 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Sharp Phase Transition of Tyler's M-Estimator for Robust Subspace Recovery
Jun 04, 2026Robust Subspace Recovery (RSR) aims to identify an underlying d-dimensional subspace from a dataset heavily corrupted by outliers. Complexity-theoretic results establish a threshold for the problem's computational hardness based on the dimension-scaled signal-to-noise ratio (DS-SNR): the problem is SSE-hard when the DS-SNR is strictly less than 1, and solvable via practical algorithms when it is greater than 1 under general position assumptions. However, the exact behavior of practical algorithms at the critical boundary DS-SNR = 1 has remained unknown. This work resolves the behavior of Tyler's M-estimator (TME) at this critical boundary, consequently establishing a sharp phase transition. Specifically, we prove that TME converges exactly to the true subspace for DS-SNR \geq 1 under a new stability condition, which is less restrictive than the general position assumptions used in prior literature. Our analysis utilizes a decomposition of the TME iterates within a majorization-minimization framework.
Combining Mechanical and Agentic Specification Inference for Move
May 11, 2026In this paper, we describe early work on a specification inference tool for the Move Prover that combines a weakest-precondition (WP) analysis over Move bytecode with an agentic coding CLI such as Claude Code. Specification inference reduces the boilerplate of writing specifications in Move: in order to verify a high-level property such as a global state invariant, pre- and post-conditions for the supporting functions typically have to be written by hand, which is tedious. In our setting, a Model Context Protocol (MCP) service exposes the WP analysis and the prover itself to the coding agent. The WP analysis provides a sound, mechanical baseline for inference; the AI is used precisely where WP is weakest -- for loop invariants and high-level idiomatic specifications such as monotonicity, conservation, and structural invariants. The Move Prover serves as the oracle that decides whether the generated specs are valid, and the agent is equipped to generate proof hints and to refine the inferred specification until verification succeeds. The tool has been applied to a corpus of canonical Move code, including code that uses higher-order functions, dynamic dispatch, global state, references, and various forms of loops.
Dynamic Skill Lifecycle Management for Agentic Reinforcement Learning
May 11, 2026Large language model agents increasingly rely on external skills to solve complex tasks, where skills act as modular units that extend their capabilities beyond what parametric memory alone supports. Existing methods assume external skills either accumulate as persistent guidance or internalized into the policy, eventually leading to zero-skill inference. We argue this assumption is overly restrictive, since with limited parametric capacity and uneven marginal contribution across skills, the optimal active skill set is non-monotonic, task- and stage-dependent. In this work, we propose SLIM, a framework of dynamic Skill LIfecycle Management for agentic reinforcement learning (RL), which treats the active external skill set as a dynamic optimization variable jointly updated with policy learning. Specifically, SLIM estimates each active skill's marginal external contribution through leave-one-skill-out validation, then applies three lifecycle operations: retaining high-value skills, retiring skills whose contribution becomes negligible after sufficient exposure, and expanding the skill bank when persistent failures reveal missing capability coverage. Experiments show that SLIM outperforms the best baselines by an average of 7.1% points across ALFWorld and SearchQA. Results further indicate that policy learning and external skill retention are not mutually exclusive: some skills are absorbed into the policy, while others continue to provide external value, supporting SLIM as a more general paradigm for skill-based agentic RL.
ReflectDrive-2: Reinforcement-Learning-Aligned Self-Editing for Discrete Diffusion Driving
May 06, 2026We introduce ReflectDrive-2, a masked discrete diffusion planner with separate action expert for autonomous driving that represents plans as discrete trajectory tokens and generates them through parallel masked decoding. This discrete token space enables in-place trajectory revision: AutoEdit rewrites selected tokens using the same model, without requiring an auxiliary refinement network. To train this capability, we use a two-stage procedure. First, we construct structure-aware perturbations of expert trajectories along longitudinal progress and lateral heading directions and supervise the model to recover the original expert trajectory. We then fine-tune the full decision--draft--reflect rollout with reinforcement learning (RL), assigning terminal driving reward to the final post-edit trajectory and propagating policy-gradient credit through full-rollout transitions. Full-rollout RL proves crucial for coupling drafting and editing: under supervised training alone, inference-time AutoEdit improves PDMS by at most $0.3$, whereas RL increases its gain to $1.9$. We also co-design an efficient reflective decoding stack for the decision--draft--reflect pipeline, combining shared-prefix KV reuse, Alternating Step Decode, and fused on-device unmasking. On NAVSIM, ReflectDrive-2 achieves $91.0$ PDMS with camera-only input and $94.8$ PDMS in a best-of-6 oracle setting, while running at $31.8$ ms average latency on NVIDIA Thor.
PRISM: Streaming Human Motion Generation with Per-Joint Latent Decomposition
Mar 10, 2026Text-to-motion generation has advanced rapidly, yet two challenges persist. First, existing motion autoencoders compress each frame into a single monolithic latent vector, entangling trajectory and per-joint rotations in an unstructured representation that downstream generators struggle to model faithfully. Second, text-to-motion, pose-conditioned generation, and long-horizon sequential synthesis typically require separate models or task-specific mechanisms, with autoregressive approaches suffering from severe error accumulation over extended rollouts. We present PRISM, addressing each challenge with a dedicated contribution. (1) A joint-factorized motion latent space: each body joint occupies its own token, forming a structured 2D grid (time joints) compressed by a causal VAE with forward-kinematics supervision. This simple change to the latent space -- without modifying the generator -- substantially improves generation quality, revealing that latent space design has been an underestimated bottleneck. (2) Noise-free condition injection: each latent token carries its own timestep embedding, allowing conditioning frames to be injected as clean tokens (timestep0) while the remaining tokens are denoised. This unifies text-to-motion and pose-conditioned generation in a single model, and directly enables autoregressive segment chaining for streaming synthesis. Self-forcing training further suppresses drift in long rollouts. With these two components, we train a single motion generation foundation model that seamlessly handles text-to-motion, pose-conditioned generation, autoregressive sequential generation, and narrative motion composition, achieving state-of-the-art on HumanML3D, MotionHub, BABEL, and a 50-scenario user study.
WorldRFT: Latent World Model Planning with Reinforcement Fine-Tuning for Autonomous Driving
Dec 22, 2025Latent World Models enhance scene representation through temporal self-supervised learning, presenting a perception annotation-free paradigm for end-to-end autonomous driving. However, the reconstruction-oriented representation learning tangles perception with planning tasks, leading to suboptimal optimization for planning. To address this challenge, we propose WorldRFT, a planning-oriented latent world model framework that aligns scene representation learning with planning via a hierarchical planning decomposition and local-aware interactive refinement mechanism, augmented by reinforcement learning fine-tuning (RFT) to enhance safety-critical policy performance. Specifically, WorldRFT integrates a vision-geometry foundation model to improve 3D spatial awareness, employs hierarchical planning task decomposition to guide representation optimization, and utilizes local-aware iterative refinement to derive a planning-oriented driving policy. Furthermore, we introduce Group Relative Policy Optimization (GRPO), which applies trajectory Gaussianization and collision-aware rewards to fine-tune the driving policy, yielding systematic improvements in safety. WorldRFT achieves state-of-the-art (SOTA) performance on both open-loop nuScenes and closed-loop NavSim benchmarks. On nuScenes, it reduces collision rates by 83% (0.30% -> 0.05%). On NavSim, using camera-only sensors input, it attains competitive performance with the LiDAR-based SOTA method DiffusionDrive (87.8 vs. 88.1 PDMS).
Benchmarking neural surrogates on realistic spatiotemporal multiphysics flows
Dec 21, 2025Predicting multiphysics dynamics is computationally expensive and challenging due to the severe coupling of multi-scale, heterogeneous physical processes. While neural surrogates promise a paradigm shift, the field currently suffers from an "illusion of mastery", as repeatedly emphasized in top-tier commentaries: existing evaluations overly rely on simplified, low-dimensional proxies, which fail to expose the models' inherent fragility in realistic regimes. To bridge this critical gap, we present REALM (REalistic AI Learning for Multiphysics), a rigorous benchmarking framework designed to test neural surrogates on challenging, application-driven reactive flows. REALM features 11 high-fidelity datasets spanning from canonical multiphysics problems to complex propulsion and fire safety scenarios, alongside a standardized end-to-end training and evaluation protocol that incorporates multiphysics-aware preprocessing and a robust rollout strategy. Using this framework, we systematically benchmark over a dozen representative surrogate model families, including spectral operators, convolutional models, Transformers, pointwise operators, and graph/mesh networks, and identify three robust trends: (i) a scaling barrier governed jointly by dimensionality, stiffness, and mesh irregularity, leading to rapidly growing rollout errors; (ii) performance primarily controlled by architectural inductive biases rather than parameter count; and (iii) a persistent gap between nominal accuracy metrics and physically trustworthy behavior, where models with high correlations still miss key transient structures and integral quantities. Taken together, REALM exposes the limits of current neural surrogates on realistic multiphysics flows and offers a rigorous testbed to drive the development of next-generation physics-aware architectures.
A Dual-Feature Extractor Framework for Accurate Back Depth and Spine Morphology Estimation from Monocular RGB Images
Jul 30, 2025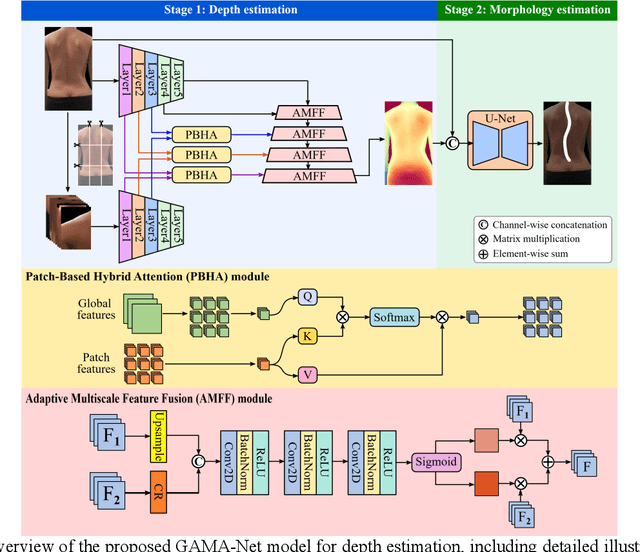

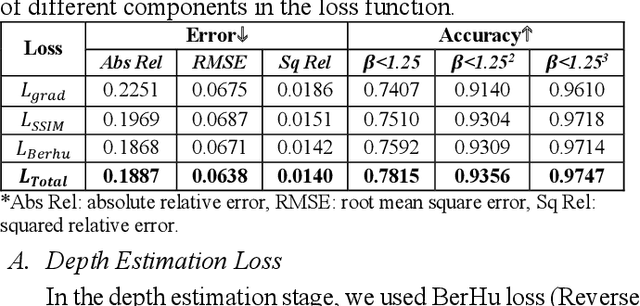
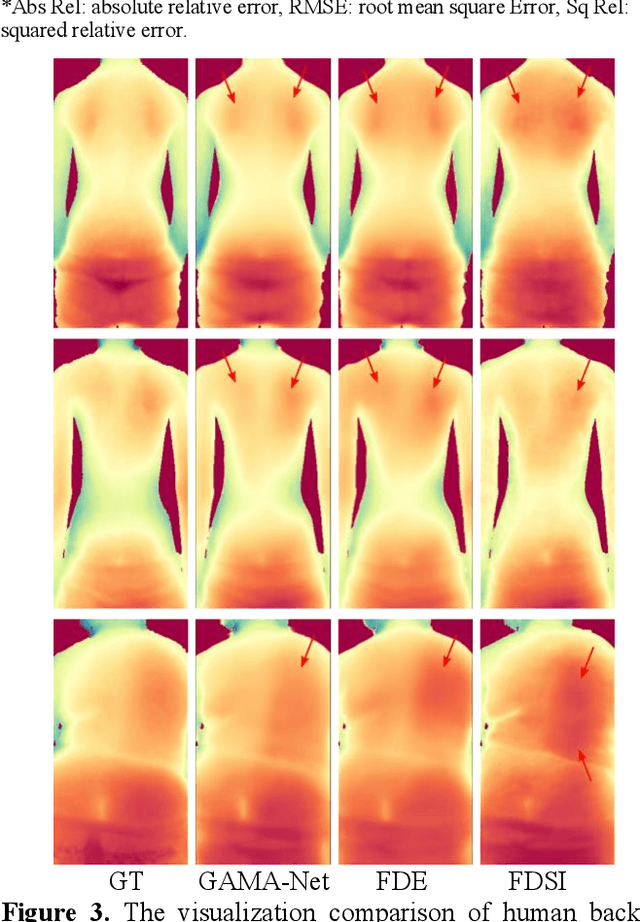
Scoliosis is a prevalent condition that impacts both physical health and appearance, with adolescent idiopathic scoliosis (AIS) being the most common form. Currently, the main AIS assessment tool, X-rays, poses significant limitations, including radiation exposure and limited accessibility in poor and remote areas. To address this problem, the current solutions are using RGB images to analyze spine morphology. However, RGB images are highly susceptible to environmental factors, such as lighting conditions, compromising model stability and generalizability. Therefore, in this study, we propose a novel pipeline to accurately estimate the depth information of the unclothed back, compensating for the limitations of 2D information, and then estimate spine morphology by integrating both depth and surface information. To capture the subtle depth variations of the back surface with precision, we design an adaptive multiscale feature learning network named Grid-Aware Multiscale Adaptive Network (GAMA-Net). This model uses dual encoders to extract both patch-level and global features, which are then interacted by the Patch-Based Hybrid Attention (PBHA) module. The Adaptive Multiscale Feature Fusion (AMFF) module is used to dynamically fuse information in the decoder. As a result, our depth estimation model achieves remarkable accuracy across three different evaluation metrics, with scores of nearly 78.2%, 93.6%, and 97.5%, respectively. To further validate the effectiveness of the predicted depth, we integrate both surface and depth information for spine morphology estimation. This integrated approach enhances the accuracy of spine curve generation, achieving an impressive performance of up to 97%.
NGA: Non-autoregressive Generative Auction with Global Externalities for Advertising Systems
Jun 06, 2025


Online advertising auctions are fundamental to internet commerce, demanding solutions that not only maximize revenue but also ensure incentive compatibility, high-quality user experience, and real-time efficiency. While recent learning-based auction frameworks have improved context modeling by capturing intra-list dependencies among ads, they remain limited in addressing global externalities and often suffer from inefficiencies caused by sequential processing. In this work, we introduce the Non-autoregressive Generative Auction with global externalities (NGA), a novel end-to-end framework designed for industrial online advertising. NGA explicitly models global externalities by jointly capturing the relationships among ads as well as the effects of adjacent organic content. To further enhance efficiency, NGA utilizes a non-autoregressive, constraint-based decoding strategy and a parallel multi-tower evaluator for unified list-wise reward and payment computation. Extensive offline experiments and large-scale online A/B testing on commercial advertising platforms demonstrate that NGA consistently outperforms existing methods in both effectiveness and efficiency.
One Model to Rank Them All: Unifying Online Advertising with End-to-End Learning
May 26, 2025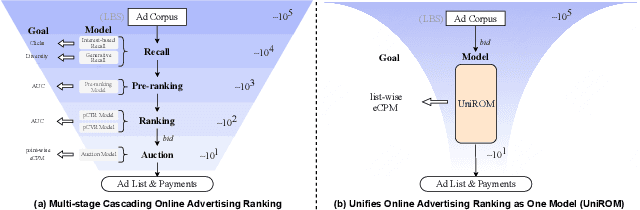
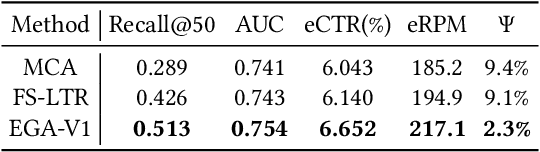
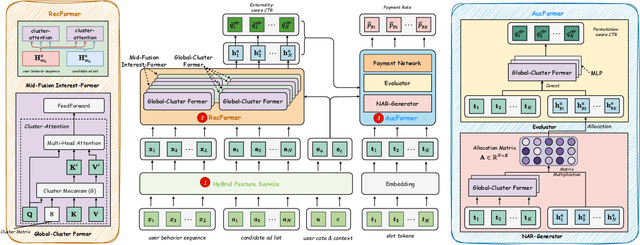
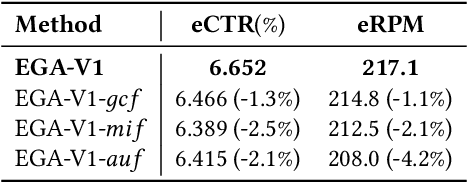
Modern industrial advertising systems commonly employ Multi-stage Cascading Architectures (MCA) to balance computational efficiency with ranking accuracy. However, this approach presents two fundamental challenges: (1) performance inconsistencies arising from divergent optimization targets and capability differences between stages, and (2) failure to account for advertisement externalities - the complex interactions between candidate ads during ranking. These limitations ultimately compromise system effectiveness and reduce platform profitability. In this paper, we present UniROM, an end-to-end generative architecture that Unifies online advertising Ranking as One Model. UniROM replaces cascaded stages with a single model to directly generate optimal ad sequences from the full candidate ad corpus in location-based services (LBS). The primary challenges associated with this approach stem from high costs of feature processing and computational bottlenecks in modeling externalities of large-scale candidate pools. To address these challenges, UniROM introduces an algorithm and engine co-designed hybrid feature service to decouple user and ad feature processing, reducing latency while preserving expressiveness. To efficiently extract intra- and cross-sequence mutual information, we propose RecFormer with an innovative cluster-attention mechanism as its core architectural component. Furthermore, we propose a bi-stage training strategy that integrates pre-training with reinforcement learning-based post-training to meet sophisticated platform and advertising objectives. Extensive offline evaluations on public benchmarks and large-scale online A/B testing on industrial advertising platform have demonstrated the superior performance of UniROM over state-of-the-art MCAs.