 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid 3D Human Pose Estimation with Monocular Video and Sparse IMUs
Paper and Code
Apr 27, 2024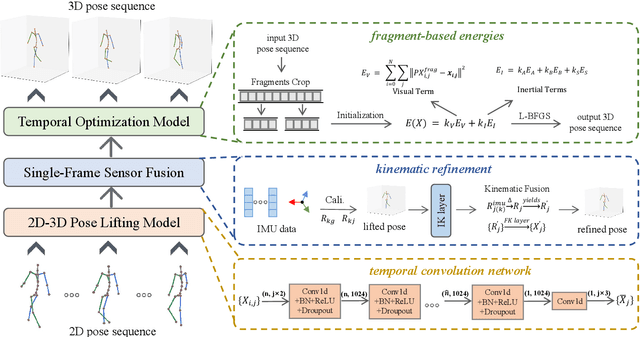
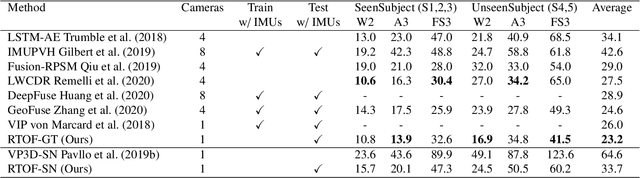
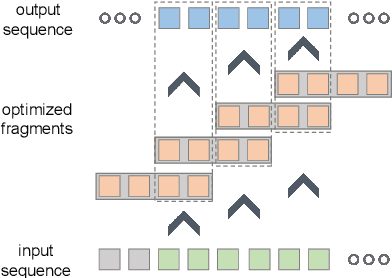
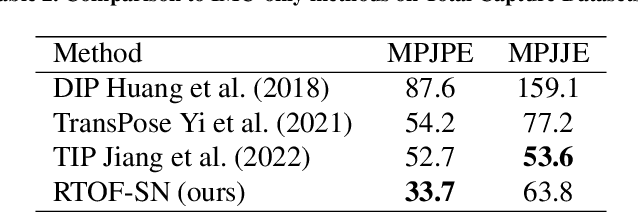
Temporal 3D human pose estimation from monocular videos is a challenging task in human-centered computer vision due to the depth ambiguity of 2D-to-3D lifting. To improve accuracy and address occlusion issues, inertial sensor has been introduced to provide complementary source of information. However, it remains challenging to integrate heterogeneous sensor data for producing physically rational 3D human poses. In this paper, we propose a novel framework, Real-time Optimization and Fusion (RTOF), to address this issue. We first incorporate sparse inertial orientations into a parametric human skeleton to refine 3D poses in kinematics. The poses are then optimized by energy functions built on both visual and inertial observations to reduce the temporal jitters. Our framework outputs smooth and biomechanically plausible human motion. Comprehensive experiments with ablation studies demonstrate its rationality and efficiency. On Total Capture dataset, the pose estimation error is significantly decreased compared to the baseline method.