 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafeguarding Privacy: Privacy-Preserving Detection of Mind Wandering and Disengagement Using Federated Learning in Online Education
Feb 10, 2026Since the COVID-19 pandemic, online courses have expanded access to education, yet the absence of direct instructor support challenges learners' ability to self-regulate attention and engagement. Mind wandering and disengagement can be detrimental to learning outcomes, making their automated detection via video-based indicators a promising approach for real-time learner support. However, machine learning-based approaches often require sharing sensitive data, raising privacy concerns. Federated learning offers a privacy-preserving alternative by enabling decentralized model training while also distributing computational load. We propose a framework exploiting cross-device federated learning to address different manifestations of behavioral and cognitive disengagement during remote learning, specifically behavioral disengagement, mind wandering, and boredom. We fit video-based cognitive disengagement detection models using facial expressions and gaze features. By adopting federated learning, we safeguard users' data privacy through privacy-by-design and introduce a novel solution with the potential for real-time learner support. We further address challenges posed by eyeglasses by incorporating related features, enhancing overall model performance. To validate the performance of our approach, we conduct extensive experiments on five datasets and benchmark multiple federated learning algorithms. Our results show great promise for privacy-preserving educational technologies promoting learner engagement.
Exploring User Acceptance and Concerns toward LLM-powered Conversational Agents in Immersive Extended Reality
Dec 17, 2025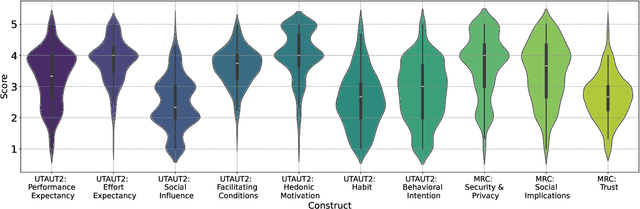
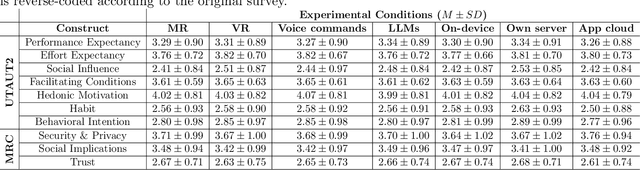
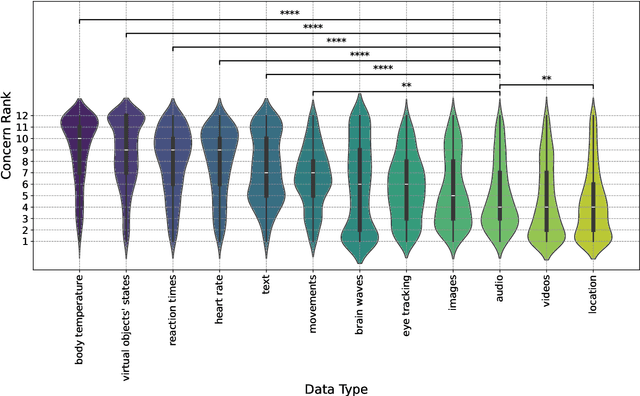
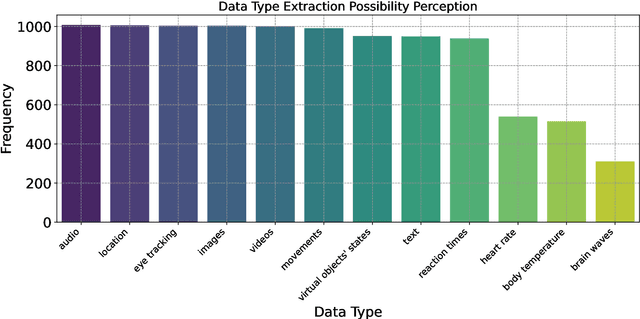
The rapid development of generative artificial intelligence (AI) and large language models (LLMs), and the availability of services that make them accessible, have led the general public to begin incorporating them into everyday life. The extended reality (XR) community has also sought to integrate LLMs, particularly in the form of conversational agents, to enhance user experience and task efficiency. When interacting with such conversational agents, users may easily disclose sensitive information due to the naturalistic flow of the conversations, and combining such conversational data with fine-grained sensor data may lead to novel privacy issues. To address these issues, a user-centric understanding of technology acceptance and concerns is essential. Therefore, to this end, we conducted a large-scale crowdsourcing study with 1036 participants, examining user decision-making processes regarding LLM-powered conversational agents in XR, across factors of XR setting type, speech interaction type, and data processing location. We found that while users generally accept these technologies, they express concerns related to security, privacy, social implications, and trust. Our results suggest that familiarity plays a crucial role, as daily generative AI use is associated with greater acceptance. In contrast, previous ownership of XR devices is linked to less acceptance, possibly due to existing familiarity with the settings. We also found that men report higher acceptance with fewer concerns than women. Regarding data type sensitivity, location data elicited the most significant concern, while body temperature and virtual object states were considered least sensitive. Overall, our study highlights the importance of practitioners effectively communicating their measures to users, who may remain distrustful. We conclude with implications and recommendations for LLM-powered XR.
Cross-View Cross-Modal Unsupervised Domain Adaptation for Driver Monitoring System
Nov 15, 2025


Driver distraction remains a leading cause of road traffic accidents, contributing to thousands of fatalities annually across the globe. While deep learning-based driver activity recognition methods have shown promise in detecting such distractions, their effectiveness in real-world deployments is hindered by two critical challenges: variations in camera viewpoints (cross-view) and domain shifts such as change in sensor modality or environment. Existing methods typically address either cross-view generalization or unsupervised domain adaptation in isolation, leaving a gap in the robust and scalable deployment of models across diverse vehicle configurations. In this work, we propose a novel two-phase cross-view, cross-modal unsupervised domain adaptation framework that addresses these challenges jointly on real-time driver monitoring data. In the first phase, we learn view-invariant and action-discriminative features within a single modality using contrastive learning on multi-view data. In the second phase, we perform domain adaptation to a new modality using information bottleneck loss without requiring any labeled data from the new domain. We evaluate our approach using state-of-the art video transformers (Video Swin, MViT) and multi modal driver activity dataset called Drive&Act, demonstrating that our joint framework improves top-1 accuracy on RGB video data by almost 50% compared to a supervised contrastive learning-based cross-view method, and outperforms unsupervised domain adaptation-only methods by up to 5%, using the same video transformer backbone.
A Novel Signal Processing Strategy for Short-Range Laser Feedback Interferometry Sensors
Jun 12, 2025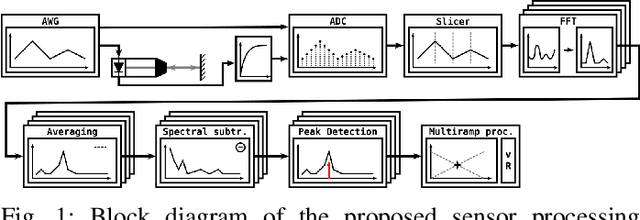
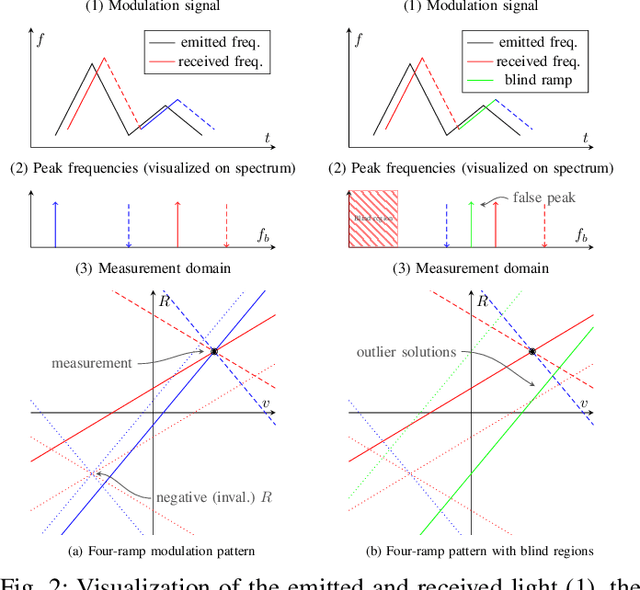
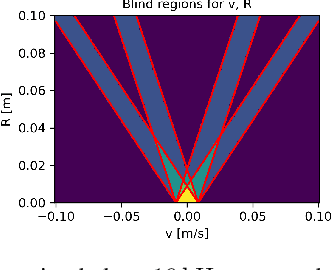

The rapid evolution of wearable technologies, such as AR glasses, demands compact, energy-efficient sensors capable of high-precision measurements in dynamic environments. Traditional Frequency-Modulated Continuous Wave (FMCW) Laser Feedback Interferometry (LFI) sensors, while promising, falter in applications that feature small distances, high velocities, shallow modulation, and low-power constraints. We propose a novel sensor-processing pipeline that reliably extracts distance and velocity measurements at distances as low as 1 cm. As a core contribution, we introduce a four-ramp modulation scheme that resolves persistent ambiguities in beat frequency signs and overcomes spectral blind regions caused by hardware limitations. Based on measurements of the implemented pipeline, a noise model is defined to evaluate its performance and sensitivity to several algorithmic and working point parameters. We show that the pipeline generally achieves robust and low-noise measurements using state-of-the-art hardware.
Position: Uncertainty Quantification Needs Reassessment for Large-language Model Agents
May 28, 2025Large-language models (LLMs) and chatbot agents are known to provide wrong outputs at times, and it was recently found that this can never be fully prevented. Hence, uncertainty quantification plays a crucial role, aiming to quantify the level of ambiguity in either one overall number or two numbers for aleatoric and epistemic uncertainty. This position paper argues that this traditional dichotomy of uncertainties is too limited for the open and interactive setup that LLM agents operate in when communicating with a user, and that we need to research avenues that enrich uncertainties in this novel scenario. We review the literature and find that popular definitions of aleatoric and epistemic uncertainties directly contradict each other and lose their meaning in interactive LLM agent settings. Hence, we propose three novel research directions that focus on uncertainties in such human-computer interactions: Underspecification uncertainties, for when users do not provide all information or define the exact task at the first go, interactive learning, to ask follow-up questions and reduce the uncertainty about the current context, and output uncertainties, to utilize the rich language and speech space to express uncertainties as more than mere numbers. We expect that these new ways of dealing with and communicating uncertainties will lead to LLM agent interactions that are more transparent, trustworthy, and intuitive.
Examining the Role of LLM-Driven Interactions on Attention and Cognitive Engagement in Virtual Classrooms
May 12, 2025Transforming educational technologies through the integration of large language models (LLMs) and virtual reality (VR) offers the potential for immersive and interactive learning experiences. However, the effects of LLMs on user engagement and attention in educational environments remain open questions. In this study, we utilized a fully LLM-driven virtual learning environment, where peers and teachers were LLM-driven, to examine how students behaved in such settings. Specifically, we investigate how peer question-asking behaviors influenced student engagement, attention, cognitive load, and learning outcomes and found that, in conditions where LLM-driven peer learners asked questions, students exhibited more targeted visual scanpaths, with their attention directed toward the learning content, particularly in complex subjects. Our results suggest that peer questions did not introduce extraneous cognitive load directly, as the cognitive load is strongly correlated with increased attention to the learning material. Considering these findings, we provide design recommendations for optimizing VR learning spaces.
Automated Visual Attention Detection using Mobile Eye Tracking in Behavioral Classroom Studies
May 12, 2025Teachers' visual attention and its distribution across the students in classrooms can constitute important implications for student engagement, achievement, and professional teacher training. Despite that, inferring the information about where and which student teachers focus on is not trivial. Mobile eye tracking can provide vital help to solve this issue; however, the use of mobile eye tracking alone requires a significant amount of manual annotations. To address this limitation, we present an automated processing pipeline concept that requires minimal manually annotated data to recognize which student the teachers focus on. To this end, we utilize state-of-the-art face detection models and face recognition feature embeddings to train face recognition models with transfer learning in the classroom context and combine these models with the teachers' gaze from mobile eye trackers. We evaluated our approach with data collected from four different classrooms, and our results show that while it is possible to estimate the visually focused students with reasonable performance in all of our classroom setups, U-shaped and small classrooms led to the best results with accuracies of approximately 0.7 and 0.9, respectively. While we did not evaluate our method for teacher-student interactions and focused on the validity of the technical approach, as our methodology does not require a vast amount of manually annotated data and offers a non-intrusive way of handling teachers' visual attention, it could help improve instructional strategies, enhance classroom management, and provide feedback for professional teacher development.
Multimodal Assessment of Classroom Discourse Quality: A Text-Centered Attention-Based Multi-Task Learning Approach
May 12, 2025Classroom discourse is an essential vehicle through which teaching and learning take place. Assessing different characteristics of discursive practices and linking them to student learning achievement enhances the understanding of teaching quality. Traditional assessments rely on manual coding of classroom observation protocols, which is time-consuming and costly. Despite many studies utilizing AI techniques to analyze classroom discourse at the utterance level, investigations into the evaluation of discursive practices throughout an entire lesson segment remain limited. To address this gap, our study proposes a novel text-centered multimodal fusion architecture to assess the quality of three discourse components grounded in the Global Teaching InSights (GTI) observation protocol: Nature of Discourse, Questioning, and Explanations. First, we employ attention mechanisms to capture inter- and intra-modal interactions from transcript, audio, and video streams. Second, a multi-task learning approach is adopted to jointly predict the quality scores of the three components. Third, we formulate the task as an ordinal classification problem to account for rating level order. The effectiveness of these designed elements is demonstrated through an ablation study on the GTI Germany dataset containing 92 videotaped math lessons. Our results highlight the dominant role of text modality in approaching this task. Integrating acoustic features enhances the model's consistency with human ratings, achieving an overall Quadratic Weighted Kappa score of 0.384, comparable to human inter-rater reliability (0.326). Our study lays the groundwork for the future development of automated discourse quality assessment to support teacher professional development through timely feedback on multidimensional discourse practices.
Exploring Context-aware and LLM-driven Locomotion for Immersive Virtual Reality
Apr 24, 2025
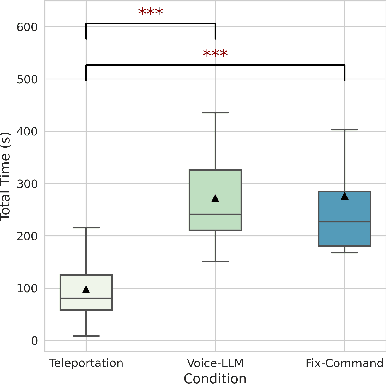
Locomotion plays a crucial role in shaping the user experience within virtual reality environments. In particular, hands-free locomotion offers a valuable alternative by supporting accessibility and freeing users from reliance on handheld controllers. To this end, traditional speech-based methods often depend on rigid command sets, limiting the naturalness and flexibility of interaction. In this study, we propose a novel locomotion technique powered by large language models (LLMs), which allows users to navigate virtual environments using natural language with contextual awareness. We evaluate three locomotion methods: controller-based teleportation, voice-based steering, and our language model-driven approach. Our evaluation measures include eye-tracking data analysis, including explainable machine learning through SHAP analysis as well as standardized questionnaires for usability, presence, cybersickness, and cognitive load to examine user attention and engagement. Our findings indicate that the LLM-driven locomotion possesses comparable usability, presence, and cybersickness scores to established methods like teleportation, demonstrating its novel potential as a comfortable, natural language-based, hands-free alternative. In addition, it enhances user attention within the virtual environment, suggesting greater engagement. Complementary to these findings, SHAP analysis revealed that fixation, saccade, and pupil-related features vary across techniques, indicating distinct patterns of visual attention and cognitive processing. Overall, we state that our method can facilitate hands-free locomotion in virtual spaces, especially in supporting accessibility.
Trade-offs in Privacy-Preserving Eye Tracking through Iris Obfuscation: A Benchmarking Study
Apr 15, 2025
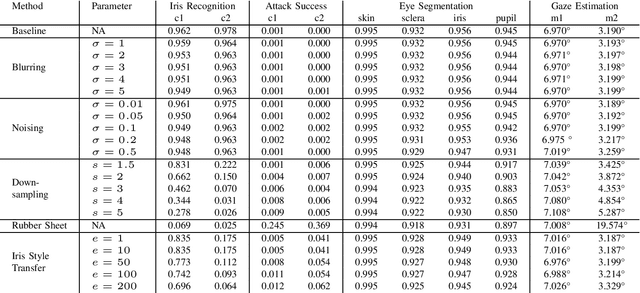
Recent developments in hardware, computer graphics, and AI may soon enable AR/VR head-mounted displays (HMDs) to become everyday devices like smartphones and tablets. Eye trackers within HMDs provide a special opportunity for such setups as it is possible to facilitate gaze-based research and interaction. However, estimating users' gaze information often requires raw eye images and videos that contain iris textures, which are considered a gold standard biometric for user authentication, and this raises privacy concerns. Previous research in the eye-tracking community focused on obfuscating iris textures while keeping utility tasks such as gaze estimation accurate. Despite these attempts, there is no comprehensive benchmark that evaluates state-of-the-art approaches. Considering all, in this paper, we benchmark blurring, noising, downsampling, rubber sheet model, and iris style transfer to obfuscate user identity, and compare their impact on image quality, privacy, utility, and risk of imposter attack on two datasets. We use eye segmentation and gaze estimation as utility tasks, and reduction in iris recognition accuracy as a measure of privacy protection, and false acceptance rate to estimate risk of attack. Our experiments show that canonical image processing methods like blurring and noising cause a marginal impact on deep learning-based tasks. While downsampling, rubber sheet model, and iris style transfer are effective in hiding user identifiers, iris style transfer, with higher computation cost, outperforms others in both utility tasks, and is more resilient against spoof attacks. Our analyses indicate that there is no universal optimal approach to balance privacy, utility, and computation burden. Therefore, we recommend practitioners consider the strengths and weaknesses of each approach, and possible combinations of those to reach an optimal privacy-utility trade-off.