 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic Video Intelligence: A Flexible Framework for Advanced Video Exploration and Understanding
Nov 18, 2025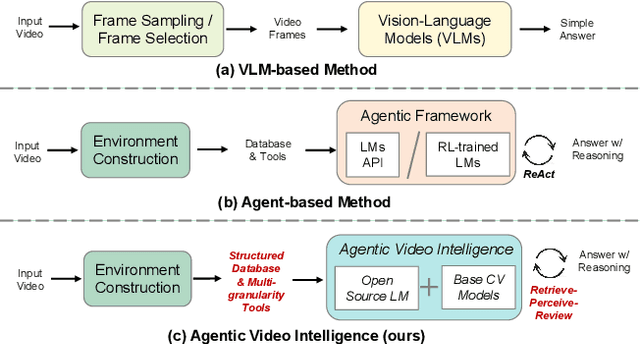
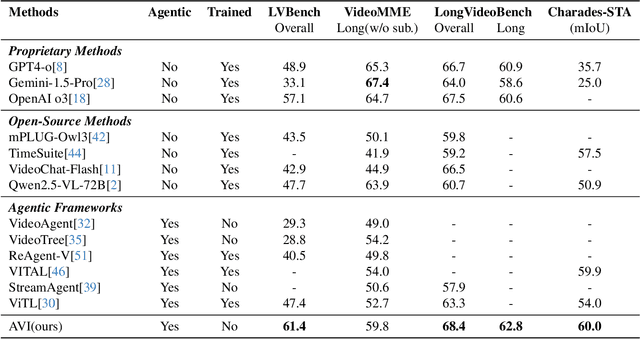
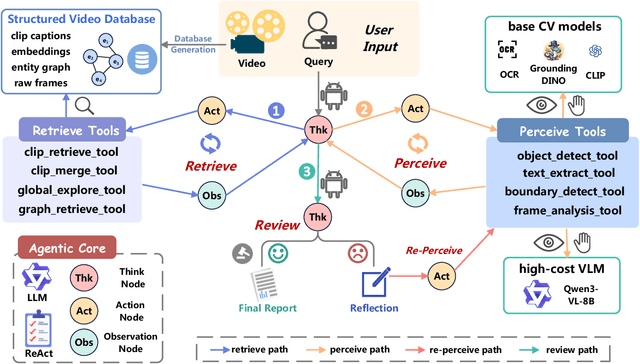
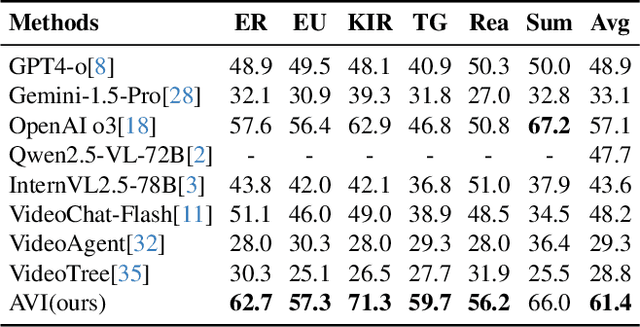
Video understanding requires not only visual recognition but also complex reasoning. While Vision-Language Models (VLMs) demonstrate impressive capabilities, they typically process videos largely in a single-pass manner with limited support for evidence revisit and iterative refinement. While recently emerging agent-based methods enable long-horizon reasoning, they either depend heavily on expensive proprietary models or require extensive agentic RL training. To overcome these limitations, we propose Agentic Video Intelligence (AVI), a flexible and training-free framework that can mirror human video comprehension through system-level design and optimization. AVI introduces three key innovations: (1) a human-inspired three-phase reasoning process (Retrieve-Perceive-Review) that ensures both sufficient global exploration and focused local analysis, (2) a structured video knowledge base organized through entity graphs, along with multi-granularity integrated tools, constituting the agent's interaction environment, and (3) an open-source model ensemble combining reasoning LLMs with lightweight base CV models and VLM, eliminating dependence on proprietary APIs or RL training. Experiments on LVBench, VideoMME-Long, LongVideoBench, and Charades-STA demonstrate that AVI achieves competitive performance while offering superior interpretability.
APVR: Hour-Level Long Video Understanding with Adaptive Pivot Visual Information Retrieval
Jun 05, 2025Current video-based multimodal large language models struggle with hour-level video understanding due to computational constraints and inefficient information extraction from extensive temporal sequences. We propose APVR (Adaptive Pivot Visual information Retrieval), a training-free framework that addresses the memory wall limitation through hierarchical visual information retrieval. APVR operates via two complementary components: Pivot Frame Retrieval employs semantic expansion and multi-modal confidence scoring to identify semantically relevant video frames, while Pivot Token Retrieval performs query-aware attention-driven token selection within the pivot frames. This dual granularity approach enables processing of hour-long videos while maintaining semantic fidelity. Experimental validation on LongVideoBench and VideoMME demonstrates significant performance improvements, establishing state-of-the-art results for not only training-free but also training-based approaches while providing plug-and-play integration capability with existing MLLM architectures.
Hybrid 3D Human Pose Estimation with Monocular Video and Sparse IMUs
Apr 27, 2024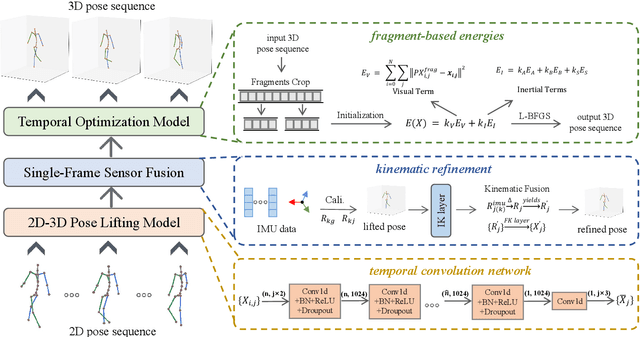
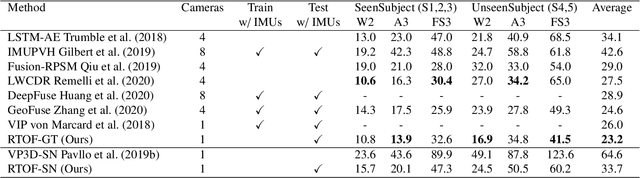
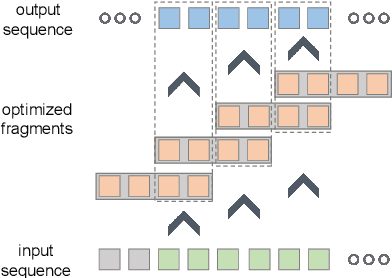
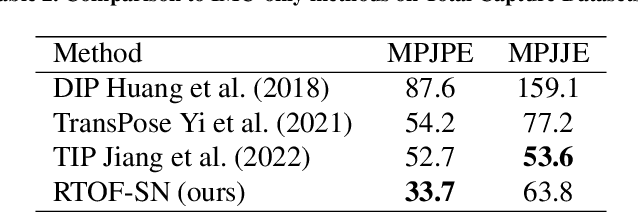
Temporal 3D human pose estimation from monocular videos is a challenging task in human-centered computer vision due to the depth ambiguity of 2D-to-3D lifting. To improve accuracy and address occlusion issues, inertial sensor has been introduced to provide complementary source of information. However, it remains challenging to integrate heterogeneous sensor data for producing physically rational 3D human poses. In this paper, we propose a novel framework, Real-time Optimization and Fusion (RTOF), to address this issue. We first incorporate sparse inertial orientations into a parametric human skeleton to refine 3D poses in kinematics. The poses are then optimized by energy functions built on both visual and inertial observations to reduce the temporal jitters. Our framework outputs smooth and biomechanically plausible human motion. Comprehensive experiments with ablation studies demonstrate its rationality and efficiency. On Total Capture dataset, the pose estimation error is significantly decreased compared to the baseline method.
RSB-Pose: Robust Short-Baseline Binocular 3D Human Pose Estimation with Occlusion Handling
Nov 24, 2023In the domain of 3D Human Pose Estimation, which finds widespread daily applications, the requirement for convenient acquisition equipment continues to grow. To satisfy this demand, we set our sights on a short-baseline binocular setting that offers both portability and a geometric measurement property that radically mitigates depth ambiguity. However, as the binocular baseline shortens, two serious challenges emerge: first, the robustness of 3D reconstruction against 2D errors deteriorates; and second, occlusion reoccurs due to the limited visual differences between two views. To address the first challenge, we propose the Stereo Co-Keypoints Estimation module to improve the view consistency of 2D keypoints and enhance the 3D robustness. In this module, the disparity is utilized to represent the correspondence of binocular 2D points and the Stereo Volume Feature is introduced to contain binocular features across different disparities. Through the regression of SVF, two-view 2D keypoints are simultaneously estimated in a collaborative way which restricts their view consistency. Furthermore, to deal with occlusions, a Pre-trained Pose Transformer module is introduced. Through this module, 3D poses are refined by perceiving pose coherence, a representation of joint correlations. This perception is injected by the Pose Transformer network and learned through a pre-training task that recovers iterative masked joints. Comprehensive experiments carried out on H36M and MHAD datasets, complemented by visualizations, validate the effectiveness of our approach in the short-baseline binocular 3D Human Pose Estimation and occlusion handling.
FusePose: IMU-Vision Sensor Fusion in Kinematic Space for Parametric Human Pose Estimation
Aug 25, 2022


There exist challenging problems in 3D human pose estimation mission, such as poor performance caused by occlusion and self-occlusion. Recently, IMU-vision sensor fusion is regarded as valuable for solving these problems. However, previous researches on the fusion of IMU and vision data, which is heterogeneous, fail to adequately utilize either IMU raw data or reliable high-level vision features. To facilitate a more efficient sensor fusion, in this work we propose a framework called \emph{FusePose} under a parametric human kinematic model. Specifically, we aggregate different information of IMU or vision data and introduce three distinctive sensor fusion approaches: NaiveFuse, KineFuse and AdaDeepFuse. NaiveFuse servers as a basic approach that only fuses simplified IMU data and estimated 3D pose in euclidean space. While in kinematic space, KineFuse is able to integrate the calibrated and aligned IMU raw data with converted 3D pose parameters. AdaDeepFuse further develops this kinematical fusion process to an adaptive and end-to-end trainable manner. Comprehensive experiments with ablation studies demonstrate the rationality and superiority of the proposed framework. The performance of 3D human pose estimation is improved compared to the baseline result. On Total Capture dataset, KineFuse surpasses previous state-of-the-art which uses IMU only for testing by 8.6\%. AdaDeepFuse surpasses state-of-the-art which uses IMU for both training and testing by 8.5\%. Moreover, we validate the generalization capability of our framework through experiments on Human3.6M dataset.
Self-Adaptive Transfer Learning for Multicenter Glaucoma Classification in Fundus Retina Images
May 07, 2021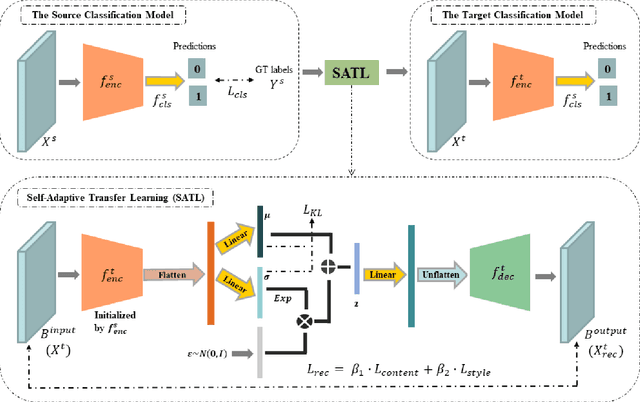
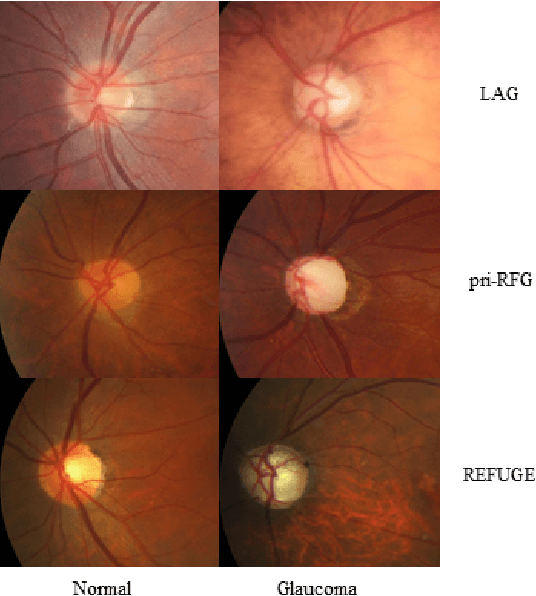
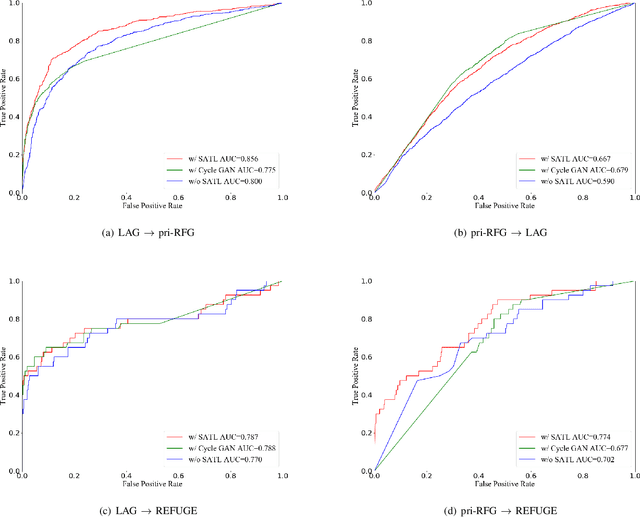
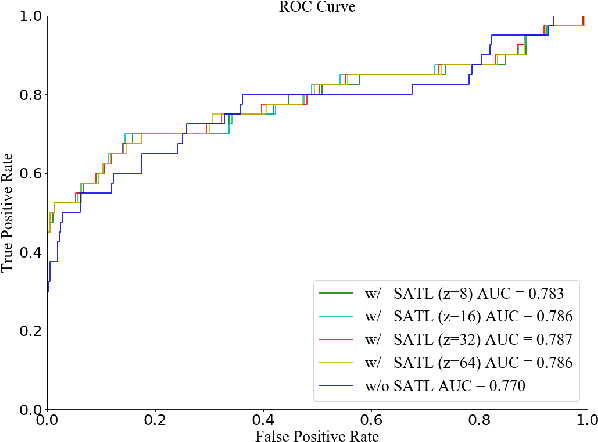
The early diagnosis and screening of glaucoma are important for patients to receive treatment in time and maintain eyesight. Nowadays, deep learning (DL) based models have been successfully used for computer-aided diagnosis (CAD) of glaucoma from retina fundus images. However, a DL model pre-trained using a dataset from one hospital center may have poor performance on a dataset from another new hospital center and therefore its applications in the real scene are limited. In this paper, we propose a self-adaptive transfer learning (SATL) strategy to fill the domain gap between multicenter datasets. Specifically, the encoder of a DL model that is pre-trained on the source domain is used to initialize the encoder of a reconstruction model. Then, the reconstruction model is trained using only unlabeled image data from the target domain, which makes the encoder in the model adapt itself to extract useful high-level features both for target domain images encoding and glaucoma classification, simultaneously. Experimental results demonstrate that the proposed SATL strategy is effective in the domain adaptation task between a private and two public glaucoma diagnosis datasets, i.e. pri-RFG, REFUGE, and LAG. Moreover, the proposed strategy is completely independent of the source domain data, which meets the real scene application and the privacy protection policy.