 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvent Stream based Sign Language Translation: A High-Definition Benchmark Dataset and A New Algorithm
Aug 20, 2024



Sign Language Translation (SLT) is a core task in the field of AI-assisted disability. Unlike traditional SLT based on visible light videos, which is easily affected by factors such as lighting, rapid hand movements, and privacy breaches, this paper proposes the use of high-definition Event streams for SLT, effectively mitigating the aforementioned issues. This is primarily because Event streams have a high dynamic range and dense temporal signals, which can withstand low illumination and motion blur well. Additionally, due to their sparsity in space, they effectively protect the privacy of the target person. More specifically, we propose a new high-resolution Event stream sign language dataset, termed Event-CSL, which effectively fills the data gap in this area of research. It contains 14,827 videos, 14,821 glosses, and 2,544 Chinese words in the text vocabulary. These samples are collected in a variety of indoor and outdoor scenes, encompassing multiple angles, light intensities, and camera movements. We have benchmarked existing mainstream SLT works to enable fair comparison for future efforts. Based on this dataset and several other large-scale datasets, we propose a novel baseline method that fully leverages the Mamba model's ability to integrate temporal information of CNN features, resulting in improved sign language translation outcomes. Both the benchmark dataset and source code will be released on https://github.com/Event-AHU/OpenESL
Benchmarking Large Language Models for Math Reasoning Tasks
Aug 20, 2024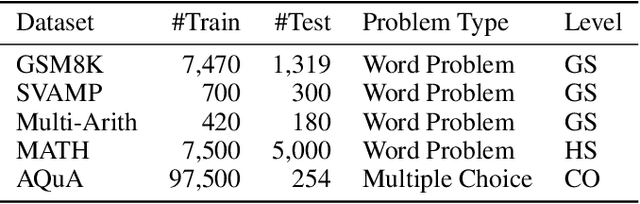
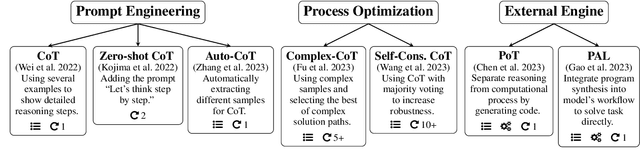

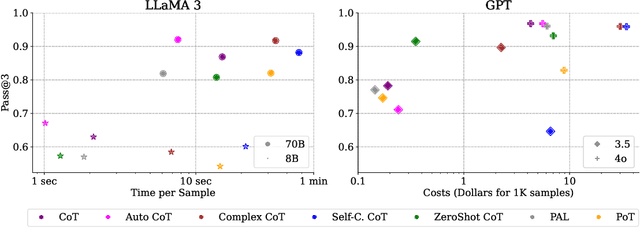
The use of Large Language Models (LLMs) in mathematical reasoning has become a cornerstone of related research, demonstrating the intelligence of these models and enabling potential practical applications through their advanced performance, such as in educational settings. Despite the variety of datasets and in-context learning algorithms designed to improve the ability of LLMs to automate mathematical problem solving, the lack of comprehensive benchmarking across different datasets makes it complicated to select an appropriate model for specific tasks. In this project, we present a benchmark that fairly compares seven state-of-the-art in-context learning algorithms for mathematical problem solving across five widely used mathematical datasets on four powerful foundation models. Furthermore, we explore the trade-off between efficiency and performance, highlighting the practical applications of LLMs for mathematical reasoning. Our results indicate that larger foundation models like GPT-4o and LLaMA 3-70B can solve mathematical reasoning independently from the concrete prompting strategy, while for smaller models the in-context learning approach significantly influences the performance. Moreover, the optimal prompt depends on the chosen foundation model. We open-source our benchmark code to support the integration of additional models in future research.
P-TA: Using Proximal Policy Optimization to Enhance Tabular Data Augmentation via Large Language Models
Jun 17, 2024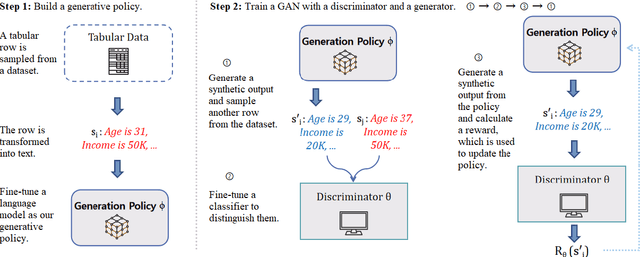



A multitude of industries depend on accurate and reasonable tabular data augmentation for their business processes. Contemporary methodologies in generating tabular data revolve around utilizing Generative Adversarial Networks (GAN) or fine-tuning Large Language Models (LLM). However, GAN-based approaches are documented to produce samples with common-sense errors attributed to the absence of external knowledge. On the other hand, LLM-based methods exhibit a limited capacity to capture the disparities between synthesized and actual data distribution due to the absence of feedback from a discriminator during training. Furthermore, the decoding of LLM-based generation introduces gradient breakpoints, impeding the backpropagation of loss from a discriminator, thereby complicating the integration of these two approaches. To solve this challenge, we propose using proximal policy optimization (PPO) to apply GANs, guiding LLMs to enhance the probability distribution of tabular features. This approach enables the utilization of LLMs as generators for GANs in synthesizing tabular data. Our experiments demonstrate that PPO leads to an approximately 4\% improvement in the accuracy of models trained on synthetically generated data over state-of-the-art across three real-world datasets.
Faithful Attention Explainer: Verbalizing Decisions Based on Discriminative Features
May 16, 2024In recent years, model explanation methods have been designed to interpret model decisions faithfully and intuitively so that users can easily understand them. In this paper, we propose a framework, Faithful Attention Explainer (FAE), capable of generating faithful textual explanations regarding the attended-to features. Towards this goal, we deploy an attention module that takes the visual feature maps from the classifier for sentence generation. Furthermore, our method successfully learns the association between features and words, which allows a novel attention enforcement module for attention explanation. Our model achieves promising performance in caption quality metrics and a faithful decision-relevance metric on two datasets (CUB and ACT-X). In addition, we show that FAE can interpret gaze-based human attention, as human gaze indicates the discriminative features that humans use for decision-making, demonstrating the potential of deploying human gaze for advanced human-AI interaction.
Pre-training on High Definition X-ray Images: An Experimental Study
Apr 27, 2024



Existing X-ray based pre-trained vision models are usually conducted on a relatively small-scale dataset (less than 500k samples) with limited resolution (e.g., 224 $\times$ 224). However, the key to the success of self-supervised pre-training large models lies in massive training data, and maintaining high resolution in the field of X-ray images is the guarantee of effective solutions to difficult miscellaneous diseases. In this paper, we address these issues by proposing the first high-definition (1280 $\times$ 1280) X-ray based pre-trained foundation vision model on our newly collected large-scale dataset which contains more than 1 million X-ray images. Our model follows the masked auto-encoder framework which takes the tokens after mask processing (with a high rate) is used as input, and the masked image patches are reconstructed by the Transformer encoder-decoder network. More importantly, we introduce a novel context-aware masking strategy that utilizes the chest contour as a boundary for adaptive masking operations. We validate the effectiveness of our model on two downstream tasks, including X-ray report generation and disease recognition. Extensive experiments demonstrate that our pre-trained medical foundation vision model achieves comparable or even new state-of-the-art performance on downstream benchmark datasets. The source code and pre-trained models of this paper will be released on https://github.com/Event-AHU/Medical_Image_Analysis.
State Space Model for New-Generation Network Alternative to Transformers: A Survey
Apr 15, 2024In the post-deep learning era, the Transformer architecture has demonstrated its powerful performance across pre-trained big models and various downstream tasks. However, the enormous computational demands of this architecture have deterred many researchers. To further reduce the complexity of attention models, numerous efforts have been made to design more efficient methods. Among them, the State Space Model (SSM), as a possible replacement for the self-attention based Transformer model, has drawn more and more attention in recent years. In this paper, we give the first comprehensive review of these works and also provide experimental comparisons and analysis to better demonstrate the features and advantages of SSM. Specifically, we first give a detailed description of principles to help the readers quickly capture the key ideas of SSM. After that, we dive into the reviews of existing SSMs and their various applications, including natural language processing, computer vision, graph, multi-modal and multi-media, point cloud/event stream, time series data, and other domains. In addition, we give statistical comparisons and analysis of these models and hope it helps the readers to understand the effectiveness of different structures on various tasks. Then, we propose possible research points in this direction to better promote the development of the theoretical model and application of SSM. More related works will be continuously updated on the following GitHub: https://github.com/Event-AHU/Mamba_State_Space_Model_Paper_List.
A Transformer-Based Model for the Prediction of Human Gaze Behavior on Videos
Apr 10, 2024



Eye-tracking applications that utilize the human gaze in video understanding tasks have become increasingly important. To effectively automate the process of video analysis based on eye-tracking data, it is important to accurately replicate human gaze behavior. However, this task presents significant challenges due to the inherent complexity and ambiguity of human gaze patterns. In this work, we introduce a novel method for simulating human gaze behavior. Our approach uses a transformer-based reinforcement learning algorithm to train an agent that acts as a human observer, with the primary role of watching videos and simulating human gaze behavior. We employed an eye-tracking dataset gathered from videos generated by the VirtualHome simulator, with a primary focus on activity recognition. Our experimental results demonstrate the effectiveness of our gaze prediction method by highlighting its capability to replicate human gaze behavior and its applicability for downstream tasks where real human-gaze is used as input.
Gaze-Guided Graph Neural Network for Action Anticipation Conditioned on Intention
Apr 10, 2024Humans utilize their gaze to concentrate on essential information while perceiving and interpreting intentions in videos. Incorporating human gaze into computational algorithms can significantly enhance model performance in video understanding tasks. In this work, we address a challenging and innovative task in video understanding: predicting the actions of an agent in a video based on a partial video. We introduce the Gaze-guided Action Anticipation algorithm, which establishes a visual-semantic graph from the video input. Our method utilizes a Graph Neural Network to recognize the agent's intention and predict the action sequence to fulfill this intention. To assess the efficiency of our approach, we collect a dataset containing household activities generated in the VirtualHome environment, accompanied by human gaze data of viewing videos. Our method outperforms state-of-the-art techniques, achieving a 7\% improvement in accuracy for 18-class intention recognition. This highlights the efficiency of our method in learning important features from human gaze data.
Stepwise Self-Consistent Mathematical Reasoning with Large Language Models
Feb 24, 2024Using Large Language Models for complex mathematical reasoning is difficult, primarily due to the complexity of multi-step reasoning. The main challenges of this process include (1) selecting critical intermediate results to advance the procedure, and (2) limited exploration of potential solutions. To address these issues, we introduce a novel algorithm, namely Stepwise Self-Consistent Chain-of-Thought (SSC-CoT). SSC-CoT employs a strategy of selecting intermediate steps based on the intersection of various reasoning chains. Additionally, SSC-CoT enables the model to discover critical intermediate steps by querying a knowledge graph comprising relevant domain knowledge. To validate SSC-CoT, we present a new dataset, TriMaster100, tailored for complex trigonometry problems. This dataset contains 100 questions, with each solution broken down into scored intermediate steps, facilitating a comprehensive evaluation of the mathematical reasoning process. On TriMaster100, SSC-CoT triples the effectiveness of the state-of-the-art methods. Furthermore, we benchmark SSC-CoT on the widely recognized complex mathematical question dataset, MATH level 5, and it surpasses the second-best method by 7.2% in accuracy. Code and the TriMaster100 dataset can be found at: https://github.com/zhao-zilong/ssc-cot.
I-CEE: Tailoring Explanations of Image Classifications Models to User Expertise
Dec 19, 2023



Effectively explaining decisions of black-box machine learning models is critical to responsible deployment of AI systems that rely on them. Recognizing their importance, the field of explainable AI (XAI) provides several techniques to generate these explanations. Yet, there is relatively little emphasis on the user (the explainee) in this growing body of work and most XAI techniques generate "one-size-fits-all" explanations. To bridge this gap and achieve a step closer towards human-centered XAI, we present I-CEE, a framework that provides Image Classification Explanations tailored to User Expertise. Informed by existing work, I-CEE explains the decisions of image classification models by providing the user with an informative subset of training data (i.e., example images), corresponding local explanations, and model decisions. However, unlike prior work, I-CEE models the informativeness of the example images to depend on user expertise, resulting in different examples for different users. We posit that by tailoring the example set to user expertise, I-CEE can better facilitate users' understanding and simulatability of the model. To evaluate our approach, we conduct detailed experiments in both simulation and with human participants (N = 100) on multiple datasets. Experiments with simulated users show that I-CEE improves users' ability to accurately predict the model's decisions (simulatability) compared to baselines, providing promising preliminary results. Experiments with human participants demonstrate that our method significantly improves user simulatability accuracy, highlighting the importance of human-centered XAI