 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoving Out: Physically-grounded Human-AI Collaboration
Jul 24, 2025The ability to adapt to physical actions and constraints in an environment is crucial for embodied agents (e.g., robots) to effectively collaborate with humans. Such physically grounded human-AI collaboration must account for the increased complexity of the continuous state-action space and constrained dynamics caused by physical constraints. In this paper, we introduce \textit{Moving Out}, a new human-AI collaboration benchmark that resembles a wide range of collaboration modes affected by physical attributes and constraints, such as moving heavy items together and maintaining consistent actions to move a big item around a corner. Using Moving Out, we designed two tasks and collected human-human interaction data to evaluate models' abilities to adapt to diverse human behaviors and unseen physical attributes. To address the challenges in physical environments, we propose a novel method, BASS (Behavior Augmentation, Simulation, and Selection), to enhance the diversity of agents and their understanding of the outcome of actions. Our experiments show that BASS outperforms state-of-the-art models in AI-AI and human-AI collaboration. The project page is available at \href{https://live-robotics-uva.github.io/movingout_ai/}{https://live-robotics-uva.github.io/movingout\_ai/}.
CaseEdit: Enhancing Localized Commonsense Reasoning via Null-Space Constrained Knowledge Editing in Small Parameter Language Models
May 26, 2025Large language models (LLMs) exhibit strong performance on factual recall and general reasoning but struggle to adapt to user-specific, commonsense knowledge, a challenge particularly acute in small-parameter settings where computational efficiency is prioritized. We introduce CaseEdit, a new dataset and generation pipeline for evaluating localized, personalized commonsense knowledge editing in small LLMs to address this. Built upon the ATOMIC20/20 commonsense graph, CaseEdit uses a multi-stage inference process to generate both typical and atypical contextual edits for household objects, paired with targeted evaluation questions across four axes: reliability, generalization, locality, and portability. We evaluate established knowledge editing methods using CaseEdit and demonstrate that AlphaEdit, a technique employing null-space projection to minimize interference with unrelated knowledge, consistently outperforms other methods when applied to an LLaMA 3.2 3B model, even in scalability tests, showing minimal ripple effects. Our results indicate that using CaseEdit with effective editing techniques like AlphaEdit allows small models to internalize high-quality, context-sensitive common-sense knowledge, paving the way for lightweight, personalized assistants.
Unforgettable Lessons from Forgettable Images: Intra-Class Memorability Matters in Computer Vision Tasks
Dec 30, 2024



We introduce intra-class memorability, where certain images within the same class are more memorable than others despite shared category characteristics. To investigate what features make one object instance more memorable than others, we design and conduct human behavior experiments, where participants are shown a series of images one at a time, and they must identify when the current item matches the item presented a few steps back in the sequence. To quantify memorability, we propose the Intra-Class Memorability score (ICMscore), a novel metric that incorporates the temporal intervals between repeated image presentations into its calculation. Our contributions open new pathways in understanding intra-class memorability by scrutinizing fine-grained visual features that result in the least and most memorable images and laying the groundwork for real-world applications in cognitive science and computer vision.
Gazing at Rewards: Eye Movements as a Lens into Human and AI Decision-Making in Hybrid Visual Foraging
Nov 14, 2024
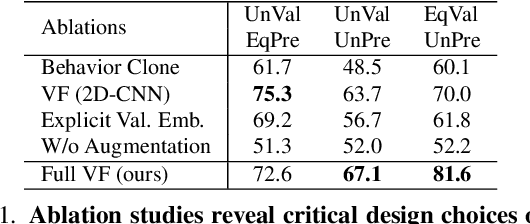


Imagine searching a collection of coins for quarters ($0.25$), dimes ($0.10$), nickels ($0.05$), and pennies ($0.01$)-a hybrid foraging task where observers look for multiple instances of multiple target types. In such tasks, how do target values and their prevalence influence foraging and eye movement behaviors (e.g., should you prioritize rare quarters or common nickels)? To explore this, we conducted human psychophysics experiments, revealing that humans are proficient reward foragers. Their eye fixations are drawn to regions with higher average rewards, fixation durations are longer on more valuable targets, and their cumulative rewards exceed chance, approaching the upper bound of optimal foragers. To probe these decision-making processes of humans, we developed a transformer-based Visual Forager (VF) model trained via reinforcement learning. Our VF model takes a series of targets, their corresponding values, and the search image as inputs, processes the images using foveated vision, and produces a sequence of eye movements along with decisions on whether to collect each fixated item. Our model outperforms all baselines, achieves cumulative rewards comparable to those of humans, and approximates human foraging behavior in eye movements and foraging biases within time-limited environments. Furthermore, stress tests on out-of-distribution tasks with novel targets, unseen values, and varying set sizes demonstrate the VF model's effective generalization. Our work offers valuable insights into the relationship between eye movements and decision-making, with our model serving as a powerful tool for further exploration of this connection. All data, code, and models will be made publicly available.
Diff-DAgger: Uncertainty Estimation with Diffusion Policy for Robotic Manipulation
Oct 18, 2024Recently, diffusion policy has shown impressive results in handling multi-modal tasks in robotic manipulation. However, it has fundamental limitations in out-of-distribution failures that persist due to compounding errors and its limited capability to extrapolate. One way to address these limitations is robot-gated DAgger, an interactive imitation learning with a robot query system to actively seek expert help during policy rollout. While robot-gated DAgger has high potential for learning at scale, existing methods like Ensemble-DAgger struggle with highly expressive policies: They often misinterpret policy disagreements as uncertainty at multi-modal decision points. To address this problem, we introduce Diff-DAgger, an efficient robot-gated DAgger algorithm that leverages the training objective of diffusion policy. We evaluate Diff-DAgger across different robot tasks including stacking, pushing, and plugging, and show that Diff-DAgger improves the task failure prediction by 37%, the task completion rate by 14%, and reduces the wall-clock time by up to 540%. We hope that this work opens up a path for efficiently incorporating expressive yet data-hungry policies into interactive robot learning settings.
Incorporating Task Progress Knowledge for Subgoal Generation in Robotic Manipulation through Image Edits
Oct 14, 2024



Understanding the progress of a task allows humans to not only track what has been done but also to better plan for future goals. We demonstrate TaKSIE, a novel framework that incorporates task progress knowledge into visual subgoal generation for robotic manipulation tasks. We jointly train a recurrent network with a latent diffusion model to generate the next visual subgoal based on the robot's current observation and the input language command. At execution time, the robot leverages a visual progress representation to monitor the task progress and adaptively samples the next visual subgoal from the model to guide the manipulation policy. We train and validate our model in simulated and real-world robotic tasks, achieving state-of-the-art performance on the CALVIN manipulation benchmark. We find that the inclusion of task progress knowledge can improve the robustness of trained policy for different initial robot poses or various movement speeds during demonstrations. The project website can be found at https://live-robotics-uva.github.io/TaKSIE/ .
MuMA-ToM: Multi-modal Multi-Agent Theory of Mind
Aug 22, 2024Understanding people's social interactions in complex real-world scenarios often relies on intricate mental reasoning. To truly understand how and why people interact with one another, we must infer the underlying mental states that give rise to the social interactions, i.e., Theory of Mind reasoning in multi-agent interactions. Additionally, social interactions are often multi-modal -- we can watch people's actions, hear their conversations, and/or read about their past behaviors. For AI systems to successfully and safely interact with people in real-world environments, they also need to understand people's mental states as well as their inferences about each other's mental states based on multi-modal information about their interactions. For this, we introduce MuMA-ToM, a Multi-modal Multi-Agent Theory of Mind benchmark. MuMA-ToM is the first multi-modal Theory of Mind benchmark that evaluates mental reasoning in embodied multi-agent interactions. In MuMA-ToM, we provide video and text descriptions of people's multi-modal behavior in realistic household environments. Based on the context, we then ask questions about people's goals, beliefs, and beliefs about others' goals. We validated MuMA-ToM in a human experiment and provided a human baseline. We also proposed a novel multi-modal, multi-agent ToM model, LIMP (Language model-based Inverse Multi-agent Planning). Our experimental results show that LIMP significantly outperforms state-of-the-art methods, including large multi-modal models (e.g., GPT-4o, Gemini-1.5 Pro) and a recent multi-modal ToM model, BIP-ALM.
Baba Is AI: Break the Rules to Beat the Benchmark
Jul 18, 2024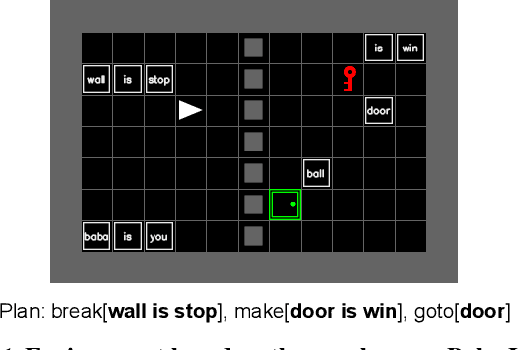

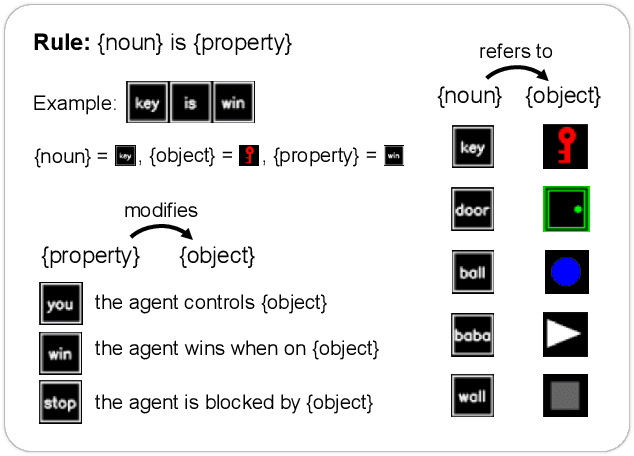
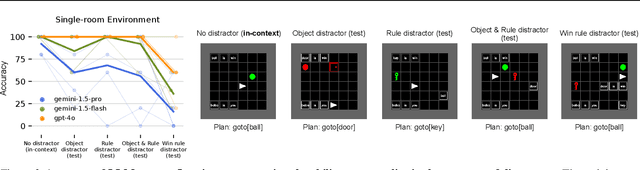
Humans solve problems by following existing rules and procedures, and also by leaps of creativity to redefine those rules and objectives. To probe these abilities, we developed a new benchmark based on the game Baba Is You where an agent manipulates both objects in the environment and rules, represented by movable tiles with words written on them, to reach a specified goal and win the game. We test three state-of-the-art multi-modal large language models (OpenAI GPT-4o, Google Gemini-1.5-Pro and Gemini-1.5-Flash) and find that they fail dramatically when generalization requires that the rules of the game must be manipulated and combined.
A Transformer-Based Model for the Prediction of Human Gaze Behavior on Videos
Apr 10, 2024



Eye-tracking applications that utilize the human gaze in video understanding tasks have become increasingly important. To effectively automate the process of video analysis based on eye-tracking data, it is important to accurately replicate human gaze behavior. However, this task presents significant challenges due to the inherent complexity and ambiguity of human gaze patterns. In this work, we introduce a novel method for simulating human gaze behavior. Our approach uses a transformer-based reinforcement learning algorithm to train an agent that acts as a human observer, with the primary role of watching videos and simulating human gaze behavior. We employed an eye-tracking dataset gathered from videos generated by the VirtualHome simulator, with a primary focus on activity recognition. Our experimental results demonstrate the effectiveness of our gaze prediction method by highlighting its capability to replicate human gaze behavior and its applicability for downstream tasks where real human-gaze is used as input.
Gaze-Guided Graph Neural Network for Action Anticipation Conditioned on Intention
Apr 10, 2024Humans utilize their gaze to concentrate on essential information while perceiving and interpreting intentions in videos. Incorporating human gaze into computational algorithms can significantly enhance model performance in video understanding tasks. In this work, we address a challenging and innovative task in video understanding: predicting the actions of an agent in a video based on a partial video. We introduce the Gaze-guided Action Anticipation algorithm, which establishes a visual-semantic graph from the video input. Our method utilizes a Graph Neural Network to recognize the agent's intention and predict the action sequence to fulfill this intention. To assess the efficiency of our approach, we collect a dataset containing household activities generated in the VirtualHome environment, accompanied by human gaze data of viewing videos. Our method outperforms state-of-the-art techniques, achieving a 7\% improvement in accuracy for 18-class intention recognition. This highlights the efficiency of our method in learning important features from human gaze data.