 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASTRA: Automated Synthesis of agentic Trajectories and Reinforcement Arenas
Jan 29, 2026Large language models (LLMs) are increasingly used as tool-augmented agents for multi-step decision making, yet training robust tool-using agents remains challenging. Existing methods still require manual intervention, depend on non-verifiable simulated environments, rely exclusively on either supervised fine-tuning (SFT) or reinforcement learning (RL), and struggle with stable long-horizon, multi-turn learning. To address these challenges, we introduce ASTRA, a fully automated end-to-end framework for training tool-augmented language model agents via scalable data synthesis and verifiable reinforcement learning. ASTRA integrates two complementary components. First, a pipeline that leverages the static topology of tool-call graphs synthesizes diverse, structurally grounded trajectories, instilling broad and transferable tool-use competence. Second, an environment synthesis framework that captures the rich, compositional topology of human semantic reasoning converts decomposed question-answer traces into independent, code-executable, and rule-verifiable environments, enabling deterministic multi-turn RL. Based on this method, we develop a unified training methodology that integrates SFT with online RL using trajectory-level rewards to balance task completion and interaction efficiency. Experiments on multiple agentic tool-use benchmarks demonstrate that ASTRA-trained models achieve state-of-the-art performance at comparable scales, approaching closed-source systems while preserving core reasoning ability. We release the full pipelines, environments, and trained models at https://github.com/LianjiaTech/astra.
Weakly supervised alignment and registration of MR-CT for cervical cancer radiotherapy
May 21, 2024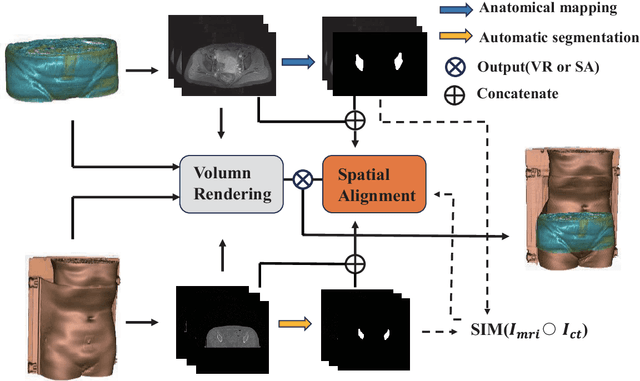
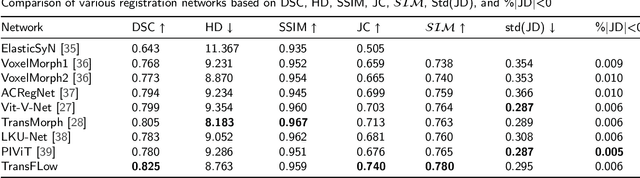
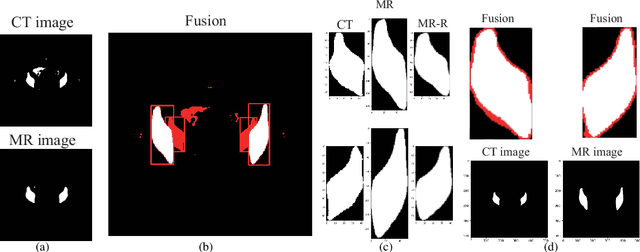
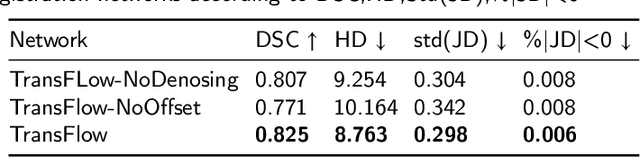
Cervical cancer is one of the leading causes of death in women, and brachytherapy is currently the primary treatment method. However, it is important to precisely define the extent of paracervical tissue invasion to improve cancer diagnosis and treatment options. The fusion of the information characteristics of both computed tomography (CT) and magnetic resonance imaging(MRI) modalities may be useful in achieving a precise outline of the extent of paracervical tissue invasion. Registration is the initial step in information fusion. However, when aligning multimodal images with varying depths, manual alignment is prone to large errors and is time-consuming. Furthermore, the variations in the size of the Region of Interest (ROI) and the shape of multimodal images pose a significant challenge for achieving accurate registration.In this paper, we propose a preliminary spatial alignment algorithm and a weakly supervised multimodal registration network. The spatial position alignment algorithm efficiently utilizes the limited annotation information in the two modal images provided by the doctor to automatically align multimodal images with varying depths. By utilizing aligned multimodal images for weakly supervised registration and incorporating pyramidal features and cost volume to estimate the optical flow, the results indicate that the proposed method outperforms traditional volume rendering alignment methods and registration networks in various evaluation metrics. This demonstrates the effectiveness of our model in multimodal image registration.
Dial-insight: Fine-tuning Large Language Models with High-Quality Domain-Specific Data Preventing Capability Collapse
Mar 14, 2024The efficacy of large language models (LLMs) is heavily dependent on the quality of the underlying data, particularly within specialized domains. A common challenge when fine-tuning LLMs for domain-specific applications is the potential degradation of the model's generalization capabilities. To address these issues, we propose a two-stage approach for the construction of production prompts designed to yield high-quality data. This method involves the generation of a diverse array of prompts that encompass a broad spectrum of tasks and exhibit a rich variety of expressions. Furthermore, we introduce a cost-effective, multi-dimensional quality assessment framework to ensure the integrity of the generated labeling data. Utilizing a dataset comprised of service provider and customer interactions from the real estate sector, we demonstrate a positive correlation between data quality and model performance. Notably, our findings indicate that the domain-specific proficiency of general LLMs can be enhanced through fine-tuning with data produced via our proposed method, without compromising their overall generalization abilities, even when exclusively domain-specific data is employed for fine-tuning.
A real-time rendering method for high albedo anisotropic materials with multiple scattering
Jan 25, 2024We propose a neural network-based real-time volume rendering method for realistic and efficient rendering of volumetric media. The traditional volume rendering method uses path tracing to solve the radiation transfer equation, which requires a huge amount of calculation and cannot achieve real-time rendering. Therefore, this paper uses neural networks to simulate the iterative integration process of solving the radiative transfer equation to speed up the volume rendering of volume media. Specifically, the paper first performs data processing on the volume medium to generate a variety of sampling features, including density features, transmittance features and phase features. The hierarchical transmittance fields are fed into a 3D-CNN network to compute more important transmittance features. Secondly, the diffuse reflection sampling template and the highlight sampling template are used to layer the three types of sampling features into the network. This method can pay more attention to light scattering, highlights and shadows, and then select important channel features through the attention module. Finally, the scattering distribution of the center points of all sampling templates is predicted through the backbone neural network. This method can achieve realistic volumetric media rendering effects and greatly increase the rendering speed while maintaining rendering quality, which is of great significance for real-time rendering applications. Experimental results indicate that our method outperforms previous methods.
Exploration and Improvement of Nerf-based 3D Scene Editing Techniques
Jan 23, 2024NeRF's high-quality scene synthesis capability was quickly accepted by scholars in the years after it was proposed, and significant progress has been made in 3D scene representation and synthesis. However, the high computational cost limits intuitive and efficient editing of scenes, making NeRF's development in the scene editing field facing many challenges. This paper reviews the preliminary explorations of scholars on NeRF in the scene or object editing field in recent years, mainly changing the shape and texture of scenes or objects in new synthesized scenes; through the combination of residual models such as GaN and Transformer with NeRF, the generalization ability of NeRF scene editing has been further expanded, including realizing real-time new perspective editing feedback, multimodal editing of text synthesized 3D scenes, 4D synthesis performance, and in-depth exploration in light and shadow editing, initially achieving optimization of indirect touch editing and detail representation in complex scenes. Currently, most NeRF editing methods focus on the touch points and materials of indirect points, but when dealing with more complex or larger 3D scenes, it is difficult to balance accuracy, breadth, efficiency, and quality. Overcoming these challenges may become the direction of future NeRF 3D scene editing technology.
Methods and strategies for improving the novel view synthesis quality of neural radiation field
Jan 23, 2024Neural Radiation Field (NeRF) technology can learn a 3D implicit model of a scene from 2D images and synthesize realistic novel view images. This technology has received widespread attention from the industry and has good application prospects. In response to the problem that the rendering quality of NeRF images needs to be improved, many researchers have proposed various methods to improve the rendering quality in the past three years. The latest relevant papers are classified and reviewed, the technical principles behind quality improvement are analyzed, and the future evolution direction of quality improvement methods is discussed. This study can help researchers quickly understand the current state and evolutionary context of technology in this field, which is helpful in inspiring the development of more efficient algorithms and promoting the application of NeRF technology in related fields.
From LLM to Conversational Agent: A Memory Enhanced Architecture with Fine-Tuning of Large Language Models
Jan 05, 2024This paper introduces RAISE (Reasoning and Acting through Scratchpad and Examples), an advanced architecture enhancing the integration of Large Language Models (LLMs) like GPT-4 into conversational agents. RAISE, an enhancement of the ReAct framework, incorporates a dual-component memory system, mirroring human short-term and long-term memory, to maintain context and continuity in conversations. It entails a comprehensive agent construction scenario, including phases like Conversation Selection, Scene Extraction, CoT Completion, and Scene Augmentation, leading to the LLMs Training phase. This approach appears to enhance agent controllability and adaptability in complex, multi-turn dialogues. Our preliminary evaluations in a real estate sales context suggest that RAISE has some advantages over traditional agents, indicating its potential for broader applications. This work contributes to the AI field by providing a robust framework for developing more context-aware and versatile conversational agents.
DUMA: a Dual-Mind Conversational Agent with Fast and Slow Thinking
Oct 30, 2023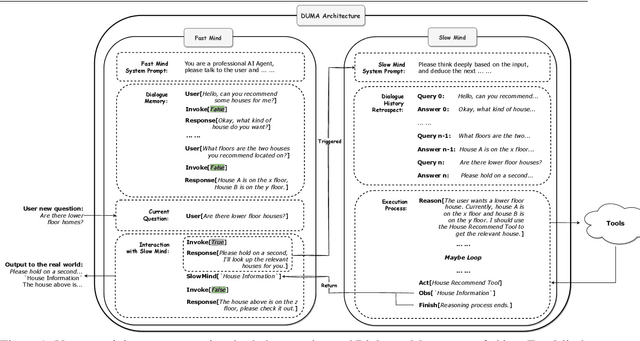
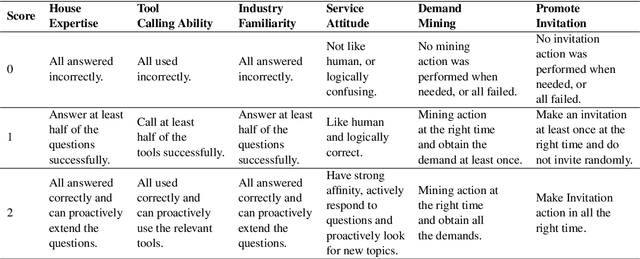
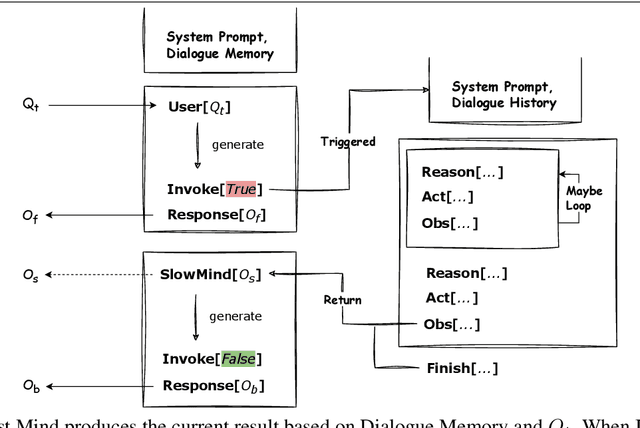

Inspired by the dual-process theory of human cognition, we introduce DUMA, a novel conversational agent framework that embodies a dual-mind mechanism through the utilization of two generative Large Language Models (LLMs) dedicated to fast and slow thinking respectively. The fast thinking model serves as the primary interface for external interactions and initial response generation, evaluating the necessity for engaging the slow thinking model based on the complexity of the complete response. When invoked, the slow thinking model takes over the conversation, engaging in meticulous planning, reasoning, and tool utilization to provide a well-analyzed response. This dual-mind configuration allows for a seamless transition between intuitive responses and deliberate problem-solving processes based on the situation. We have constructed a conversational agent to handle online inquiries in the real estate industry. The experiment proves that our method balances effectiveness and efficiency, and has a significant improvement compared to the baseline.