 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Transformer-Based Model for the Prediction of Human Gaze Behavior on Videos
Apr 10, 2024



Eye-tracking applications that utilize the human gaze in video understanding tasks have become increasingly important. To effectively automate the process of video analysis based on eye-tracking data, it is important to accurately replicate human gaze behavior. However, this task presents significant challenges due to the inherent complexity and ambiguity of human gaze patterns. In this work, we introduce a novel method for simulating human gaze behavior. Our approach uses a transformer-based reinforcement learning algorithm to train an agent that acts as a human observer, with the primary role of watching videos and simulating human gaze behavior. We employed an eye-tracking dataset gathered from videos generated by the VirtualHome simulator, with a primary focus on activity recognition. Our experimental results demonstrate the effectiveness of our gaze prediction method by highlighting its capability to replicate human gaze behavior and its applicability for downstream tasks where real human-gaze is used as input.
Gaze-Guided Graph Neural Network for Action Anticipation Conditioned on Intention
Apr 10, 2024Humans utilize their gaze to concentrate on essential information while perceiving and interpreting intentions in videos. Incorporating human gaze into computational algorithms can significantly enhance model performance in video understanding tasks. In this work, we address a challenging and innovative task in video understanding: predicting the actions of an agent in a video based on a partial video. We introduce the Gaze-guided Action Anticipation algorithm, which establishes a visual-semantic graph from the video input. Our method utilizes a Graph Neural Network to recognize the agent's intention and predict the action sequence to fulfill this intention. To assess the efficiency of our approach, we collect a dataset containing household activities generated in the VirtualHome environment, accompanied by human gaze data of viewing videos. Our method outperforms state-of-the-art techniques, achieving a 7\% improvement in accuracy for 18-class intention recognition. This highlights the efficiency of our method in learning important features from human gaze data.
SyNet: An Ensemble Network for Object Detection in UAV Images
Dec 23, 2020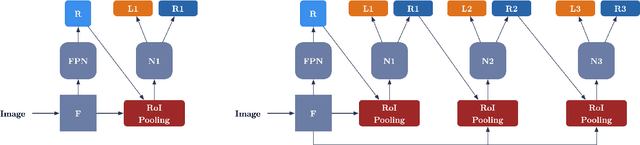
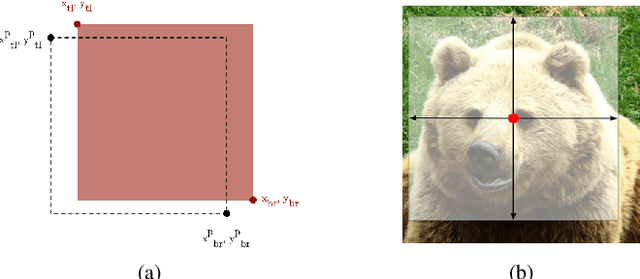
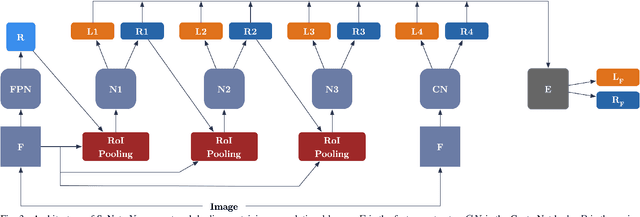

Recent advances in camera equipped drone applications and their widespread use increased the demand on vision based object detection algorithms for aerial images. Object detection process is inherently a challenging task as a generic computer vision problem, however, since the use of object detection algorithms on UAVs (or on drones) is relatively a new area, it remains as a more challenging problem to detect objects in aerial images. There are several reasons for that including: (i) the lack of large drone datasets including large object variance, (ii) the large orientation and scale variance in drone images when compared to the ground images, and (iii) the difference in texture and shape features between the ground and the aerial images. Deep learning based object detection algorithms can be classified under two main categories: (a) single-stage detectors and (b) multi-stage detectors. Both single-stage and multi-stage solutions have their advantages and disadvantages over each other. However, a technique to combine the good sides of each of those solutions could yield even a stronger solution than each of those solutions individually. In this paper, we propose an ensemble network, SyNet, that combines a multi-stage method with a single-stage one with the motivation of decreasing the high false negative rate of multi-stage detectors and increasing the quality of the single-stage detector proposals. As building blocks, CenterNet and Cascade R-CNN with pretrained feature extractors are utilized along with an ensembling strategy. We report the state of the art results obtained by our proposed solution on two different datasets: namely MS-COCO and visDrone with \%52.1 $mAP_{IoU = 0.75}$ is obtained on MS-COCO $val2017$ dataset and \%26.2 $mAP_{IoU = 0.75}$ is obtained on VisDrone $test-set$.
Driver Modeling through Deep Reinforcement Learning and Behavioral Game Theory
Mar 24, 2020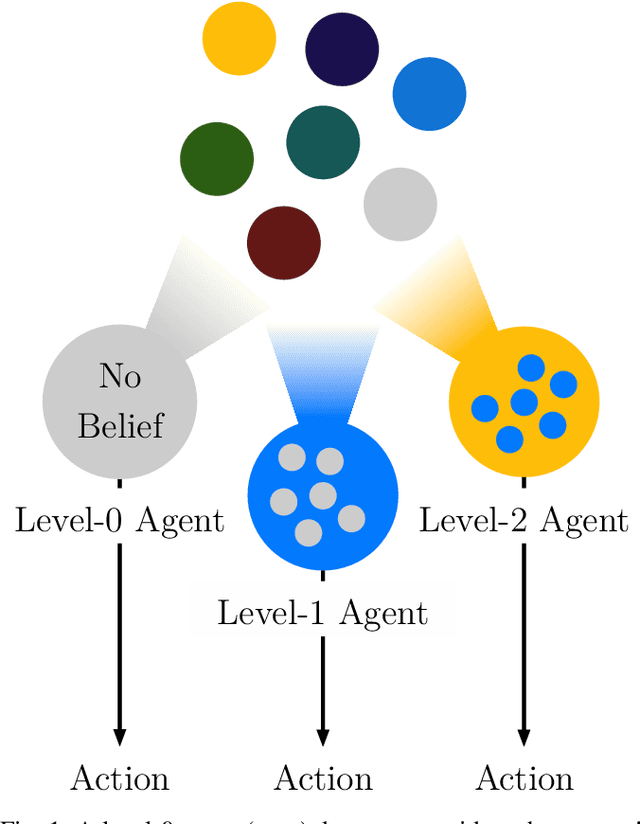
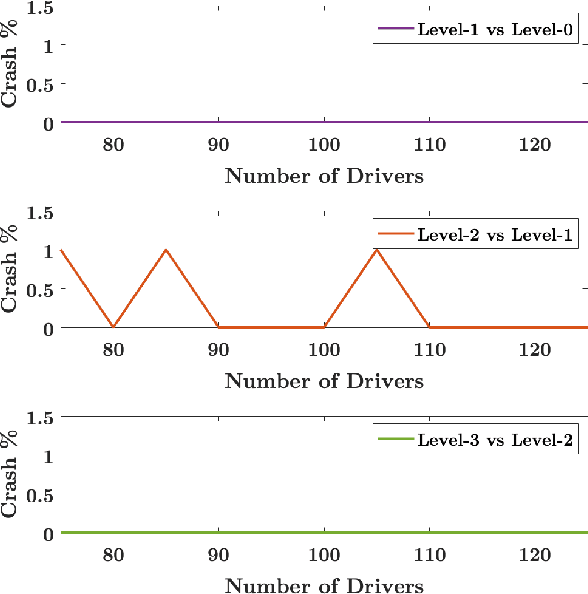

In this paper, a synergistic combination of deep reinforcement learning and hierarchical game theory is proposed as a modeling framework for behavioral predictions of drivers in highway driving scenarios. The need for a modeling framework that can address multiple human-human and human-automation interactions, where all the agents can be modeled as decision makers simultaneously, is the main motivation behind this work. Such a modeling framework may be utilized for the validation and verification of autonomous vehicles: It is estimated that for an autonomous vehicle to reach the same safety level of cars with drivers, millions of miles of driving tests are required. The modeling framework presented in this paper may be used in a high-fidelity traffic simulator consisting of multiple human decision makers to reduce the time and effort spent for testing by allowing safe and quick assessment of self-driving algorithms. To demonstrate the fidelity of the proposed modeling framework, game theoretical driver models are compared with real human driver behavior patterns extracted from traffic data.