 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the Explain-Any-Concept by Introducing Nonlinearity to the Trainable Surrogate Model
May 20, 2024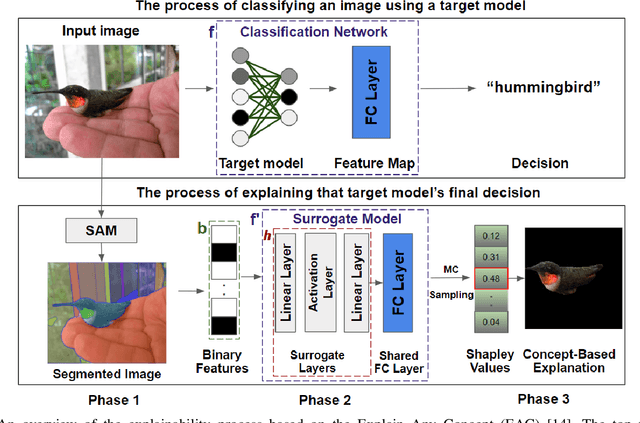
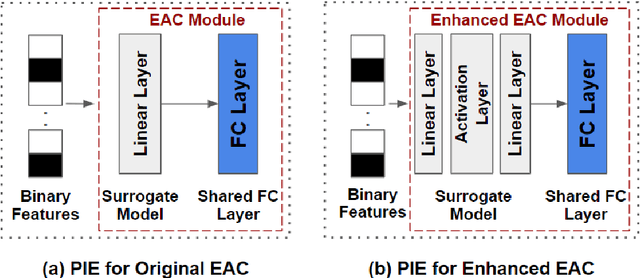

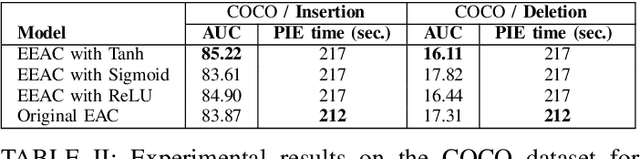
In the evolving field of Explainable AI (XAI), interpreting the decisions of deep neural networks (DNNs) in computer vision tasks is an important process. While pixel-based XAI methods focus on identifying significant pixels, existing concept-based XAI methods use pre-defined or human-annotated concepts. The recently proposed Segment Anything Model (SAM) achieved a significant step forward to prepare automatic concept sets via comprehensive instance segmentation. Building upon this, the Explain Any Concept (EAC) model emerged as a flexible method for explaining DNN decisions. EAC model is based on using a surrogate model which has one trainable linear layer to simulate the target model. In this paper, by introducing an additional nonlinear layer to the original surrogate model, we show that we can improve the performance of the EAC model. We compare our proposed approach to the original EAC model and report improvements obtained on both ImageNet and MS COCO datasets.
VisIRNet: Deep Image Alignment for UAV-taken Visible and Infrared Image Pairs
Feb 15, 2024This paper proposes a deep learning based solution for multi-modal image alignment regarding UAV-taken images. Many recently proposed state-of-the-art alignment techniques rely on using Lucas-Kanade (LK) based solutions for a successful alignment. However, we show that we can achieve state of the art results without using LK-based methods. Our approach carefully utilizes a two-branch based convolutional neural network (CNN) based on feature embedding blocks. We propose two variants of our approach, where in the first variant (ModelA), we directly predict the new coordinates of only the four corners of the image to be aligned; and in the second one (ModelB), we predict the homography matrix directly. Applying alignment on the image corners forces algorithm to match only those four corners as opposed to computing and matching many (key)points, since the latter may cause many outliers, yielding less accurate alignment. We test our proposed approach on four aerial datasets and obtain state of the art results, when compared to the existing recent deep LK-based architectures.
GRJointNET: Synergistic Completion and Part Segmentation on 3D Incomplete Point Clouds
Nov 23, 2023



Segmentation of three-dimensional (3D) point clouds is an important task for autonomous systems. However, success of segmentation algorithms depends greatly on the quality of the underlying point clouds (resolution, completeness etc.). In particular, incomplete point clouds might reduce a downstream model's performance. GRNet is proposed as a novel and recent deep learning solution to complete point clouds, but it is not capable of part segmentation. On the other hand, our proposed solution, GRJointNet, is an architecture that can perform joint completion and segmentation on point clouds as a successor of GRNet. Features extracted for the two tasks are also utilized by each other to increase the overall performance. We evaluated our proposed network on the ShapeNet-Part dataset and compared its performance to GRNet. Our results demonstrate GRJointNet can outperform GRNet on point completion. It should also be noted that GRNet is not capable of segmentation while GRJointNet is. This study1, therefore, holds a promise to enhance practicality and utility of point clouds in 3D vision for autonomous systems.
A Hybrid 3D Eddy Detection Technique Based on Sea Surface Height and Velocity Field
May 14, 2023Eddy detection is a critical task for ocean scientists to understand and analyze ocean circulation. In this paper, we introduce a hybrid eddy detection approach that combines sea surface height (SSH) and velocity fields with geometric criteria defining eddy behavior. Our approach searches for SSH minima and maxima, which oceanographers expect to find at the center of eddies. Geometric criteria are used to verify expected velocity field properties, such as net rotation and symmetry, by tracing velocity components along a circular path surrounding each eddy center. Progressive searches outward and into deeper layers yield each eddy's 3D region of influence. Isolation of each eddy structure from the dataset, using it's cylindrical footprint, facilitates visualization of internal eddy structures using horizontal velocity, vertical velocity, temperature and salinity. A quantitative comparison of Okubo-Weiss vorticity (OW) thresholding, the standard winding angle, and this new SSH-velocity hybrid methods of eddy detection as applied to the Red Sea dataset suggests that detection results are highly dependent on the choices of method, thresholds, and criteria. Our new SSH-velocity hybrid detection approach has the advantages of providing eddy structures with verified rotation properties, 3D visualization of the internal structure of physical properties, and rapid efficient estimations of eddy footprints without calculating streamlines. Our approach combines visualization of internal structure and tracking overall movement to support the study of the transport mechanisms key to understanding the interaction of nutrient distribution and ocean circulation. Our method is applied to three different datasets to showcase the generality of its application.
Offloading Deep Learning Powered Vision Tasks from UAV to 5G Edge Server with Denoising
Feb 03, 2023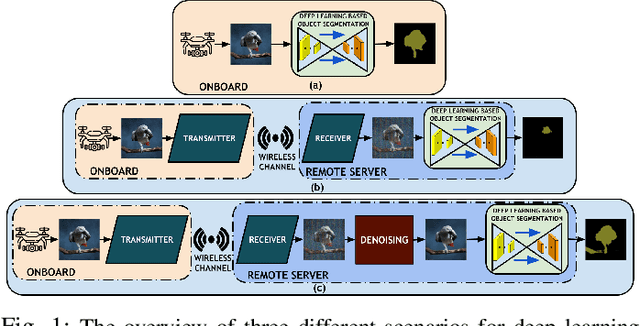
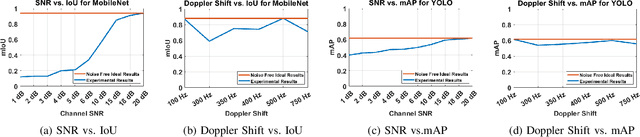
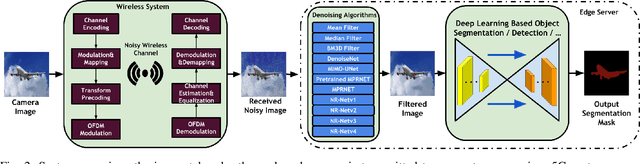
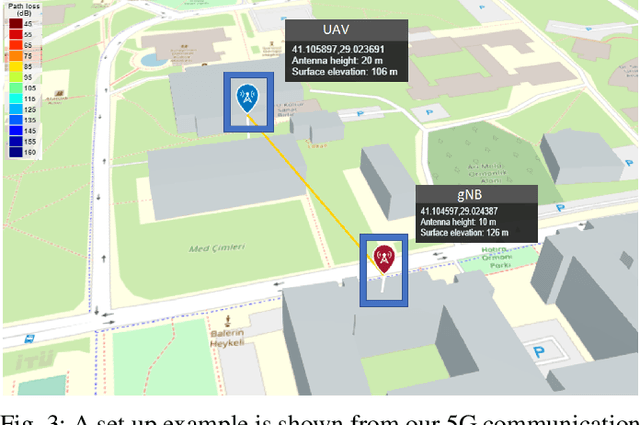
Offloading computationally heavy tasks from an unmanned aerial vehicle (UAV) to a remote server helps improve the battery life and can help reduce resource requirements. Deep learning based state-of-the-art computer vision tasks, such as object segmentation and object detection, are computationally heavy algorithms, requiring large memory and computing power. Many UAVs are using (pretrained) off-the-shelf versions of such algorithms. Offloading such power-hungry algorithms to a remote server could help UAVs save power significantly. However, deep learning based algorithms are susceptible to noise, and a wireless communication system, by its nature, introduces noise to the original signal. When the signal represents an image, noise affects the image. There has not been much work studying the effect of the noise introduced by the communication system on pretrained deep networks. In this work, we first analyze how reliable it is to offload deep learning based computer vision tasks (including both object segmentation and detection) by focusing on the effect of various parameters of a 5G wireless communication system on the transmitted image and demonstrate how the introduced noise of the used 5G wireless communication system reduces the performance of the offloaded deep learning task. Then solutions are introduced to eliminate (or reduce) the negative effect of the noise. The proposed framework starts with introducing many classical techniques as alternative solutions first, and then introduces a novel deep learning based solution to denoise the given noisy input image. The performance of various denoising algorithms on offloading both object segmentation and object detection tasks are compared. Our proposed deep transformer-based denoiser algorithm (NR-Net) yields the state-of-the-art results on reducing the negative effect of the noise in our experiments.
SyNet: An Ensemble Network for Object Detection in UAV Images
Dec 23, 2020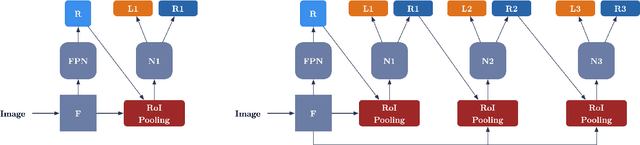
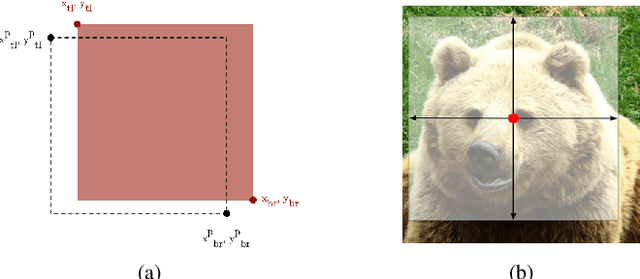
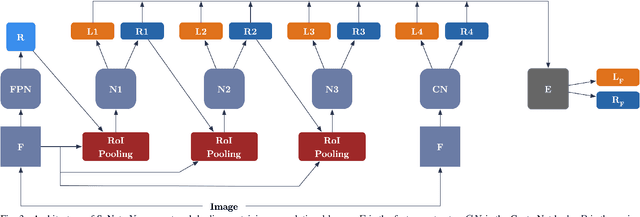

Recent advances in camera equipped drone applications and their widespread use increased the demand on vision based object detection algorithms for aerial images. Object detection process is inherently a challenging task as a generic computer vision problem, however, since the use of object detection algorithms on UAVs (or on drones) is relatively a new area, it remains as a more challenging problem to detect objects in aerial images. There are several reasons for that including: (i) the lack of large drone datasets including large object variance, (ii) the large orientation and scale variance in drone images when compared to the ground images, and (iii) the difference in texture and shape features between the ground and the aerial images. Deep learning based object detection algorithms can be classified under two main categories: (a) single-stage detectors and (b) multi-stage detectors. Both single-stage and multi-stage solutions have their advantages and disadvantages over each other. However, a technique to combine the good sides of each of those solutions could yield even a stronger solution than each of those solutions individually. In this paper, we propose an ensemble network, SyNet, that combines a multi-stage method with a single-stage one with the motivation of decreasing the high false negative rate of multi-stage detectors and increasing the quality of the single-stage detector proposals. As building blocks, CenterNet and Cascade R-CNN with pretrained feature extractors are utilized along with an ensembling strategy. We report the state of the art results obtained by our proposed solution on two different datasets: namely MS-COCO and visDrone with \%52.1 $mAP_{IoU = 0.75}$ is obtained on MS-COCO $val2017$ dataset and \%26.2 $mAP_{IoU = 0.75}$ is obtained on VisDrone $test-set$.
Deep Receiver Design for Multi-carrier Waveforms Using CNNs
Jun 02, 2020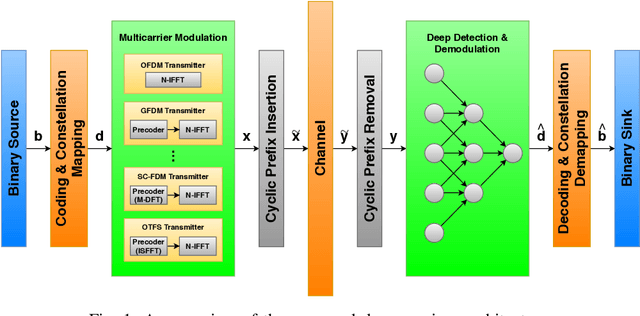
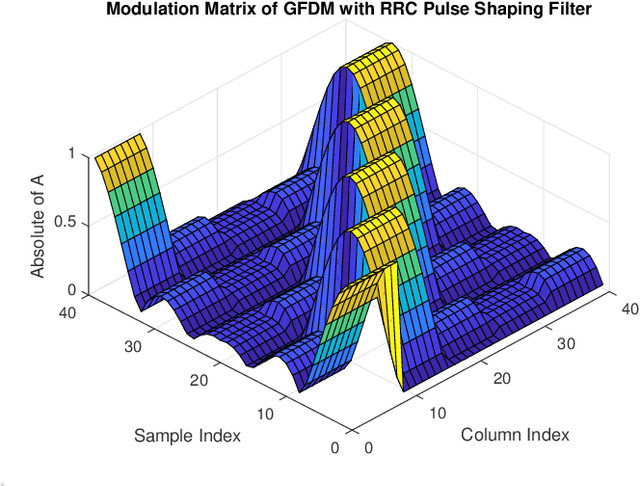
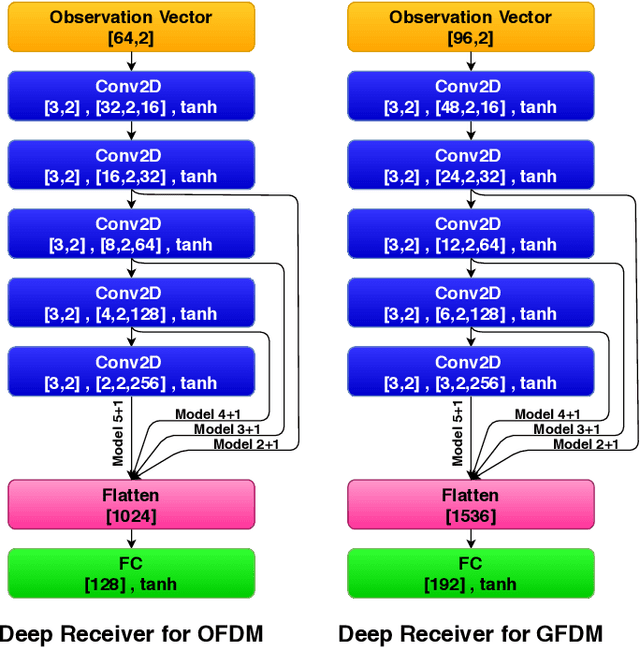
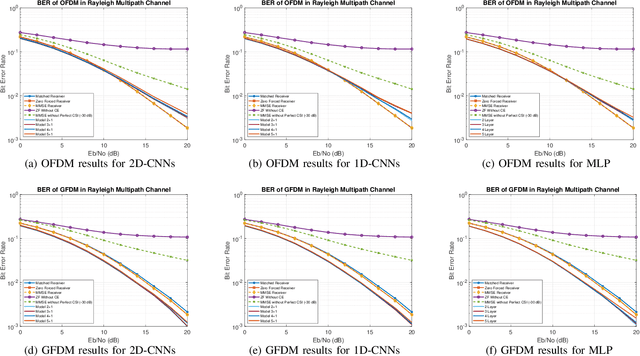
In this paper, a deep learning based receiver is proposed for a collection of multi-carrier wave-forms including both current and next-generation wireless communication systems. In particular, we propose to use a convolutional neural network (CNN) for jointly detection and demodulation of the received signal at the receiver in wireless environments. We compare our proposed architecture to the classical methods and demonstrate that our proposed CNN-based architecture can perform better on different multi-carrier forms including OFDM and GFDM in various simulations. Furthermore, we compare the total number of required parameters for each network for memory requirements.
Parametric Shape Modeling and Skeleton Extraction with Radial Basis Functions using Similarity Domains Network
Jun 01, 2019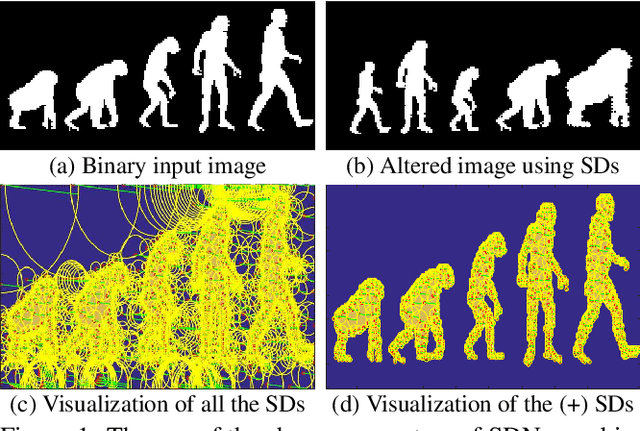
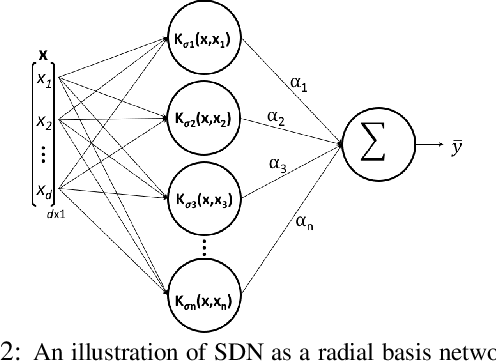

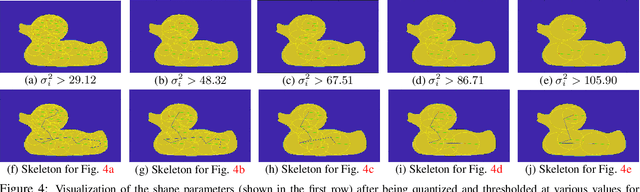
We demonstrate the use of similarity domains (SDs) for shape modeling and skeleton extraction. SDs are recently proposed and they can be utilized in a neural network framework to help us analyze shapes. SDs are modeled with radial basis functions with varying shape parameters in Similarity Domains Networks (SDNs). In this paper, we demonstrate how using SDN can first help us model a pixel-based image in terms of SDs and then demonstrate how those learned SDs can be used to extract the skeleton of a shape.
Controlling Steering Angle for Cooperative Self-driving Vehicles utilizing CNN and LSTM-based Deep Networks
May 12, 2019
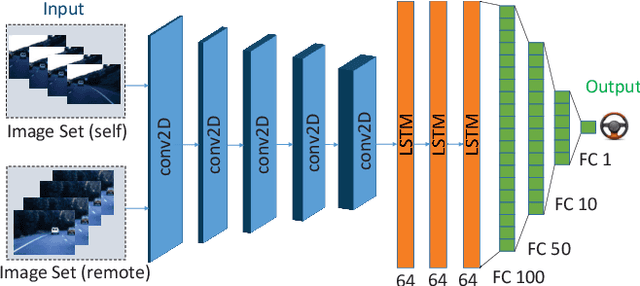

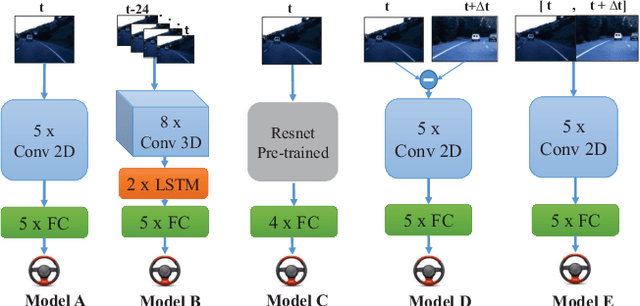
A fundamental challenge in autonomous vehicles is adjusting the steering angle at different road conditions. Recent state-of-the-art solutions addressing this challenge include deep learning techniques as they provide end-to-end solution to predict steering angles directly from the raw input images with higher accuracy. Most of these works ignore the temporal dependencies between the image frames. In this paper, we tackle the problem of utilizing multiple sets of images shared between two autonomous vehicles to improve the accuracy of controlling the steering angle by considering the temporal dependencies between the image frames. This problem has not been studied in the literature widely. We present and study a new deep architecture to predict the steering angle automatically by using Long-Short-Term-Memory (LSTM) in our deep architecture. Our deep architecture is an end-to-end network that utilizes CNN, LSTM and fully connected (FC) layers and it uses both present and futures images (shared by a vehicle ahead via Vehicle-to-Vehicle (V2V) communication) as input to control the steering angle. Our model demonstrates the lowest error when compared to the other existing approaches in the literature.
Coresets for Vector Summarization with Applications to Network Graphs
Jun 17, 2017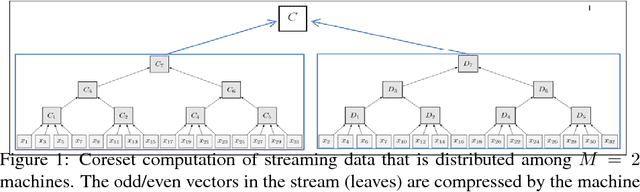
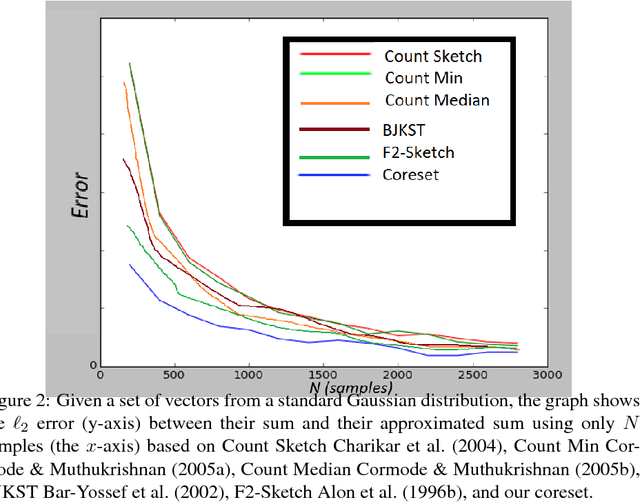
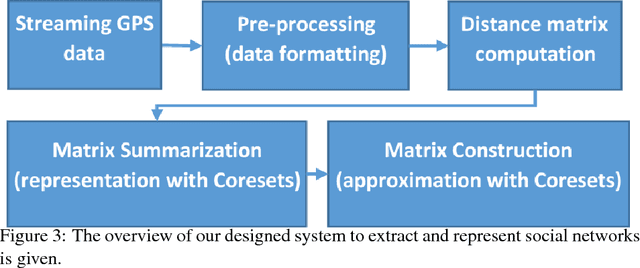
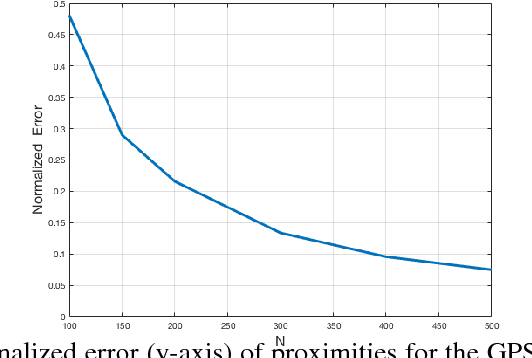
We provide a deterministic data summarization algorithm that approximates the mean $\bar{p}=\frac{1}{n}\sum_{p\in P} p$ of a set $P$ of $n$ vectors in $\REAL^d$, by a weighted mean $\tilde{p}$ of a \emph{subset} of $O(1/\eps)$ vectors, i.e., independent of both $n$ and $d$. We prove that the squared Euclidean distance between $\bar{p}$ and $\tilde{p}$ is at most $\eps$ multiplied by the variance of $P$. We use this algorithm to maintain an approximated sum of vectors from an unbounded stream, using memory that is independent of $d$, and logarithmic in the $n$ vectors seen so far. Our main application is to extract and represent in a compact way friend groups and activity summaries of users from underlying data exchanges. For example, in the case of mobile networks, we can use GPS traces to identify meetings, in the case of social networks, we can use information exchange to identify friend groups. Our algorithm provably identifies the {\it Heavy Hitter} entries in a proximity (adjacency) matrix. The Heavy Hitters can be used to extract and represent in a compact way friend groups and activity summaries of users from underlying data exchanges. We evaluate the algorithm on several large data sets.