 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRSB-Pose: Robust Short-Baseline Binocular 3D Human Pose Estimation with Occlusion Handling
Nov 24, 2023In the domain of 3D Human Pose Estimation, which finds widespread daily applications, the requirement for convenient acquisition equipment continues to grow. To satisfy this demand, we set our sights on a short-baseline binocular setting that offers both portability and a geometric measurement property that radically mitigates depth ambiguity. However, as the binocular baseline shortens, two serious challenges emerge: first, the robustness of 3D reconstruction against 2D errors deteriorates; and second, occlusion reoccurs due to the limited visual differences between two views. To address the first challenge, we propose the Stereo Co-Keypoints Estimation module to improve the view consistency of 2D keypoints and enhance the 3D robustness. In this module, the disparity is utilized to represent the correspondence of binocular 2D points and the Stereo Volume Feature is introduced to contain binocular features across different disparities. Through the regression of SVF, two-view 2D keypoints are simultaneously estimated in a collaborative way which restricts their view consistency. Furthermore, to deal with occlusions, a Pre-trained Pose Transformer module is introduced. Through this module, 3D poses are refined by perceiving pose coherence, a representation of joint correlations. This perception is injected by the Pose Transformer network and learned through a pre-training task that recovers iterative masked joints. Comprehensive experiments carried out on H36M and MHAD datasets, complemented by visualizations, validate the effectiveness of our approach in the short-baseline binocular 3D Human Pose Estimation and occlusion handling.
View Consistency Aware Holistic Triangulation for 3D Human Pose Estimation
Feb 23, 2023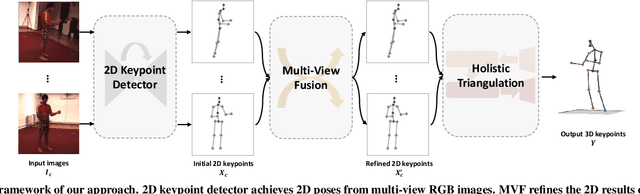
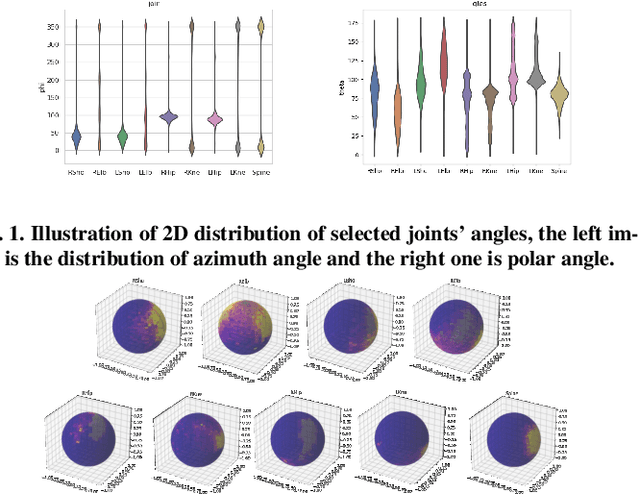
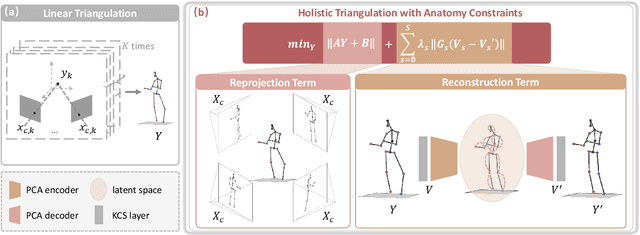

The rapid development of multi-view 3D human pose estimation (HPE) is attributed to the maturation of monocular 2D HPE and the geometry of 3D reconstruction. However, 2D detection outliers in occluded views due to neglect of view consistency, and 3D implausible poses due to lack of pose coherence, remain challenges. To solve this, we introduce a Multi-View Fusion module to refine 2D results by establishing view correlations. Then, Holistic Triangulation is proposed to infer the whole pose as an entirety, and anatomy prior is injected to maintain the pose coherence and improve the plausibility. Anatomy prior is extracted by PCA whose input is skeletal structure features, which can factor out global context and joint-by-joint relationship from abstract to concrete. Benefiting from the closed-form solution, the whole framework is trained end-to-end. Our method outperforms the state of the art in both precision and plausibility which is assessed by a new metric.