AL-RoR for age estimation in the wild, where it achieves new state-of-the-art performance than all other CNN methods on the Adience, MORPH Album 2, FG-NET and LAP datasets.
Age Group and Gender Estimation in the Wild with Deep RoR Architecture
Oct 09, 2017
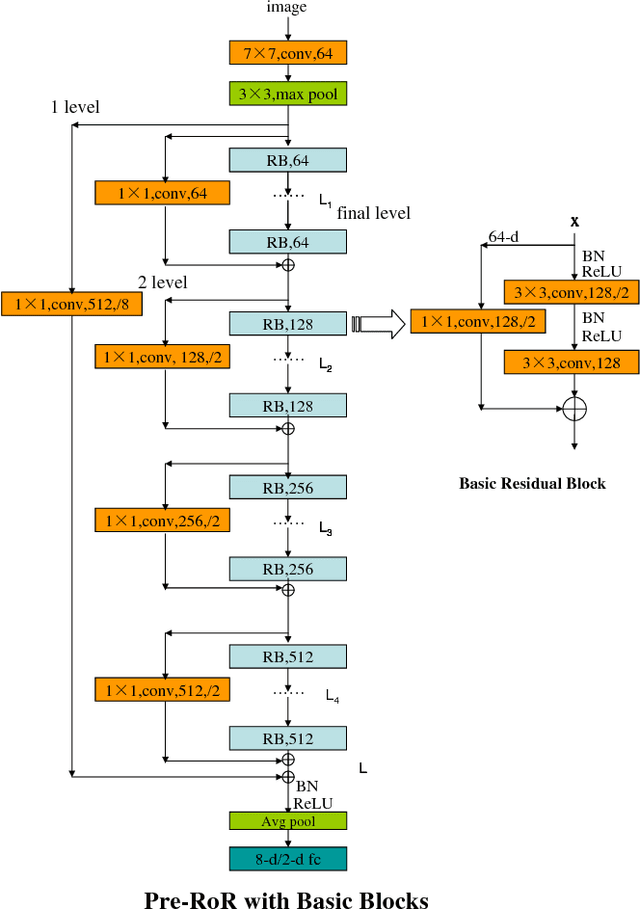
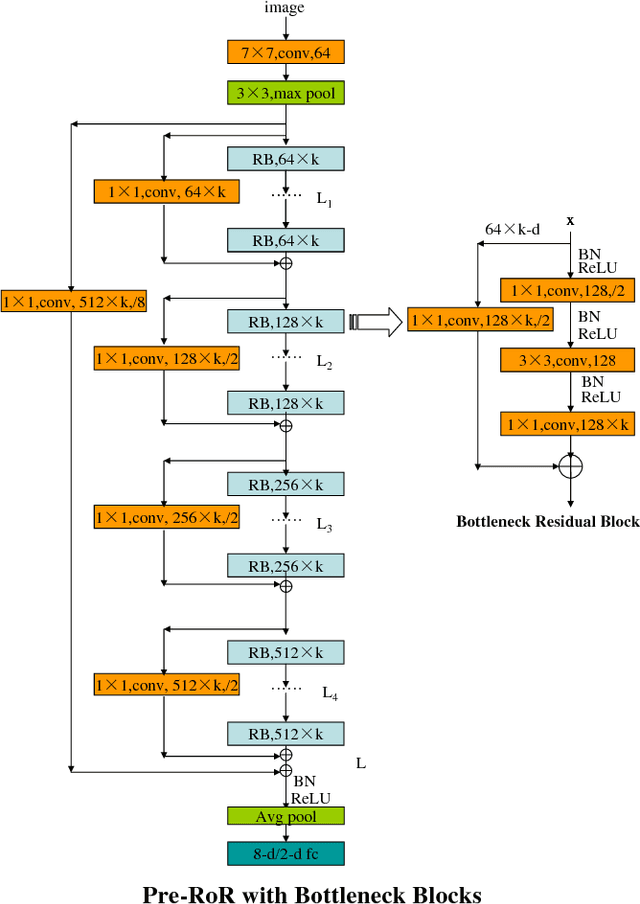
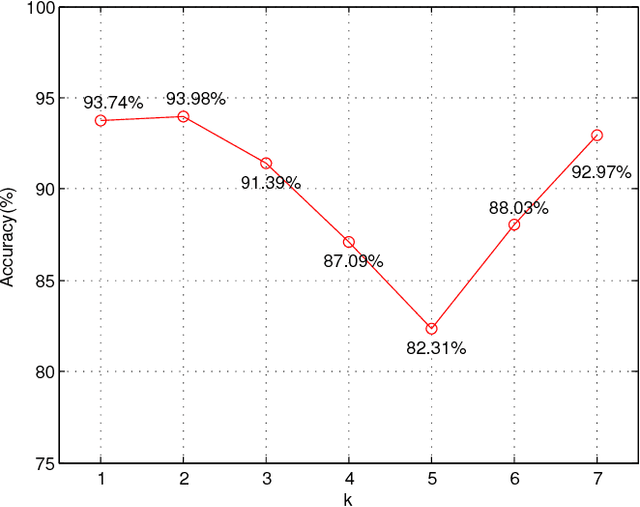
Automatically predicting age group and gender from face images acquired in unconstrained conditions is an important and challenging task in many real-world applications. Nevertheless, the conventional methods with manually-designed features on in-the-wild benchmarks are unsatisfactory because of incompetency to tackle large variations in unconstrained images. This difficulty is alleviated to some degree through Convolutional Neural Networks (CNN) for its powerful feature representation. In this paper, we propose a new CNN based method for age group and gender estimation leveraging Residual Networks of Residual Networks (RoR), which exhibits better optimization ability for age group and gender classification than other CNN architectures.Moreover, two modest mechanisms based on observation of the characteristics of age group are presented to further improve the performance of age estimation.In order to further improve the performance and alleviate over-fitting problem, RoR model is pre-trained on ImageNet firstly, and then it is fune-tuned on the IMDB-WIKI-101 data set for further learning the features of face images, finally, it is used to fine-tune on Adience data set. Our experiments illustrate the effectiveness of RoR method for age and gender estimation in the wild, where it achieves better performance than other CNN methods. Finally, the RoR-152+IMDB-WIKI-101 with two mechanisms achieves new state-of-the-art results on Adience benchmark.
Pyramidal RoR for Image Classification
Oct 01, 2017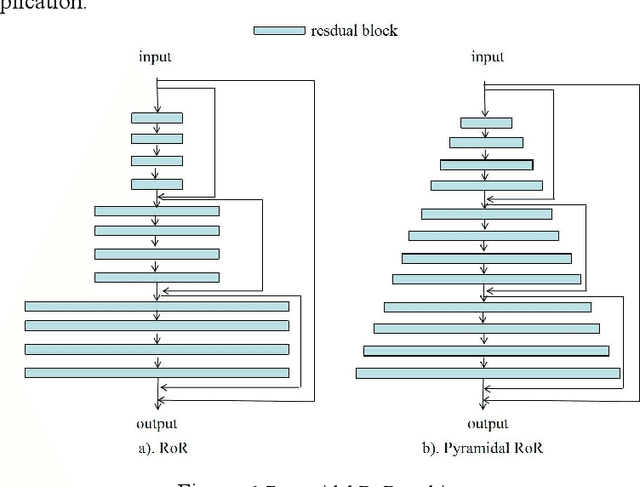


The Residual Networks of Residual Networks (RoR) exhibits excellent performance in the image classification task, but sharply increasing the number of feature map channels makes the characteristic information transmission incoherent, which losses a certain of information related to classification prediction, limiting the classification performance. In this paper, a Pyramidal RoR network model is proposed by analysing the performance characteristics of RoR and combining with the PyramidNet. Firstly, based on RoR, the Pyramidal RoR network model with channels gradually increasing is designed. Secondly, we analysed the effect of different residual block structures on performance, and chosen the residual block structure which best favoured the classification performance. Finally, we add an important principle to further optimize Pyramidal RoR networks, drop-path is used to avoid over-fitting and save training time. In this paper, image classification experiments were performed on CIFAR-10/100 and SVHN datasets, and we achieved the current lowest classification error rates were 2.96%, 16.40% and 1.59%, respectively. Experiments show that the Pyramidal RoR network optimization method can improve the network performance for different data sets and effectively suppress the gradient disappearance problem in DCNN training.