 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge2D or 3D: Who Governs Salience in VLA Models? -- Tri-Stage Token Pruning Framework with Modality Salience Awareness
Apr 10, 2026Vision-Language-Action (VLA) models have emerged as the mainstream of embodied intelligence. Recent VLA models have expanded their input modalities from 2D-only to 2D+3D paradigms, forming multi-visual-modal VLA (MVLA) models. Despite achieving improved spatial perception, MVLA faces a greater acceleration demand due to the increased number of input tokens caused by modal expansion. Token pruning is an effective optimization methods tailored to MVLA models. However, existing token pruning schemes are designed for 2D-only VLA models, ignoring 2D/3D modality salience differences. In this paper, we follow the application process of multi-modal data in MVLA models and develop a tri-stage analysis to capture the discrepancy and dynamics of 2D/3D modality salience. Based on these, we propose a corresponding tri-stage token pruning framework for MVLA models to achieve optimal 2D/3D token selection and efficient pruning. Experiments show that our framework achieves up to a 2.55x inference speedup with minimal accuracy loss, while only costing 5.8% overhead. Our Code is coming soon.
Agentic Video Intelligence: A Flexible Framework for Advanced Video Exploration and Understanding
Nov 18, 2025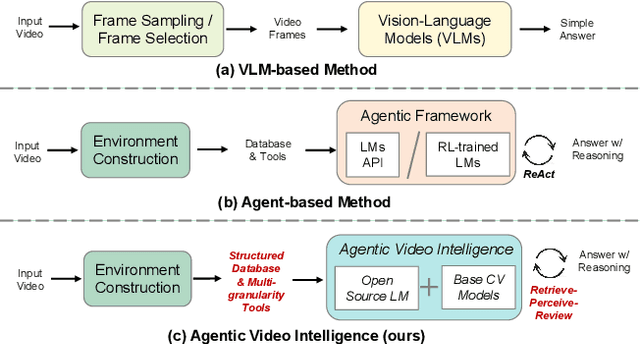
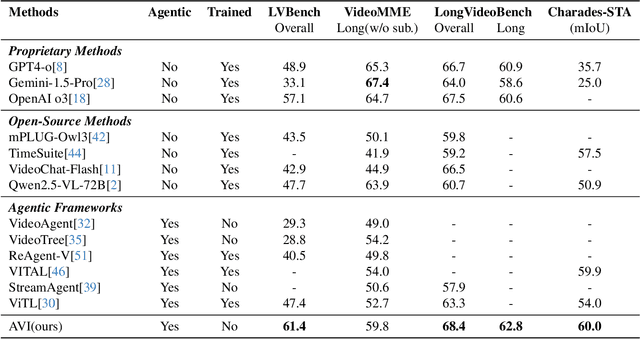
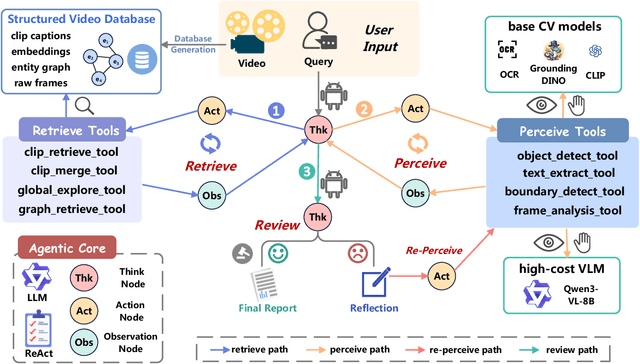
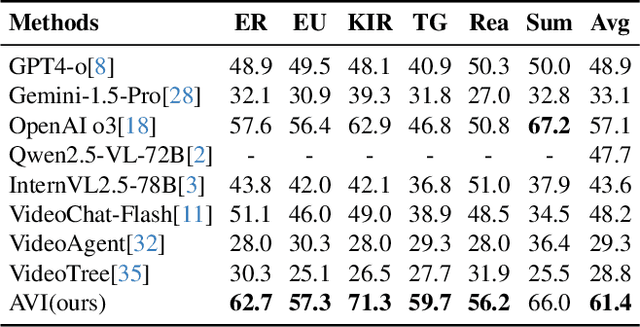
Video understanding requires not only visual recognition but also complex reasoning. While Vision-Language Models (VLMs) demonstrate impressive capabilities, they typically process videos largely in a single-pass manner with limited support for evidence revisit and iterative refinement. While recently emerging agent-based methods enable long-horizon reasoning, they either depend heavily on expensive proprietary models or require extensive agentic RL training. To overcome these limitations, we propose Agentic Video Intelligence (AVI), a flexible and training-free framework that can mirror human video comprehension through system-level design and optimization. AVI introduces three key innovations: (1) a human-inspired three-phase reasoning process (Retrieve-Perceive-Review) that ensures both sufficient global exploration and focused local analysis, (2) a structured video knowledge base organized through entity graphs, along with multi-granularity integrated tools, constituting the agent's interaction environment, and (3) an open-source model ensemble combining reasoning LLMs with lightweight base CV models and VLM, eliminating dependence on proprietary APIs or RL training. Experiments on LVBench, VideoMME-Long, LongVideoBench, and Charades-STA demonstrate that AVI achieves competitive performance while offering superior interpretability.
APVR: Hour-Level Long Video Understanding with Adaptive Pivot Visual Information Retrieval
Jun 05, 2025Current video-based multimodal large language models struggle with hour-level video understanding due to computational constraints and inefficient information extraction from extensive temporal sequences. We propose APVR (Adaptive Pivot Visual information Retrieval), a training-free framework that addresses the memory wall limitation through hierarchical visual information retrieval. APVR operates via two complementary components: Pivot Frame Retrieval employs semantic expansion and multi-modal confidence scoring to identify semantically relevant video frames, while Pivot Token Retrieval performs query-aware attention-driven token selection within the pivot frames. This dual granularity approach enables processing of hour-long videos while maintaining semantic fidelity. Experimental validation on LongVideoBench and VideoMME demonstrates significant performance improvements, establishing state-of-the-art results for not only training-free but also training-based approaches while providing plug-and-play integration capability with existing MLLM architectures.
Examining the Role of LLM-Driven Interactions on Attention and Cognitive Engagement in Virtual Classrooms
May 12, 2025Transforming educational technologies through the integration of large language models (LLMs) and virtual reality (VR) offers the potential for immersive and interactive learning experiences. However, the effects of LLMs on user engagement and attention in educational environments remain open questions. In this study, we utilized a fully LLM-driven virtual learning environment, where peers and teachers were LLM-driven, to examine how students behaved in such settings. Specifically, we investigate how peer question-asking behaviors influenced student engagement, attention, cognitive load, and learning outcomes and found that, in conditions where LLM-driven peer learners asked questions, students exhibited more targeted visual scanpaths, with their attention directed toward the learning content, particularly in complex subjects. Our results suggest that peer questions did not introduce extraneous cognitive load directly, as the cognitive load is strongly correlated with increased attention to the learning material. Considering these findings, we provide design recommendations for optimizing VR learning spaces.
NTIRE 2025 Challenge on Cross-Domain Few-Shot Object Detection: Methods and Results
Apr 14, 2025Cross-Domain Few-Shot Object Detection (CD-FSOD) poses significant challenges to existing object detection and few-shot detection models when applied across domains. In conjunction with NTIRE 2025, we organized the 1st CD-FSOD Challenge, aiming to advance the performance of current object detectors on entirely novel target domains with only limited labeled data. The challenge attracted 152 registered participants, received submissions from 42 teams, and concluded with 13 teams making valid final submissions. Participants approached the task from diverse perspectives, proposing novel models that achieved new state-of-the-art (SOTA) results under both open-source and closed-source settings. In this report, we present an overview of the 1st NTIRE 2025 CD-FSOD Challenge, highlighting the proposed solutions and summarizing the results submitted by the participants.
Evaluating Usability and Engagement of Large Language Models in Virtual Reality for Traditional Scottish Curling
Aug 17, 2024



This paper explores the innovative application of Large Language Models (LLMs) in Virtual Reality (VR) environments to promote heritage education, focusing on traditional Scottish curling presented in the game ``Scottish Bonspiel VR''. Our study compares the effectiveness of LLM-based chatbots with pre-defined scripted chatbots, evaluating key criteria such as usability, user engagement, and learning outcomes. The results show that LLM-based chatbots significantly improve interactivity and engagement, creating a more dynamic and immersive learning environment. This integration helps document and preserve cultural heritage and enhances dissemination processes, which are crucial for safeguarding intangible cultural heritage (ICH) amid environmental changes. Furthermore, the study highlights the potential of novel technologies in education to provide immersive experiences that foster a deeper appreciation of cultural heritage. These findings support the wider application of LLMs and VR in cultural education to address global challenges and promote sustainable practices to preserve and enhance cultural heritage.
Embedding Large Language Models into Extended Reality: Opportunities and Challenges for Inclusion, Engagement, and Privacy
Feb 06, 2024Recent developments in computer graphics, hardware, artificial intelligence (AI), and human-computer interaction likely lead to extended reality (XR) devices and setups being more pervasive. While these devices and setups provide users with interactive, engaging, and immersive experiences with different sensing modalities, such as eye and hand trackers, many non-player characters are utilized in a pre-scripted way or by conventional AI techniques. In this paper, we argue for using large language models (LLMs) in XR by embedding them in virtual avatars or as narratives to facilitate more inclusive experiences through prompt engineering according to user profiles and fine-tuning the LLMs for particular purposes. We argue that such inclusion will facilitate diversity for XR use. In addition, we believe that with the versatile conversational capabilities of LLMs, users will engage more with XR environments, which might help XR be more used in everyday life. Lastly, we speculate that combining the information provided to LLM-powered environments by the users and the biometric data obtained through the sensors might lead to novel privacy invasions. While studying such possible privacy invasions, user privacy concerns and preferences should also be investigated. In summary, despite some challenges, embedding LLMs into XR is a promising and novel research area with several opportunities.
Eye-tracked Virtual Reality: A Comprehensive Survey on Methods and Privacy Challenges
May 23, 2023



Latest developments in computer hardware, sensor technologies, and artificial intelligence can make virtual reality (VR) and virtual spaces an important part of human everyday life. Eye tracking offers not only a hands-free way of interaction but also the possibility of a deeper understanding of human visual attention and cognitive processes in VR. Despite these possibilities, eye-tracking data also reveal privacy-sensitive attributes of users when it is combined with the information about the presented stimulus. To address these possibilities and potential privacy issues, in this survey, we first cover major works in eye tracking, VR, and privacy areas between the years 2012 and 2022. While eye tracking in the VR part covers the complete pipeline of eye-tracking methodology from pupil detection and gaze estimation to offline use and analyses, as for privacy and security, we focus on eye-based authentication as well as computational methods to preserve the privacy of individuals and their eye-tracking data in VR. Later, taking all into consideration, we draw three main directions for the research community by mainly focusing on privacy challenges. In summary, this survey provides an extensive literature review of the utmost possibilities with eye tracking in VR and the privacy implications of those possibilities.
ExperienceThinking: Hyperparameter Optimization with Budget Constraints
Dec 02, 2019
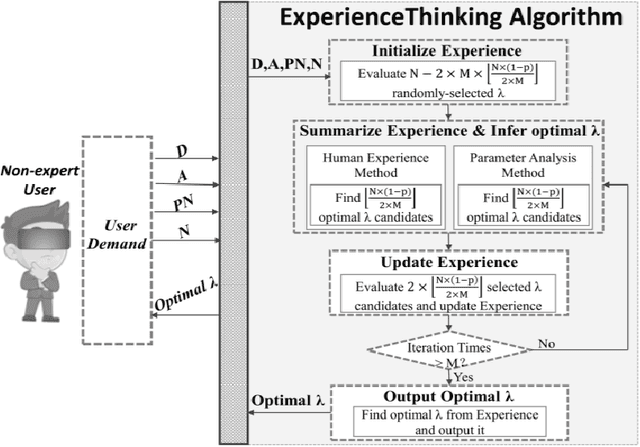
The problem of hyperparameter optimization exists widely in the real life and many common tasks can be transformed into it, such as neural architecture search and feature subset selection. Without considering various constraints, the existing hyperparameter tuning techniques can solve these problems effectively by traversing as many hyperparameter configurations as possible. However, because of the limited resources and budget, it is not feasible to evaluate so many kinds of configurations, which requires us to design effective algorithms to find a best possible hyperparameter configuration with a finite number of configuration evaluations. In this paper, we simulate human thinking processes and combine the merit of the existing techniques, and thus propose a new algorithm called ExperienceThinking, trying to solve this constrained hyperparameter optimization problem. In addition, we analyze the performances of 3 classical hyperparameter optimization algorithms with a finite number of configuration evaluations, and compare with that of ExperienceThinking. The experimental results show that our proposed algorithm provides superior results and has better performance.
Auto-Model: Utilizing Research Papers and HPO Techniques to Deal with the CASH problem
Oct 24, 2019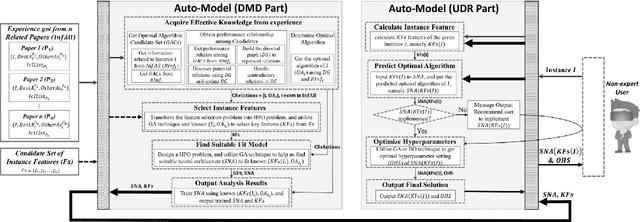



In many fields, a mass of algorithms with completely different hyperparameters have been developed to address the same type of problems. Choosing the algorithm and hyperparameter setting correctly can promote the overall performance greatly, but users often fail to do so due to the absence of knowledge. How to help users to effectively and quickly select the suitable algorithm and hyperparameter settings for the given task instance is an important research topic nowadays, which is known as the CASH problem. In this paper, we design the Auto-Model approach, which makes full use of known information in the related research paper and introduces hyperparameter optimization techniques, to solve the CASH problem effectively. Auto-Model tremendously reduces the cost of algorithm implementations and hyperparameter configuration space, and thus capable of dealing with the CASH problem efficiently and easily. To demonstrate the benefit of Auto-Model, we compare it with classical Auto-Weka approach. The experimental results show that our proposed approach can provide superior results and achieves better performance in a short time.