 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAwakening Facial Emotional Expressions in Human-Robot
Oct 27, 2025The facial expression generation capability of humanoid social robots is critical for achieving natural and human-like interactions, playing a vital role in enhancing the fluidity of human-robot interactions and the accuracy of emotional expression. Currently, facial expression generation in humanoid social robots still relies on pre-programmed behavioral patterns, which are manually coded at high human and time costs. To enable humanoid robots to autonomously acquire generalized expressive capabilities, they need to develop the ability to learn human-like expressions through self-training. To address this challenge, we have designed a highly biomimetic robotic face with physical-electronic animated facial units and developed an end-to-end learning framework based on KAN (Kolmogorov-Arnold Network) and attention mechanisms. Unlike previous humanoid social robots, we have also meticulously designed an automated data collection system based on expert strategies of facial motion primitives to construct the dataset. Notably, to the best of our knowledge, this is the first open-source facial dataset for humanoid social robots. Comprehensive evaluations indicate that our approach achieves accurate and diverse facial mimicry across different test subjects.
MARS: Radio Map Super-resolution and Reconstruction Method under Sparse Channel Measurements
Jun 06, 2025Radio maps reflect the spatial distribution of signal strength and are essential for applications like smart cities, IoT, and wireless network planning. However, reconstructing accurate radio maps from sparse measurements remains challenging. Traditional interpolation and inpainting methods lack environmental awareness, while many deep learning approaches depend on detailed scene data, limiting generalization. To address this, we propose MARS, a Multi-scale Aware Radiomap Super-resolution method that combines CNNs and Transformers with multi-scale feature fusion and residual connections. MARS focuses on both global and local feature extraction, enhancing feature representation across different receptive fields and improving reconstruction accuracy. Experiments across different scenes and antenna locations show that MARS outperforms baseline models in both MSE and SSIM, while maintaining low computational cost, demonstrating strong practical potential.
Leveraging Contrast Information for Efficient Document Shadow Removal
Apr 01, 2025Document shadows are a major obstacle in the digitization process. Due to the dense information in text and patterns covered by shadows, document shadow removal requires specialized methods. Existing document shadow removal methods, although showing some progress, still rely on additional information such as shadow masks or lack generalization and effectiveness across different shadow scenarios. This often results in incomplete shadow removal or loss of original document content and tones. Moreover, these methods tend to underutilize the information present in the original shadowed document image. In this paper, we refocus our approach on the document images themselves, which inherently contain rich information.We propose an end-to-end document shadow removal method guided by contrast representation, following a coarse-to-fine refinement approach. By extracting document contrast information, we can effectively and quickly locate shadow shapes and positions without the need for additional masks. This information is then integrated into the refined shadow removal process, providing better guidance for network-based removal and feature fusion. Extensive qualitative and quantitative experiments show that our method achieves state-of-the-art performance.
DULRTC-RME: A Deep Unrolled Low-rank Tensor Completion Network for Radio Map Estimation
Feb 07, 2025



Radio maps enrich radio propagation and spectrum occupancy information, which provides fundamental support for the operation and optimization of wireless communication systems. Traditional radio maps are mainly achieved by extensive manual channel measurements, which is time-consuming and inefficient. To reduce the complexity of channel measurements, radio map estimation (RME) through novel artificial intelligence techniques has emerged to attain higher resolution radio maps from sparse measurements or few observations. However, black box problems and strong dependency on training data make learning-based methods less explainable, while model-based methods offer strong theoretical grounding but perform inferior to the learning-based methods. In this paper, we develop a deep unrolled low-rank tensor completion network (DULRTC-RME) for radio map estimation, which integrates theoretical interpretability and learning ability by unrolling the tedious low-rank tensor completion optimization into a deep network. It is the first time that algorithm unrolling technology has been used in the RME field. Experimental results demonstrate that DULRTC-RME outperforms existing RME methods.
Dial-insight: Fine-tuning Large Language Models with High-Quality Domain-Specific Data Preventing Capability Collapse
Mar 14, 2024The efficacy of large language models (LLMs) is heavily dependent on the quality of the underlying data, particularly within specialized domains. A common challenge when fine-tuning LLMs for domain-specific applications is the potential degradation of the model's generalization capabilities. To address these issues, we propose a two-stage approach for the construction of production prompts designed to yield high-quality data. This method involves the generation of a diverse array of prompts that encompass a broad spectrum of tasks and exhibit a rich variety of expressions. Furthermore, we introduce a cost-effective, multi-dimensional quality assessment framework to ensure the integrity of the generated labeling data. Utilizing a dataset comprised of service provider and customer interactions from the real estate sector, we demonstrate a positive correlation between data quality and model performance. Notably, our findings indicate that the domain-specific proficiency of general LLMs can be enhanced through fine-tuning with data produced via our proposed method, without compromising their overall generalization abilities, even when exclusively domain-specific data is employed for fine-tuning.
A Physics-driven GraphSAGE Method for Physical Process Simulations Described by Partial Differential Equations
Mar 13, 2024Physics-informed neural networks (PINNs) have successfully addressed various computational physics problems based on partial differential equations (PDEs). However, while tackling issues related to irregularities like singularities and oscillations, trained solutions usually suffer low accuracy. In addition, most current works only offer the trained solution for predetermined input parameters. If any change occurs in input parameters, transfer learning or retraining is required, and traditional numerical techniques also need an independent simulation. In this work, a physics-driven GraphSAGE approach (PD-GraphSAGE) based on the Galerkin method and piecewise polynomial nodal basis functions is presented to solve computational problems governed by irregular PDEs and to develop parametric PDE surrogate models. This approach employs graph representations of physical domains, thereby reducing the demands for evaluated points due to local refinement. A distance-related edge feature and a feature mapping strategy are devised to help training and convergence for singularity and oscillation situations, respectively. The merits of the proposed method are demonstrated through a couple of cases. Moreover, the robust PDE surrogate model for heat conduction problems parameterized by the Gaussian random field source is successfully established, which not only provides the solution accurately but is several times faster than the finite element method in our experiments.
CasCast: Skillful High-resolution Precipitation Nowcasting via Cascaded Modelling
Feb 06, 2024



Precipitation nowcasting based on radar data plays a crucial role in extreme weather prediction and has broad implications for disaster management. Despite progresses have been made based on deep learning, two key challenges of precipitation nowcasting are not well-solved: (i) the modeling of complex precipitation system evolutions with different scales, and (ii) accurate forecasts for extreme precipitation. In this work, we propose CasCast, a cascaded framework composed of a deterministic and a probabilistic part to decouple the predictions for mesoscale precipitation distributions and small-scale patterns. Then, we explore training the cascaded framework at the high resolution and conducting the probabilistic modeling in a low dimensional latent space with a frame-wise-guided diffusion transformer for enhancing the optimization of extreme events while reducing computational costs. Extensive experiments on three benchmark radar precipitation datasets show that CasCast achieves competitive performance. Especially, CasCast significantly surpasses the baseline (up to +91.8%) for regional extreme-precipitation nowcasting.
From LLM to Conversational Agent: A Memory Enhanced Architecture with Fine-Tuning of Large Language Models
Jan 05, 2024This paper introduces RAISE (Reasoning and Acting through Scratchpad and Examples), an advanced architecture enhancing the integration of Large Language Models (LLMs) like GPT-4 into conversational agents. RAISE, an enhancement of the ReAct framework, incorporates a dual-component memory system, mirroring human short-term and long-term memory, to maintain context and continuity in conversations. It entails a comprehensive agent construction scenario, including phases like Conversation Selection, Scene Extraction, CoT Completion, and Scene Augmentation, leading to the LLMs Training phase. This approach appears to enhance agent controllability and adaptability in complex, multi-turn dialogues. Our preliminary evaluations in a real estate sales context suggest that RAISE has some advantages over traditional agents, indicating its potential for broader applications. This work contributes to the AI field by providing a robust framework for developing more context-aware and versatile conversational agents.
DUMA: a Dual-Mind Conversational Agent with Fast and Slow Thinking
Oct 30, 2023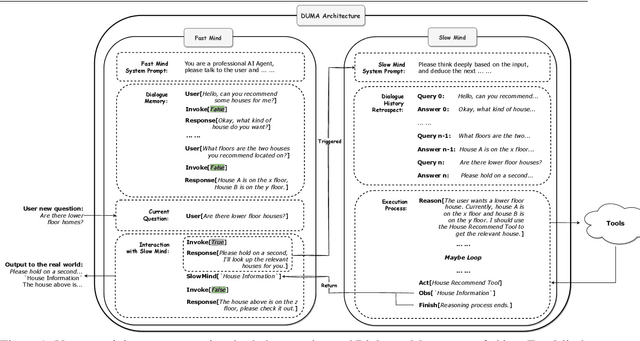
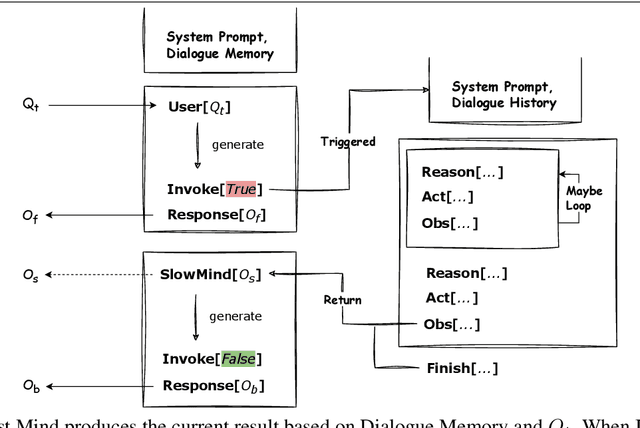

Inspired by the dual-process theory of human cognition, we introduce DUMA, a novel conversational agent framework that embodies a dual-mind mechanism through the utilization of two generative Large Language Models (LLMs) dedicated to fast and slow thinking respectively. The fast thinking model serves as the primary interface for external interactions and initial response generation, evaluating the necessity for engaging the slow thinking model based on the complexity of the complete response. When invoked, the slow thinking model takes over the conversation, engaging in meticulous planning, reasoning, and tool utilization to provide a well-analyzed response. This dual-mind configuration allows for a seamless transition between intuitive responses and deliberate problem-solving processes based on the situation. We have constructed a conversational agent to handle online inquiries in the real estate industry. The experiment proves that our method balances effectiveness and efficiency, and has a significant improvement compared to the baseline.
A Survey on Hyperspectral Image Restoration: From the View of Low-Rank Tensor Approximation
May 18, 2022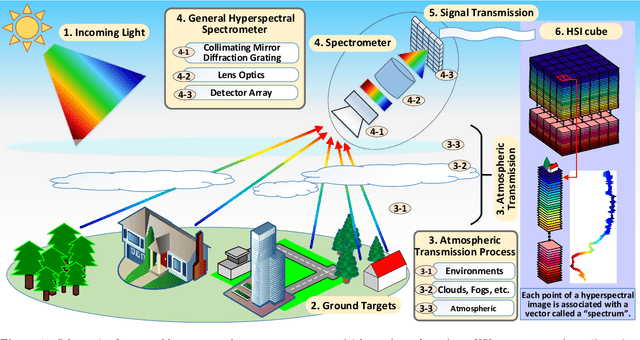
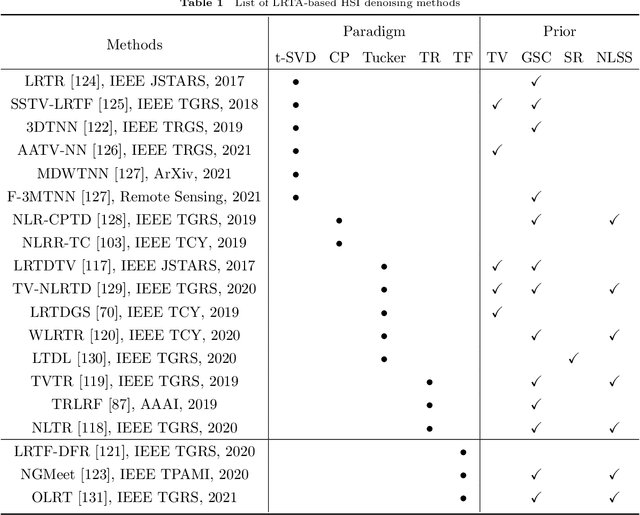
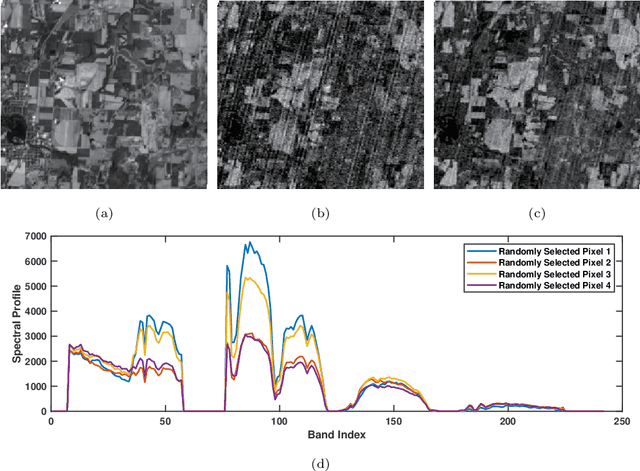
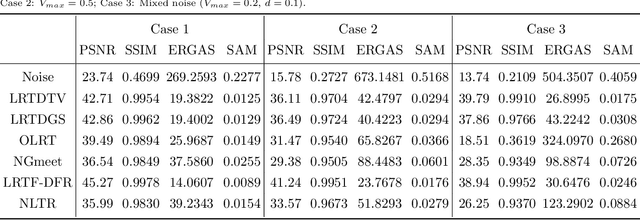
The ability of capturing fine spectral discriminative information enables hyperspectral images (HSIs) to observe, detect and identify objects with subtle spectral discrepancy. However, the captured HSIs may not represent true distribution of ground objects and the received reflectance at imaging instruments may be degraded, owing to environmental disturbances, atmospheric effects and sensors' hardware limitations. These degradations include but are not limited to: complex noise (i.e., Gaussian noise, impulse noise, sparse stripes, and their mixtures), heavy stripes, deadlines, cloud and shadow occlusion, blurring and spatial-resolution degradation and spectral absorption, etc. These degradations dramatically reduce the quality and usefulness of HSIs. Low-rank tensor approximation (LRTA) is such an emerging technique, having gained much attention in HSI restoration community, with ever-growing theoretical foundation and pivotal technological innovation. Compared to low-rank matrix approximation (LRMA), LRTA is capable of characterizing more complex intrinsic structure of high-order data and owns more efficient learning abilities, being established to address convex and non-convex inverse optimization problems induced by HSI restoration. This survey mainly attempts to present a sophisticated, cutting-edge, and comprehensive technical survey of LRTA toward HSI restoration, specifically focusing on the following six topics: Denoising, Destriping, Inpainting, Deblurring, Super--resolution and Fusion. The theoretical development and variants of LRTA techniques are also elaborated. For each topic, the state-of-the-art restoration methods are compared by assessing their performance both quantitatively and visually. Open issues and challenges are also presented, including model formulation, algorithm design, prior exploration and application concerning the interpretation requirements.