 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetis: A Generalizable and Efficient World-Action Model for Autonomous Driving and Urban Navigation
Jun 14, 2026World action models~(WAMs) have shown great promise for autonomous driving and urban navigation. Built upon Vision-Language-Action models or video generation models, existing approaches suffer key limitations: (1) High inference latency due to future observation prediction at test time, and (2) tightly coupled video and action modeling leading to representational mismatch and degraded generalization. To address both issues, we propose Metis, an end-to-end WAM framework that decouples video generation and action prediction. Specifically, Metis employs a Mixture-of-Transformers architecture with dedicated experts for video generation and action prediction, preserving the intrinsic distributional properties of each task. To enhance efficiency, we introduce an asymmetric attention mask that enables joint training of both experts while allowing the action model to bypass explicit video generation during inference. This design ensures training-inference consistency and significantly reduces computational costs without compromising planning performance. Extensive experiments demonstrate state-of-the-art performance on the NAVSIM navhard and navtest benchmarks and the CityWalker navigation benchmark, validating both the generalizability and efficiency across diverse tasks. Real-robot deployments further confirm the practical feasibility of our approach.
ERNIE-Image Technical Report
May 25, 2026We introduce ERNIE-Image, an open-source text-to-image generation model built upon an 8B single-stream DiT architecture. ERNIE-Image aims to bridge the gap between current open-source models and leading closed-source systems through more effective mining of large-scale pre-training data and improved supervision quality throughout training. During pre-training, we adopt a bottom-up data construction pipeline that combines fine-grained image categorization, rich caption annotation, aesthetic assessment, and hierarchical sampling. This strategy reduces data noise while preserving long-tail concepts and detailed real-world knowledge, providing a stronger foundation for complex generation tasks. In the post-training stage, we use a top-down data construction pipeline for high-demand scenarios, diversify prompt annotations to better match real user inputs, and apply a stabilized DPO strategy to align the model with human aesthetic preferences. We further train ERNIE-Image-Turbo for efficient 8-NFE generation and propose MT-DMD to mitigate capability drift during distillation. To make the model easier to use in practical scenarios, we equip it with a lightweight Prompt Enhancer that expands concise user intents into structured visual descriptions. In addition, we develop ERNIE-Image-Aes, an industrial-grade aesthetic model, together with ERNIE-Image-Aes-1K, a human-annotated benchmark for realistic aesthetic evaluation. Extensive qualitative and quantitative experiments show that ERNIE-Image achieves leading performance among open-source models and approaches top-tier commercial models in instruction following, text rendering, and aesthetic quality. We release the trained models and aesthetic resources to facilitate further academic research and technical progress in the AIGC community.
Good to Go: The LOOP Skill Engine That Hits 99% Success and Slashes Token Usage by 99% via One-Shot Recording and Deterministic Replay
May 14, 2026Deploying AI agents for repetitive periodic tasks exposes a critical tension: Large Language Models (LLMs) offer unmatched flexibility in tool orchestration, yet their inherent stochasticity causes unpredictable failures, and repeated invocations incur prohibitive token costs. We present the LOOP SKILL ENGINE, a system that achieves a combined 99% success rate and 99% token reduction for periodic agent tasks through a one-shot recording, deterministic replay paradigm. On its first run, the agent executes the task with full LLM reasoning while the system transparently intercepts and records the complete tool-call trajectory. A greedy length-descending template extraction algorithm then converts this recording into a parameterized, branch-free Loop Skill -- a deterministic execution plan that captures the task's functional intent while parameterizing time-dependent and result-dependent variables. All subsequent executions bypass the LLM entirely: the engine resolves template variables against real-time values and replays the tool sequence deterministically. We prove two theorems: (1) Replay Determinism -- the step sequence of a validated Loop Skill is invariant across all future executions; (2) Write Safety -- concurrent access to persistent configuration is serialized through reentrant locks and atomic file replacement. Across a benchmark of periodic agent tasks spanning intervals from 5 minutes to 24 hours, the Loop Skill Engine reduces monthly token consumption by 93.3%--99.98% and cuts execution latency by 8.7x while eliminating output non-determinism. A multi-layer degradation strategy guarantees that tasks never stall. We release the engine as part of the buddyMe open-source agent framework.
Artificial Intelligence-Assistant Cardiotocography: Unified Model for Signal Reconstruction, Fetal Heart Rate Analysis, and Variability Assessment
May 14, 2026The monitoring of fetal heart rate (FHR) and the assessment of its variability are crucial for preventing fetal compromise and adverse outcomes. However, traditional methods encounter limitations arising from equipment performance, data transmission, and subjective assessments by doctors. We have developed a tailored AI-based FHrCTG model specifically for FHR monitoring, which effectively mitigates noise interference and precisely reconstructs signals. Our model was pre-trained on a massive dataset consisting of 558,412 unlabeled data points and further refined using 7,266 expert-reviewed entries. To validate FHR, we introduced the Intersection Overlapping Labels (IOL) approach, which transforms rate analysis into categorical judgments. Testing revealed that our model demonstrates high sensitivity and specificity in detecting critical FHR decelerations (89.13% and 87.78%, respectively) and accelerations (62.5% and 92.04%, respectively). Furthermore, based on Fischer's criteria for clinical application, our model achieved impressive AUC scores of 0.7214 and 0.9643 for verifying FHR periodicity and amplitude variation, respectively.
Neural ODE and SDE Models for Adaptation and Planning in Model-Based Reinforcement Learning
Mar 24, 2026We investigate neural ordinary and stochastic differential equations (neural ODEs and SDEs) to model stochastic dynamics in fully and partially observed environments within a model-based reinforcement learning (RL) framework. Through a sequence of simulations, we show that neural SDEs more effectively capture the inherent stochasticity of transition dynamics, enabling high-performing policies with improved sample efficiency in challenging scenarios. We leverage neural ODEs and SDEs for efficient policy adaptation to changes in environment dynamics via inverse models, requiring only limited interactions with the new environment. To address partial observability, we introduce a latent SDE model that combines an ODE with a GAN-trained stochastic component in latent space. Policies derived from this model provide a strong baseline, outperforming or matching general model-based and model-free approaches across stochastic continuous-control benchmarks. This work demonstrates the applicability of action-conditional latent SDEs for RL planning in environments with stochastic transitions. Our code is available at: https://github.com/ChaoHan-UoS/NeuralRL
Optimizing Neural Network Architecture for Medical Image Segmentation Using Monte Carlo Tree Search
Feb 25, 2026This paper proposes a novel medical image segmentation framework, MNAS-Unet, which combines Monte Carlo Tree Search (MCTS) and Neural Architecture Search (NAS). MNAS-Unet dynamically explores promising network architectures through MCTS, significantly enhancing the efficiency and accuracy of architecture search. It also optimizes the DownSC and UpSC unit structures, enabling fast and precise model adjustments. Experimental results demonstrate that MNAS-Unet outperforms NAS-Unet and other state-of-the-art models in segmentation accuracy on several medical image datasets, including PROMISE12, Ultrasound Nerve, and CHAOS. Furthermore, compared with NAS-Unet, MNAS-Unet reduces the architecture search budget by 54% (early stopping at 139 epochs versus 300 epochs under the same search setting), while achieving a lightweight model with only 0.6M parameters and lower GPU memory consumption, which further improves its practical applicability. These results suggest that MNAS-Unet can improve search efficiency while maintaining competitive segmentation accuracy under practical resource constraints.
WorldRFT: Latent World Model Planning with Reinforcement Fine-Tuning for Autonomous Driving
Dec 22, 2025Latent World Models enhance scene representation through temporal self-supervised learning, presenting a perception annotation-free paradigm for end-to-end autonomous driving. However, the reconstruction-oriented representation learning tangles perception with planning tasks, leading to suboptimal optimization for planning. To address this challenge, we propose WorldRFT, a planning-oriented latent world model framework that aligns scene representation learning with planning via a hierarchical planning decomposition and local-aware interactive refinement mechanism, augmented by reinforcement learning fine-tuning (RFT) to enhance safety-critical policy performance. Specifically, WorldRFT integrates a vision-geometry foundation model to improve 3D spatial awareness, employs hierarchical planning task decomposition to guide representation optimization, and utilizes local-aware iterative refinement to derive a planning-oriented driving policy. Furthermore, we introduce Group Relative Policy Optimization (GRPO), which applies trajectory Gaussianization and collision-aware rewards to fine-tune the driving policy, yielding systematic improvements in safety. WorldRFT achieves state-of-the-art (SOTA) performance on both open-loop nuScenes and closed-loop NavSim benchmarks. On nuScenes, it reduces collision rates by 83% (0.30% -> 0.05%). On NavSim, using camera-only sensors input, it attains competitive performance with the LiDAR-based SOTA method DiffusionDrive (87.8 vs. 88.1 PDMS).
Preliminary Investigation into Data Scaling Laws for Imitation Learning-Based End-to-End Autonomous Driving
Dec 03, 2024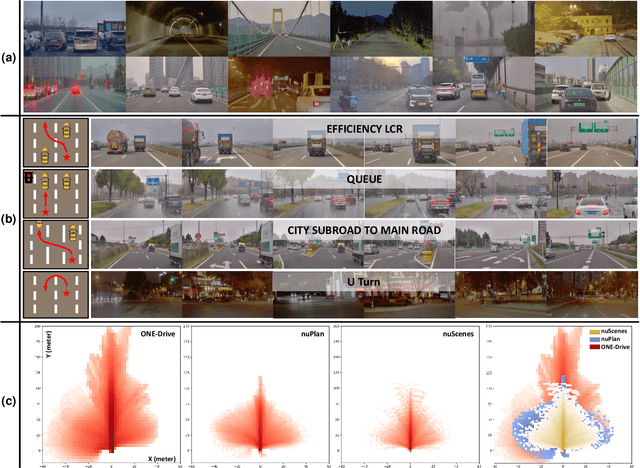
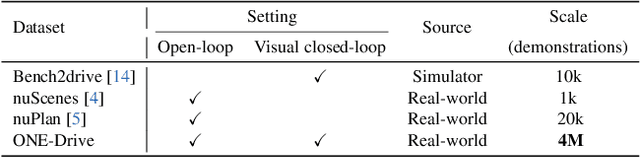

The end-to-end autonomous driving paradigm has recently attracted lots of attention due to its scalability. However, existing methods are constrained by the limited scale of real-world data, which hinders a comprehensive exploration of the scaling laws associated with end-to-end autonomous driving. To address this issue, we collected substantial data from various driving scenarios and behaviors and conducted an extensive study on the scaling laws of existing imitation learning-based end-to-end autonomous driving paradigms. Specifically, approximately 4 million demonstrations from 23 different scenario types were gathered, amounting to over 30,000 hours of driving demonstrations. We performed open-loop evaluations and closed-loop simulation evaluations in 1,400 diverse driving demonstrations (1,300 for open-loop and 100 for closed-loop) under stringent assessment conditions. Through experimental analysis, we discovered that (1) the performance of the driving model exhibits a power-law relationship with the amount of training data; (2) a small increase in the quantity of long-tailed data can significantly improve the performance for the corresponding scenarios; (3) appropriate scaling of data enables the model to achieve combinatorial generalization in novel scenes and actions. Our results highlight the critical role of data scaling in improving the generalizability of models across diverse autonomous driving scenarios, assuring safe deployment in the real world. Project repository: https://github.com/ucaszyp/Driving-Scaling-Law
Dynamical-VAE-based Hindsight to Learn the Causal Dynamics of Factored-POMDPs
Nov 12, 2024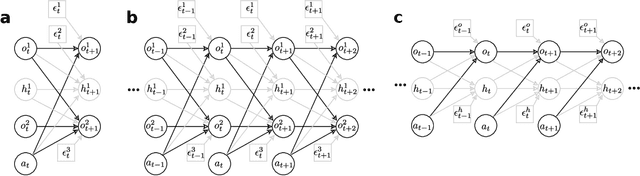
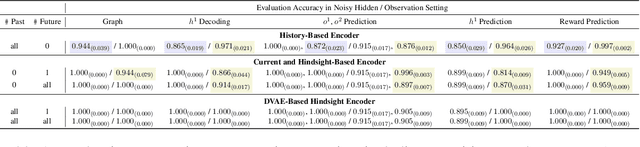
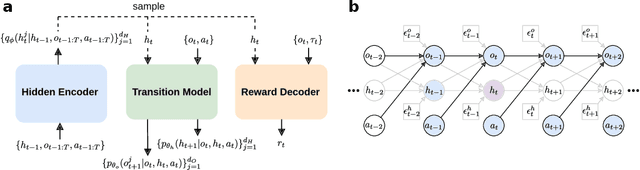
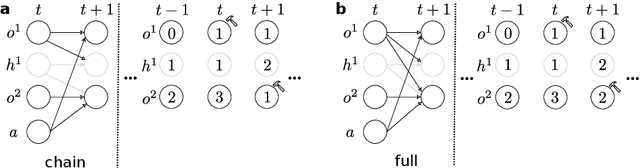
Learning representations of underlying environmental dynamics from partial observations is a critical challenge in machine learning. In the context of Partially Observable Markov Decision Processes (POMDPs), state representations are often inferred from the history of past observations and actions. We demonstrate that incorporating future information is essential to accurately capture causal dynamics and enhance state representations. To address this, we introduce a Dynamical Variational Auto-Encoder (DVAE) designed to learn causal Markovian dynamics from offline trajectories in a POMDP. Our method employs an extended hindsight framework that integrates past, current, and multi-step future information within a factored-POMDP setting. Empirical results reveal that this approach uncovers the causal graph governing hidden state transitions more effectively than history-based and typical hindsight-based models.
Large region targets observation scheduling by multiple satellites using resampling particle swarm optimization
Jun 21, 2022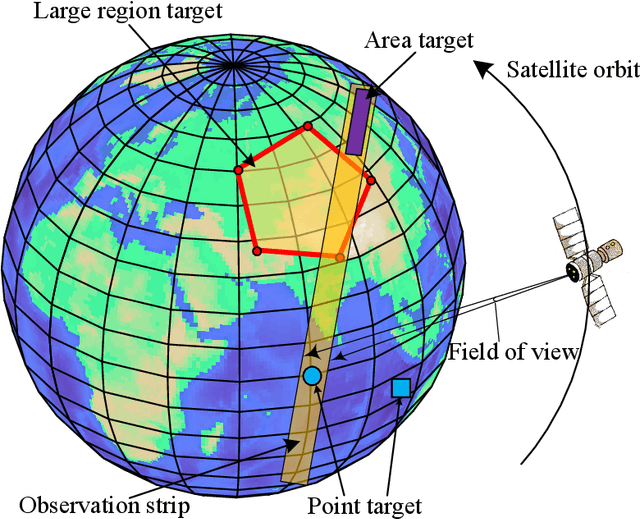
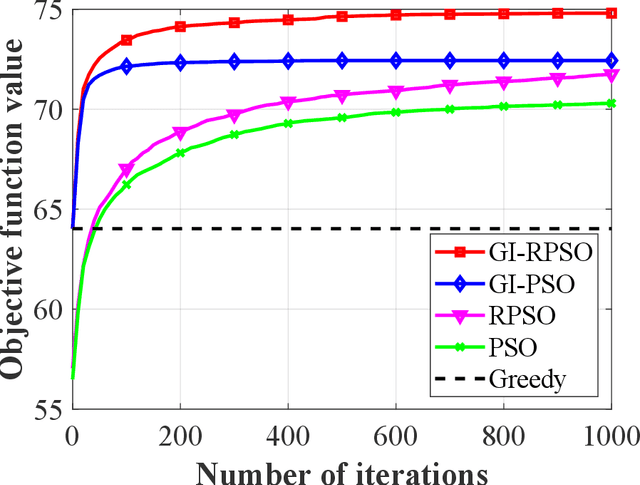
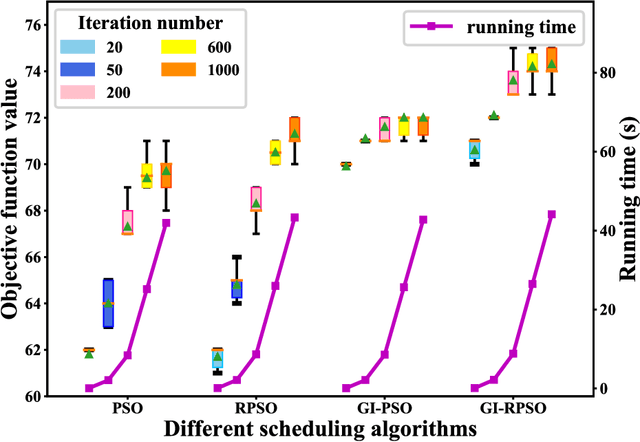
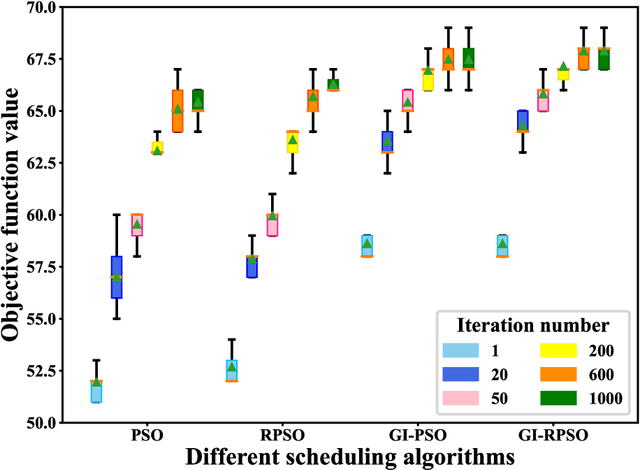
The last decades have witnessed a rapid increase of Earth observation satellites (EOSs), leading to the increasing complexity of EOSs scheduling. On account of the widespread applications of large region observation, this paper aims to address the EOSs observation scheduling problem for large region targets. A rapid coverage calculation method employing a projection reference plane and a polygon clipping technique is first developed. We then formulate a nonlinear integer programming model for the scheduling problem, where the objective function is calculated based on the developed coverage calculation method. A greedy initialization-based resampling particle swarm optimization (GI-RPSO) algorithm is proposed to solve the model. The adopted greedy initialization strategy and particle resampling method contribute to generating efficient and effective solutions during the evolution process. In the end, extensive experiments are conducted to illustrate the effectiveness and reliability of the proposed method. Compared to the traditional particle swarm optimization and the widely used greedy algorithm, the proposed GI-RPSO can improve the scheduling result by 5.42% and 15.86%, respectively.